
PageRank演算法初探
1. PageRank的由來和發展歷史
0x1:源自搜尋引擎的需求
Google早已成為全球最成功的網際網路搜尋引擎,在Google出現之前,曾出現過許多通用或專業領域搜尋引擎。Google最終能擊敗所有競爭對手,很大程度上是因為它解決了困擾前輩們的最大難題:對搜尋結果按重要性排序。而解決這個問題的演算法就是PageRank。毫不誇張的說,是PageRank演算法成就了Google今天的地位。
1. 搜尋引擎的核心框架
從本質上說,搜尋引擎是一個資料檢索系統,搜尋引擎擁有一個資料庫(具體到這裡就是網際網路頁面),使用者提交一個檢索條件(例如關鍵詞),搜尋引擎返回符合查詢條件的資料列表。
理論上檢索條件可以非常複雜,為了簡單起見,我們不妨設檢索條件是一至多個以空格分隔的詞,而其表達的語義是同時含有這些詞的資料(等價於布林代數的邏輯與)。例如,提交“littlehann 部落格”,意思就是“給我既含有‘littlehann’又含有‘部落格’詞語的頁面”,以下是Google對這條關鍵詞的搜尋結果:

當然,實際上現在的搜尋引擎都是有分詞機制的,例如如果以“littlehann的部落格”為關鍵詞,搜尋引擎會自動將其分解為“littlehann 的 部落格”三個詞,而“的”作為停止詞(Stop Word)會被過濾掉。
建立一個搜尋引擎的核心問題就是以下幾個:
1. 建立資料庫; 2. 建立一種資料結構,根據關鍵詞找到含有這個詞的頁面; 3. 將結果按照重要程度排序後呈現給使用者;
1)建立資料庫
這個問題一般是通過一種叫爬蟲(Spider)的特殊程式實現的(專業領域搜尋引擎例如某個學術會議的論文檢索系統可能直接從資料庫建立資料庫)。
簡單來說,爬蟲就是從一個頁面出發(例如新浪首頁),通過HTTP協議通訊獲取這個頁面的所有內容,把這個頁面url和內容記錄下來(記錄到資料庫),然後分析頁面中的連結,再去分別獲取這些連結鏈向頁面的內容,記錄到資料庫後再分析這個頁面的連結。
上述過程不斷重複,就可以將整個網際網路的頁面全部獲取下來(當然這是理想情況,要求整個Web是一個強連通(Strongly Connected),並且所有頁面的robots協議允許爬蟲抓取頁面,為了簡單,我們仍然假設Web是一個強連通圖,且不考慮robots協議)。
抽象來看,可以將資料庫看做一個巨大的key-value結構,key是頁面url,value是頁面內容。
2)建立一種資料結構,根據關鍵詞找到含有這個詞的頁面
這個問題是通過一種叫倒排索引(inverted index)的資料結構實現的。
抽象來說倒排索引也是一組key-value結構,key是關鍵詞,value是一個頁面編號集合(假設資料庫中每個頁面有唯一編號),表示這些頁面含有這個關鍵詞。
搜尋引擎獲取“littlehann 部落格”查詢條件,將其分為“littlehann”和“部落格”兩個詞。
然後分別從倒排索引中找到“littlehann”所對應的集合,假設是{1, 3, 6, 8, 11, 15};
“部落格”對應的集合是{1, 6, 10, 11, 12, 17, 20, 22},
將兩個集合做交運算(intersection),結果是{1, 6, 11}。即尋找同時出現了這2個詞的頁面。
最後,從資料庫中找出1、6、11對應的頁面返回給使用者就可以了。
3)將結果按照重要程度排序後呈現給使用者
上面兩個問題解決後,我們很自然會想到,Web頁面數量非常巨大,所以一個檢索的結果條目數量也非常多,例如上面“littlehann 部落格”的檢索返回了上萬條條結果。使用者不可能從如此眾多的結果中一一查詢對自己有用的資訊。
所以,一個好的搜尋引擎必須想辦法將“質量”較高的頁面排在前面。
