
tensorflow實現線性迴歸和邏輯迴歸
阿新 • • 發佈:2018-11-16
關於線性迴歸和邏輯迴歸的原理和python實現,請左轉:邏輯迴歸、線性迴歸。
這裡就直接貼程式碼了。
線性迴歸:
# -*- coding: utf-8 -*- """ Created on Thu Aug 30 09:40:50 2018 @author: 96jie """ import tensorflow as tf import numpy as np import matplotlib.pyplot as plt #資料 num_points = 1000 vectors_set = [] for i in range(num_points): x1 = np.random.normal(0.0, 0.55) y1 = x1 * 0.1 + 0.3 + np.random.normal(0.0, 0.03) vectors_set.append([x1, y1]) x = [v[0] for v in vectors_set] y = [v[1] for v in vectors_set] #隨機生成theta theta = tf.Variable(tf.random_uniform([2],-1,1),name='theta') #計算損失 y11 = theta[0]*x+ theta[1] loss = tf.reduce_mean(tf.square(y11 - y), name='loss') #梯度下降 optimizer = tf.train.GradientDescentOptimizer(0.01) #訓練得到最小梯度 train = optimizer.minimize(loss, name='train') sess = tf.Session() init = tf.global_variables_initializer() sess.run(init) #迭代 for step in range(1000): sess.run(train) print(sess.run(theta)) plt.figure(figsize=(35,35)) plt.scatter(x,y,marker='o') plt.plot(x,sess.run(y11)) plt.xticks(fontsize=40) plt.yticks(fontsize=40) plt.xlabel('特徵X',fontsize=40) plt.ylabel('Y',fontsize=40) plt.title('結果',fontsize=40) plt.savefig("tf結果.jpg")
輸出結果:
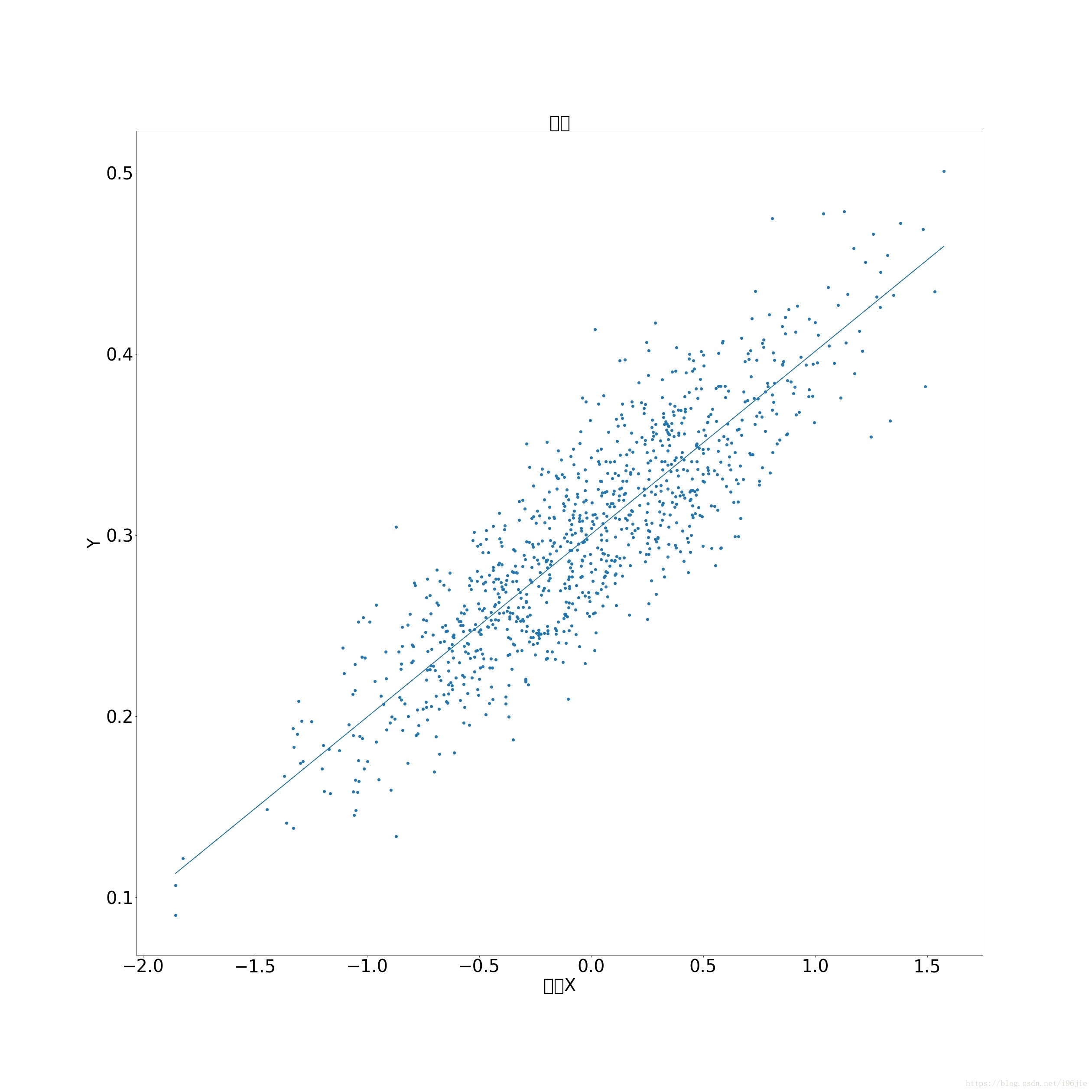
邏輯迴歸:
# -*- coding: utf-8 -*- """ Created on Thu Aug 30 11:27:55 2018 @author: asus """ import tensorflow as tf import numpy as np import matplotlib.pyplot as plt label = [] feature = np.zeros([32561,123]) f = open(r'D:\python_test\test\test\樣本\train.txt') line = f.readline() a = 0 while line: data = [] for i in line.split( ): data.append(i); for i in data[1:]: j = i.split(":") feature[a][int(j[0]) - 1] = int(j[1]) if data[0] in '+1': label.append(1) else: label.append(0) line = f.readline() a += 1 f.close n = len(label) label = np.mat(label) #構建訓練集和測試集 label1 = label[:,20001:32561] label = label[:,0:20000] feature1 = feature[20001:32561] feature = feature[0:20000] #feature1 = np.insert(feature1, 0, values=one1, axis=1) #feature = np.insert(feature, 0, values=one, axis=1) #引數 numclass = 1 Iter = 6000 inputSize = 123 #指定好x和y的大小 X = tf.placeholder(tf.float32, shape = [None, inputSize]) y = tf.placeholder(tf.float32, shape = [None, numclass]) #引數初始化 W1 = tf.Variable(tf.ones([123, 1])) B1 = tf.Variable(tf.constant(0.1), [numclass]) #損失函式 y_pred = 1 / (1 + tf.exp(-tf.matmul(X, W1) + B1)) loss = tf.reduce_mean(- y * tf.log(y_pred) - (1 - y) * tf.log(1 - y_pred)) #訓練 opt = tf.train.GradientDescentOptimizer(learning_rate = 0.05) train = opt.minimize(loss) y1 = tf.round(y_pred) #計算準確率 correct_prediction = tf.equal(y1, y) accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) init = tf.global_variables_initializer() sess = tf.Session() sess.run(init) for i in range(Iter): batchInput = feature batchLabels = label.transpose() sess.run(train, feed_dict={X: batchInput, y: batchLabels}) if i%1000 == 0: train_accuracy = accuracy.eval(session=sess, feed_dict={X: batchInput, y: batchLabels}) print ("step %d, training accuracy %g"%(i, train_accuracy)) #測試集 testAccuracy = sess.run(accuracy, feed_dict={X: feature1, y: label1.transpose()}) print ("test accuracy %g"%(testAccuracy))
結果:
step 0, training accuracy 0.23805
step 1000, training accuracy 0.82775
step 2000, training accuracy 0.8402
step 3000, training accuracy 0.84385
step 4000, training accuracy 0.84585
step 5000, training accuracy 0.84585
test accuracy 0.844984
邏輯迴歸的資料用的依舊是之前的資料。