
線性迴歸和邏輯迴歸的比較
線性迴歸
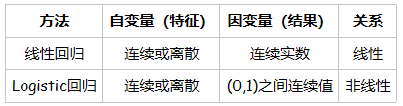
用一組變數的(特徵)的線性組合,來建立與結果之間的關係。
模型表達:
邏輯迴歸
邏輯迴歸用於分類,而不是迴歸。
線上性迴歸模型中,輸出一般是連續的, 對於每一個輸入的x,都有一個對應的輸出y。因此模型的定義域和值域都可以是無窮。
但是對於邏輯迴歸,輸入可以是連續的[-∞, +∞],但輸出一般是離散的,通常只有兩個值{0, 1}。
這兩個值可以表示對樣本的某種分類,高/低、患病/ 健康、陰性/陽性等,這就是最常見的二分類邏輯迴歸。因此,從整體上來說,通過邏輯迴歸模型,我們將在整個實數範圍上的x對映到了有限個點上,這樣就實現了對x的分類。因為每次拿過來一個x,經過邏輯迴歸分析,就可以將它歸入某一類y中。
邏輯迴歸與線性迴歸的關係
可以認為邏輯迴歸的輸入是線性迴歸的輸出,將邏輯斯蒂函式(Sigmoid曲線)作用於線性迴歸的輸出得到輸出結果。
線性迴歸y = ax + b, 其中a和b是待求引數;
邏輯迴歸p = S(ax + b), 其中a和b是待求引數, S是邏輯斯蒂函式,然後根據p與1-p的大小確定輸出的值,通常閾值取0.5,若p大於0.5則歸為1這類。
具體的:
線性函式如下:
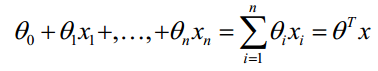
構造預測函式:
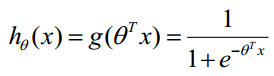
邏輯迴歸的損失函式:
邏輯迴歸採用交叉熵作為代價函式,即對數損失函式。能夠有效避免梯度消失.
對數損失函式(logarithmic loss function) 或對數似然損失函式(log-likehood loss function):
邏輯迴歸中,採用的是負對數損失函式。如果損失函式越小,表示模型越好。
極大似然估計:
極大似然原理的直觀想法是,一個隨機試驗如有若干個可能的結果A,B,C,… ,若在一次試驗中,結果A出現了,那麼可以認為實驗條件對A的出現有利,也即出現的概率P(A)較大。一般說來,事件A發生的概率與某一未知引數θ有關, θ取值不同,則事件A發生的概率也不同,當我們在一次試驗中事件A發生了,則認為此時的θ值應是一切可能取值中使P(A|θ)達到最大的那一個,極大似然估計法就是要選取這樣的θ值作為引數的估計值,使所選取的樣本在被選的總體中出現的可能性為最大。
在邏輯迴歸中目標函式均為最大化條件概率p(y|x),其中x是輸入樣本
似然:選擇引數使似然概率p(y|x,)最大,y是實際標籤
過程:目標函式→單個樣本的似然概率→所有樣本的似然概率→log變換, 將累乘變成累加→負號, 變成損失函式
選擇一組引數使得實驗結果具有最大概率。
損失函式的由來:
已知估計函式為:
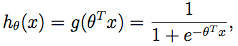
則似然概率分佈為(即輸出值為判斷為1的概率,但在輸出標籤值時實際只與0.5作比較):
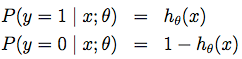
可以寫成概率一般式:
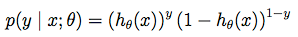
由最大似然估計原理,我們可以通過m個訓練樣本值,來估計出值,使得似然函式值(所有樣本的似然函式之積)最大
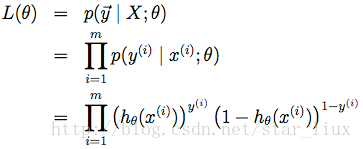
求log:
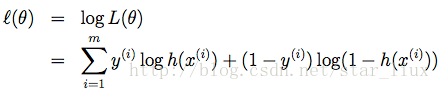
取負數,得損失函式:
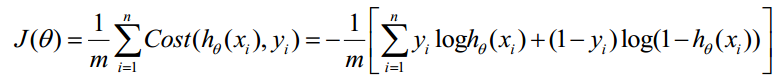
邏輯迴歸引數迭代,利用反向傳播進行計算:
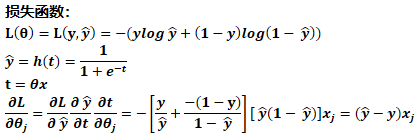
上面這個過程計算的是單個樣本對wj的梯度更新。
為什麼邏輯迴歸採用似然函式,而不是平方損失函式?