其實直觀上也可以感覺出,在使用搜索引擎時,我們並不太關心頁面是否夠全(上百萬的結果,全不全有什麼區別?而且實際上搜索引擎都是取top,並不會真的返回全部結果。),而很關心前一兩頁是否都是質量較高的頁面,是否能滿足我們的實際需求。
因此,對搜尋結果按重要性合理的排序就成為搜尋引擎的最大核心問題。
3.1)早期搜尋引擎的做法
1. 不評價 早期的搜尋引擎直接按照某自然順序(例如時間順序或編號順序)返回結果。這在結果集比較少的情況下還說得過去,但是一旦結果集變大,使用者叫苦不迭,試想讓你從幾萬條質量參差不齊的頁面中尋找需要的內容,簡直就是一場災難,這也註定這種方法不可能用於現代的通用搜索引擎。 2. 基於檢索詞的評價 後來,一些搜尋引擎引入了基於檢索關鍵詞去評價搜尋結構重要性的方法,實際上,這類方法如TF-IDF演算法在現代搜尋引擎中仍在使用。
3.2)早期搜尋引擎遇到的問題 - Term Spam
早期一些搜尋引擎基於類似的演算法評價網頁重要性的。這種評價演算法看似依據充分、實現直觀簡單,但卻非常容易受到一種叫“Term Spam”的攻擊。
其實從搜尋引擎出現的那天起,spammer和搜尋引擎反作弊的鬥法就沒有停止過。Spammer是這樣一群人——試圖通過搜尋引擎演算法的漏洞來提高目標頁面(通常是一些廣告頁面、博彩或垃圾頁面)的重要性,使目標頁面在搜尋結果中排名靠前。
現在假設Google單純使用關鍵詞佔比評價頁面重要性,而我想讓我的部落格在搜尋結果中排名更靠前(最好排第一)。
那麼我可以這麼做:在頁面中加入一個隱藏的html元素(例如一個div),然後其內容是“littlehann”重複一萬次。這樣,搜尋引擎在計算“littlehann 部落格”的搜尋結果時,我的部落格關鍵詞佔比就會非常大(TF-IDF的公式決定了),從而做到排名靠前的效果。
更進一步,我甚至可以干擾別的關鍵詞搜尋結果,例如我知道現在歐洲盃很火熱,我就在我部落格的隱藏div里加一萬個“歐洲盃”,當有使用者搜尋歐洲盃時,我的部落格就能出現在搜尋結果較靠前的位置。這種行為就叫做“Term Spam”。
早期搜尋引擎深受這種作弊方法的困擾,加之基於關鍵詞的評價演算法本身也不甚合理,因此經常是搜出一堆質量低下的結果,使用者體驗大大打了折扣。而Google正是在這種背景下,提出了PageRank演算法,並申請了專利保護。此舉充分保護了當時相對弱小Google,也使得Google一舉成為全球首屈一指的搜尋引擎。
Relevant Link:
http://blog.codinglabs.org/articles/intro-to-pagerank.html
2. PageRank演算法描述
0x1:PageRank的思想
1. 每一個一個網頁本身具有一定的重要性,它的重要性是通過其他網路的連結到該網頁來評價的。其他網頁連結到該網頁可以形象地理解為給這個網頁投票。 2. 一個網頁的連結會把該網頁的重要性傳遞到連結的網頁中,而一個網頁的重要性又必須通過連結它的網頁來確定。這是一個互相依賴的遞迴過程。 3. 公平起見,一個網頁X若連結了m個網頁,那麼這m個網頁的每個網頁接收到的來自網頁X的重要性是PR(X)/m。
PageRank演算法的目標就是計算每一個網頁的PageRank值,然後根據這個值的大小對網頁的重要性進行排序。
它的思想是模擬一個悠閒的上網者,上網者首先隨機選擇一個網頁開啟,然後在這個網頁上呆了幾分鐘後,跳轉到該網頁所指向的連結,這樣無所事事、漫無目的地在網頁上跳來跳去,PageRank就是估計這個悠閒的上網者分佈在各個網頁上的概率。
0x2:從感性層面認識一個簡單pagerank模型
在這個小節我們以一個悠閒上網者的視角來討論PageRank的演算法過程,以便建立起一個感性的概念性認識,方便我們記憶和攔截核心概念。
網際網路中的WWW網頁可以看出是一個有向圖,其中網頁是結點。如果網頁A有連結到網頁B,則存在一條有向邊A->B。下面是一個簡單的示例:

