
Spark基本架構
Spark基本架構圖如下:
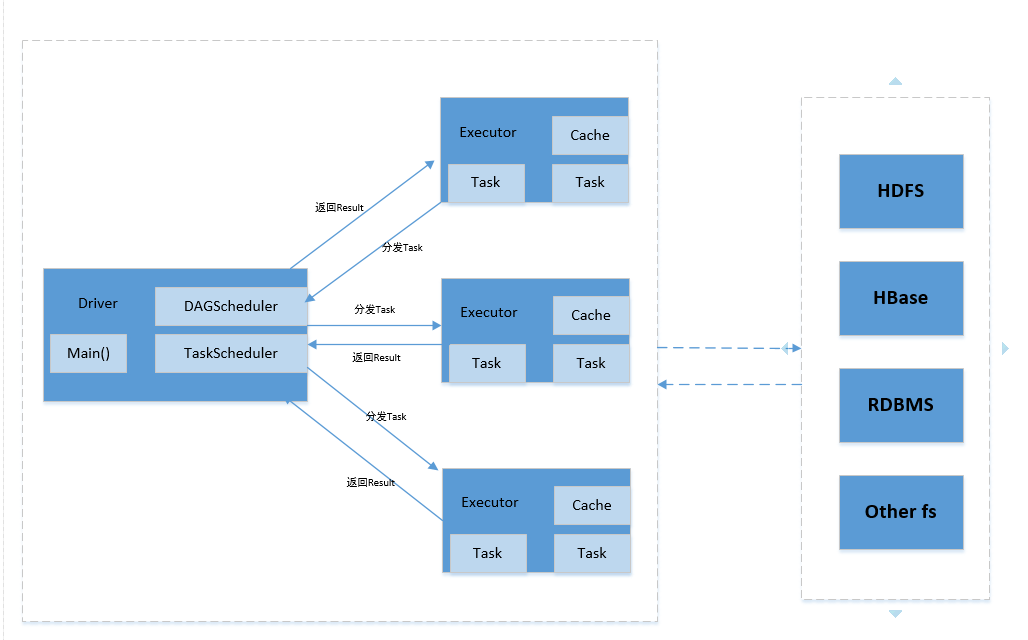
Client:客戶端程序,負責提交作業。
Driver:一個Spark作業有一個spark context,一個Spark Context對應一個Driver程序,作業的main函式執行在Driver中。Driver主要負責Spark作業的解析,以及通過DAGSchduler劃分stage,將Stage轉化成TaskSet提交給TaskScheduler任務排程器,進而排程Task到Executor上執行。
Executor:負責執行Driver分發的Task任務。叢集中一個節點可以啟動多個Executor,每個Executor可以執行多個Task任務。
Cache:Spark提供了對RDD不同級別的快取策略,分別可以快取到記憶體、磁碟、外部分散式記憶體儲存系統如Tachyon等。
Applicatio:提交的一個作業就是一個Appliation。一個Application只有一個Spark Context。
Job:RDD執行一次Action操作應付生成一個Job。
Task:Spark執行的基本單位,負責 處理RDD的計算邏輯。
Stage:DAGScheduler將Job劃分為多個Stage,Stage的劃分界限為Shuffle的產生,Suffle標誌著上一個Stage的結束和下一個Stage的開始。
TaskSet:劃分的Stage會轉換成一組相關聯的任務集。
RDD(Resilient Distributed Dataset):彈性分散式資料集,可以理解為一種只讀的分散式多分割槽的陣列,Spark計算操作都是基於RDD進行的,下面會有詳細介紹。
DAG(Directed Acyclic Graph):有向無環圖。Spark實現了DAG的計算模型,DAG計算模型是指將一個計算任務按照計算規則分解為若干子任務,這些子任務之間根據邏輯關係構建成有向無環圖。