可以從兩個角度理解。
交叉熵損失函式的好處是可以克服方差代價函式更新權重過慢的問題(針對啟用函式是sigmoid的情況)。
原因是其梯度裡面不在包含對sigmoid函式的導數:
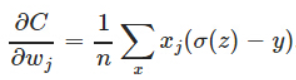
而如果使用的是平方損失函式加sigmoid函式,則計算梯度時:
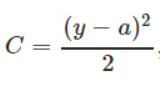
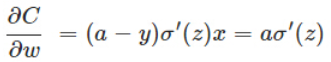
會包含sigmoid的導數(sigmoid的導數值始終小於1),使梯度下降變慢。

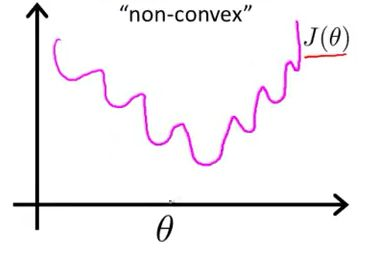
圖1 最小二乘作為邏輯迴歸模型的損失函式(非凸),theta為待優化引數
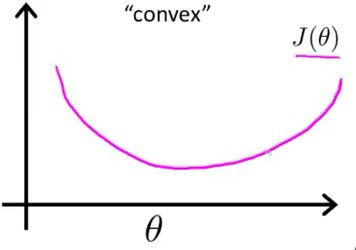
圖2 最大似然作為邏輯迴歸模型的損失函式,theta為待優化引數
邏輯迴歸為什麼使用sigmoid函式
也可以從兩點來進行理解
Sigmoid 函式自身的性質
因為這是一個最簡單的,可導的,0-1階躍函式
sigmoid 函式連續,單調遞增
sigmiod 函式關於(0,0.5) 中心對稱
對sigmoid函式求導簡單
邏輯迴歸函式的定義

因此, 邏輯迴歸返回的概率是指判別為1類的概率.
邏輯迴歸和SVM的異同點
相同點:
第一,LR和SVM都是分類演算法。
第二,如果不考慮核函式,LR和SVM都是線性分類演算法,也就是說他們的分類決策面都是線性的。
第三,LR和SVM都是監督學習演算法。
第四,LR和SVM都是判別模型。
判別模型會生成一個表示P(Y|X)的判別函式(或預測模型),而生成模型先計算聯合概率p(Y,X)然後通過貝葉斯公式轉化為條件概率。簡單來說,在計算判別模型時,不會計算聯合概率,而在計算生成模型時,必須先計算聯合概率。
不同點:
第一,本質上是其loss function不同
邏輯迴歸的損失函式是交叉熵函式:
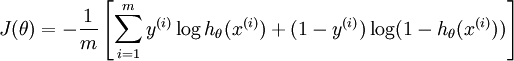
SVM的損失函式:
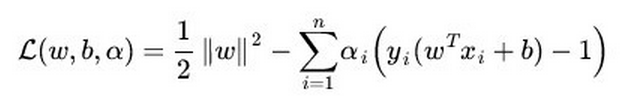
邏輯迴歸方法基於概率理論,假設樣本為1的概率可以用sigmoid函式來表示,然後通過極大似然估計的方法估計出引數的值;
支援向量機基於幾何間隔最大化原理,認為存在最大幾何間隔的分類面為最優分類面;
第二,支援向量機只考慮區域性的邊界線附近的點,而邏輯迴歸考慮全域性(遠離的點對邊界線的確定也起作用)。
第三,在解決非線性問題時,支援向量機採用核函式的機制,而LR通常不採用核函式的方法。
這個問題理解起來非常簡單。分類模型的結果就是計算決策面,模型訓練的過程就是決策面的計算過程。通過上面的第二點不同點可以瞭解,在計算決策面時,SVM演算法裡只有少數幾個代表支援向量的樣本參與了計算,也就是隻有少數幾個樣本需要參與核計算(即kernal machine解的係數是稀疏的)。然而,LR演算法裡,每個樣本點都必須參與決策面的計算過程,也就是說,假設我們在LR裡也運用核函式的原理,那麼每個樣本點都必須參與核計算,這帶來的計算複雜度是相當高的。所以,在具體應用時,LR很少運用核函式機制。
第四,SVM的損失函式就自帶正則
參考:
Poll的部落格:www.cnblogs.com/maybe2030/p/5494931.html