這個例子中只有四個網頁。分別是A、B、C、D。這4個網頁分別擁有各自不同的“跳轉選擇選項”,悠閒上網者在每個網頁中,可以往哪一個網頁去進行下一跳,是由這個選項規定的。
如果當前在A網頁,那麼悠閒的上網者將會各以1/3的概率跳轉到B、C、D,這裡的3表示A有3條出鏈。如果一個網頁有k條出鏈,那麼跳轉任意一個出鏈上的概率是1/k;
同理D到B、C的概率各為1/2;
而B到C的概率為0。
一般用轉移矩陣表示上網者的跳轉概率(注意,這個跳轉概率是在建立網路圖的時候就確定好的,後面不會再改變)。
如果用n表示網頁的數目,則轉移矩陣M是一個n*n的方陣(每一個網頁都可能轉移到任意的網頁,包括它自己)。
如果網頁j 有 k 個出鏈,那麼對每一個出鏈指向的網頁i,有M[i][j]=1/k(權重是等分的),而其他網頁的M[i][j]=0(沒有出鏈就意味著不給那個網頁投票);
上面示例圖對應的轉移矩陣的轉置如下(注意,下面的矩陣是列向量的形式):

好了,現在我們已經得到了所有網頁的轉移矩陣,也即確定了所有網頁各自的“跳轉選擇選項”。接下來要讓我們的悠閒上網者開始在網頁上不斷遊走,希望這個上網者通過不斷地遊走,給出一個最終的評估,對A、B、C、D這4個網頁的重要性權重給出一個數值結果。
根據最大熵原則,悠閒上網者對這4個網頁的權重沒有任何先驗知識,所以假設每一個網頁的概率都是相等的,即1/n。
於是初試的概率分佈就是一個所有值都為1/n的n維列向量V0,用V0去右乘轉移矩陣M,就得到了第一步之後上網者的概率分佈向量MV0。n x n)* (n x 1)依然得到一個n x 1的矩陣。

M的第一行乘以 V0,表示累加所有網頁到網頁A的概率即得到9/24;
M的第二行乘以 V0,表示累加所有網頁到網頁B的概率即得到9/24;
M的第三行乘以 V0,表示累加所有網頁到網頁C的概率即得到9/24;
M的第四行乘以 V0,表示累加所有網頁到網頁D的概率即得到9/24;
這一輪結束後,上網者對各個網頁的權重值得到了一次調整,從思想上很類似EM優化過程。
可以把矩陣MM和向量rr相乘當做MM的列以向量rr為權重進行線性組合,矩陣MM同一列的不同行代表該節點向其他節點的分發連線。
得到了V1後,再用V1去右乘M得到V2,一直下去,最終V會收斂,
即Vn=M * V(n-1)。

不斷的迭代,最終V = [3/9,2/9,2/9,2/9]'
這個[3/9,2/9,2/9,2/9]'就代表了上網者對這4個網頁權重的最終評價。顯然,這個權重評價是根據 M矩陣 的擬合而來的。
直觀上可以這麼理解:這個悠閒上網者看到轉移矩陣M,他在想,這個M矩陣就代表了當前整個網路的拓樸結構,那麼這個拓樸結構背後一定隱含了某種規律,這個規律就是每個網頁的權重。這個規則“支撐”著網路成為今天我看到的樣本。那我要努力去遊走,讓我的評價無限接近網路背後的真實規律。恩,加油,我一定行的!
筆者思考:這種漸進收斂的思路,本質上體現了極大似然估計的思想,即從結果反推最有可能產生這個結果的模型引數。筆者建議讀者朋友翻出極大似然估計的書籍參照著學習,筆者也有一篇blog討論了極大似然估計的話題。
0x3:從馬爾科夫過程的視角看PageRank
現在我們從馬爾科夫過程的角度來看PageRank的訓練和收斂過程。關於markvo的討論,可以參閱另一篇blog。
1. 馬爾科夫假設
假設我們在上網的時候瀏覽頁面並選擇下一個頁面,這個過程與過去瀏覽過哪些頁面無關,而僅依賴於當前所在的頁面。這個假設前提符合馬爾科夫的有限狀態依賴假設。
我們可以把PageRank的這一選擇過程可以認為是一個有限狀態、離散時間的隨機過程,其狀態轉移規律可用Markov鏈描述。
2. 概率轉移矩陣
在PageRank演算法中,網頁拓樸間互相連結的鄰接矩陣,就對應了概率轉移矩陣。
- 網際網路是一個有向圖
- 每一個網頁是圖的一個頂點
- 網頁間的每一個超連結是圖的一個有向邊
- 用鄰接矩陣G來表示有向圖, 即,若網頁j 到網頁i 有超連結, 則gij=1, 否則為gij=0
可以想象,在一個龐大的網路中,鄰接矩陣是一個十分龐大有相當稀疏的方陣(用黑色代表1, 用白色代表0)。例如下圖:

矩陣中的的空行代表了沒有被其他網頁連結過,可能代表是新網頁(例如新的新聞html頁面),或者是異常的惡意url。
定義矩陣G的“列和”與“行和”,在PageRank場景下,概率轉移矩陣的“行和”和“列和”是有明確含義的。

1. cj(列和) 是頁面j 的匯出連結數目。也就是該頁面給其他頁面的“投票”。當然,在PageRank中,列和是有明確約束的,即一個頁面能給其他頁面投票的總權重和是1,不能超過1。 2. ri(行和) 是頁面 i 的匯入連結數目。也就是該頁面收到的權重投票。
3. 權重向量計算過程 - 隱狀態序列(網頁權重向量)收斂過程
在討論馬爾科夫收斂問題前,我們要對PageRank的迭代公式進行一個明確定義。但是,在討論PageRank公式之前還要先討論兩個在實際中會遇到的問題:
1)Spider Traps問題
,即Spider Traps問題(自迴圈節點),因為這個問題的存在,導致PageRank的迭代公式需要作出一些變形。
可以預見,如果把真實的Web組織成轉移矩陣,那麼這將是一個極為稀疏的矩陣。
從矩陣論知識可以推斷,極度稀疏的轉移矩陣迭代相乘可能會使得向量v變得非常不平滑,即一些節點擁有很大的rank,而大多數節點rank值接近0。
而一種叫做Spider Traps節點的存在加劇了這種不平滑。例如下圖:

D有外鏈所以不是Dead Ends,但是它只鏈向自己(注意鏈向自己也算外鏈,當然同時也是個內鏈)。這種節點叫做Spider Trap。
如果對這個圖進行計算,會發現D的rank越來越大趨近於1(因為每輪迭代它都只給自己投票),而其它節點rank值幾乎歸零。
2)Dead Ends問題
所謂Dead Ends,就是這樣一類節點:它們不存在外鏈。看下面的圖:

注意這裡D頁面不存在外鏈,是一個Dead End。
在這個圖中,M第四列(D對應的那列)將全為0。在沒有Dead Ends的情況下,每次迭代後向量v各項的和始終保持為1,而有了Dead Ends,迭代結果將最終歸零。
3)隨機轉移概率(心靈轉移)
為了克服這種由於矩陣稀疏性、Spider Traps、以及Dead Ends帶來的問題,需要對PageRank計算方法進行一個平滑處理,具體做法是加入“隨機轉移概率”。
所謂隨機轉移,就是我們認為在任何一個頁面瀏覽的使用者都有可能以一個極小的概率瞬間轉移到另外一個隨機頁面。
當然,這兩個頁面可能不存在超連結,隨機轉移只是為了演算法需要而強加的一種純數學意義的概率數字。
筆者思考:大家仔細體會這種做法的思想,它本質上就是一個結構化風險最小化思想。和在機器學習演算法中加入正則項、懲罰項、剪枝;在深度學習中 Dropout 的核心思想都是一致的。我們可以這麼來理解,加入了隨機轉移概率後,每個節點向其他節點轉移的概率是不是更加傾向於“均等化”了,這就等於削弱了原本的網路結構的先驗特性。
4)PageRank序列迭代公式
加入隨機概率轉移後,向量迭代公式變為:

其中 β 往往被設定為一個比較小的引數(0.2或更小),它的作用就是在原本模型基礎上加入懲罰因子;
e為N維單位向量,加入e的原因是這個公式的前半部分是向量,因此必須將β/N轉為向量才能相加。
經過隨機轉移概率的修正後,整個計算就變得平滑,因為每次迭代的結果除了依賴轉移矩陣外,還依賴一個小概率的隨機概率轉移。
以該圖為例:
原始轉移矩陣M為:

設β為0.2,則計算公式為:

如果按這個公式迭代算下去,會發現Spider Traps的效應被抑制了,從而每個頁面都擁有一個合理的pagerank。
同時,即使是出現了Dead Ends,因為隨機概率矩陣的存在,實際的M 也因此不存在為0的行了。
問題得到了完美的解決。
0x4:PR值計算方法
1. 冪迭代法
首先給每個頁面賦予隨機的PR值,然後通過![]() 不斷地迭代PR值。當滿足下面的不等式後迭代結束,獲得所有頁面的PR值:
不斷地迭代PR值。當滿足下面的不等式後迭代結束,獲得所有頁面的PR值:
用python實現示例程式碼如下:
# -*- coding: utf-8 -*- from pygraph.classes.digraph import digraph class PRIterator: __doc__ = '''計算一張圖中的PR值''' def __init__(self, dg): self.damping_factor = 0.85 # 阻尼係數,即α self.max_iterations = 100 # 最大迭代次數 self.min_delta = 0.00001 # 確定迭代是否結束的引數,即ϵ self.graph = dg def page_rank(self): # 先將圖中沒有出鏈的節點改為對所有節點都有出鏈 for node in self.graph.nodes(): if len(self.graph.neighbors(node)) == 0: for node2 in self.graph.nodes(): digraph.add_edge(self.graph, (node, node2)) nodes = self.graph.nodes() graph_size = len(nodes) if graph_size == 0: return {} # 給每個節點賦予初始的PR值,第一輪的PR值是均等的,即 1/N page_rank = dict.fromkeys(nodes, 1.0 / graph_size) # 公式中的(1−α)/N部分 damping_value = (1.0 - self.damping_factor) / graph_size flag = False for i in range(self.max_iterations): change = 0 for node in nodes: rank = 0 # 遍歷所有“入射”的頁面 for incident_page in self.graph.incidents(node): # "入射"頁面的權重根據其出鏈個數均分,然後傳遞給當前頁面 rank += self.damping_factor * (page_rank[incident_page] / len(self.graph.neighbors(incident_page))) # 增加隨機概率轉移矩陣的部分 rank += damping_value change += abs(page_rank[node] - rank) # 絕對值 page_rank[node] = rank print("This is NO.%s iteration" % (i + 1)) print(page_rank) if change < self.min_delta: flag = True break if flag: print("finished in %s iterations!" % node) else: print("finished out of 100 iterations!") return page_rank if __name__ == '__main__': # 建立一個網路拓樸圖 dg = digraph() dg.add_nodes(["A", "B", "C", "D", "E"]) dg.add_edge(("A", "B")) dg.add_edge(("A", "C")) dg.add_edge(("A", "D")) dg.add_edge(("B", "D")) dg.add_edge(("C", "E")) dg.add_edge(("D", "E")) dg.add_edge(("B", "E")) dg.add_edge(("E", "A")) # PRrank迭代計算 pr = PRIterator(dg) page_ranks = pr.page_rank() print("The final page rank is\n", page_ranks)

從結果上可以看出兩個比較明顯的規律:
1. E節點的權重是最高的,因為E的入鏈最多,這很顯然; 2. A節點的權重次之,也很高,因為高權重E節點存在向A節點的入鏈;
2. 特徵值法
我們知道,當Markov鏈收斂時,必有:
![]()
3. 代數法
類似地,當提到Markov鏈收斂時,必有:

Relevant Link:
http://www.cnblogs.com/fengfenggirl/p/pagerank-introduction.html https://www.letiantian.me/2014-06-10-pagerank/ https://wizardforcel.gitbooks.io/dm-algo-top10/content/pagerank.html https://blog.csdn.net/cannel_2020/article/details/7672042 https://blog.csdn.net/Young_Gy/article/details/70169649?utm_source=blogxgwz2 http://blog.codinglabs.org/articles/intro-to-pagerank.html https://blog.csdn.net/golden1314521/article/details/41597605 https://blog.csdn.net/rubinorth/article/details/52215036 https://blog.csdn.net/leadai/article/details/81230557
4. PageRank的數學原理
0x1:討論該問題涉及到的幾個數學概念
1. Perron - Frobenius定理
設 A = (aij) 是一個 n x n 的正矩陣:![]() ,該矩陣有以下幾個性質:
,該矩陣有以下幾個性質:
1. A 存在一個正實數的特徵值![]() ,叫做 Perron根 或者 Perron - Frobenius特徵值,使得其他所有特徵值(包括複數特徵值)的規模都比它小;
,叫做 Perron根 或者 Perron - Frobenius特徵值,使得其他所有特徵值(包括複數特徵值)的規模都比它小;
2. ![]() 只對應一個特徵向量 v;
只對應一個特徵向量 v;
3. ![]() 所對應的特徵向量 v 的所有元素都為正實數;
所對應的特徵向量 v 的所有元素都為正實數;
4. ![]() 以外的其他特徵值所對應的特徵向量的元素至少有一個為負數或者複數;
以外的其他特徵值所對應的特徵向量的元素至少有一個為負數或者複數;
5. ![]()
6. ![]()
2. 正矩陣(Positive matrix)
每個矩陣元都大於0的矩陣稱之為正矩陣;
每個矩陣元都大於等於0的矩陣是非負矩陣(Nonnegative matrix)
3. 素陣(Primitive matrix)
素陣是指自身的某個次冪為正矩陣(Positive matrix)的矩陣。設 A 為一個 n x n 的方陣,如果存在正整數 k 使得矩陣滿足:
![]()
那麼,稱矩陣 A 為素矩陣。
4. 隨機矩陣(stochastic matrix)
隨機矩陣又叫做概率矩陣(probability matrix)、轉移矩陣(transition matrix)、馬爾科夫矩陣(markov matrix)等。
隨機矩陣通常表示左隨機矩陣(left stochastic matrix)。
如果方陣![]() 為左隨機矩陣,則其滿足以下條件:
為左隨機矩陣,則其滿足以下條件:

即“列和”為1
5. 不可約矩陣(irreducible matrix)
方陣A 是不可約的,當且僅當與矩陣A 對應的有向圖是強連通的。
有向圖 G = (V,E) 是強連通的當且僅當對每一節點對![]() ,存在 u 到 v 的路徑。也就是說,如果某狀態轉移矩陣不可約,則其每個狀態都可來自任意的其他狀態。
,存在 u 到 v 的路徑。也就是說,如果某狀態轉移矩陣不可約,則其每個狀態都可來自任意的其他狀態。
6. 週期圖(Periodicity)
說狀態 i 是週期的,並且具有周期 k > 1,是指存在一個最小的正整數 k,使得從某狀態 i 出發又回到狀態 i 的所有路徑的長度都是 k 的整數倍。
如果一個狀態不是週期的或者 k = 1,那它就是非週期的。
如果一個馬爾柯夫鏈的所有狀態都是非週期的,那麼就說這個馬爾柯夫鏈是非週期的。
下圖所示,從狀態1 出發回到狀態1 的路徑只有一條,即 1-2-3-1,需要的轉移次數是3,所以這是一個週期為3 的馬爾柯夫鏈。
0x2:權重向量收斂性問題
1. 權重向量數學公式化表示
我們從排序聲望(rank prestige)的角度進一步闡述PageRank的思想:
1. 從一個網頁指向另一個網頁的超連結是PageRank值的隱含式傳遞,網頁的PageRank值是由指向它的所有的網頁所傳遞過來的PageRank值總和決定的。這樣,網頁 i 的入鏈越多,它的PageRank值就越高,它得到的聲望就越高。 2. 一個網頁指向多個其他網頁,那麼它傳遞的聲望值就會被它所指向的多個網頁分享。也就是說,即使網頁 i 被一個PageRank值很高的網頁 j 所指向,但是如果網頁 i 的出鏈非常多,網頁 i 從網頁 j 得到的聲望值可能因此被稀釋地也很小
我們可以把web網路抽象成一個有向圖 G = (V,E),其中 V 是圖的節點集合(一個節點對應一個網頁),E 是圖的有向邊集合(有向邊對應超連結)。
設web上的網頁總數為 n,即 n = | V |。上述四項可以形式化為:
 ,i = 1,2....,n
,i = 1,2....,n
其中 P(i) 表示網頁 i 的PageRank值,![]() 是網頁 j 出鏈的數量,(j,i) 表示存在網頁 j 指向網頁 i 的超連結。
是網頁 j 出鏈的數量,(j,i) 表示存在網頁 j 指向網頁 i 的超連結。
從數學的觀點看就是存在一個包含 n 個未知量的線性方程組,每個網頁的權重都是一個未知量。
可以用一個矩陣來表示,首先作一個符號的約定,用列向量 P 表示 n 個網頁的PageRank值,如下:
![]()
再用矩陣 A 表示有向圖的鄰接矩陣,並按如下規則未每條有向邊賦值:

例如如下鄰接矩陣 A:

我們可以得到如下方程組:
![]()
我們的任務是在已知矩陣 A 的條件下,求解向量 P。這個 P 是迴圈定義的,所以採用冪迭代方法求解 P。
我們定義給定初值 ![]() ,定義
,定義![]() 是經過第 n 次迭代得到的 P 值,可以形式化如下:
是經過第 n 次迭代得到的 P 值,可以形式化如下:
![]()
滿足上述方程組的解![]() 就是
就是![]() 。
。
當然,也可以用馬爾柯夫鏈(markov chain)進行建模,這時![]() 就可以看成是markov chain的一個狀態(state),A 可以表示狀態轉移矩陣(state transition matrix),這樣就可以轉換成馬爾柯夫鏈的遍歷性和極限分佈問題。
就可以看成是markov chain的一個狀態(state),A 可以表示狀態轉移矩陣(state transition matrix),這樣就可以轉換成馬爾柯夫鏈的遍歷性和極限分佈問題。
2. 收斂性的充要條件
![]() 是否收斂,取決於下面幾個條件是否成立:
是否收斂,取決於下面幾個條件是否成立:
1. ![]() 是否存在?
是否存在?
2. 如果極限存在,它是否與![]() 的選取有關?即收斂性是否初始值敏感?
的選取有關?即收斂性是否初始值敏感?
3. 如果極限存在,並且與![]() 的選取無關,它作為網頁排序的依據是否真的合理?
的選取無關,它作為網頁排序的依據是否真的合理?
如果要滿足前2個問題, 轉移矩陣A 必須滿足以下3個條件:
1. 轉移矩陣A 必須是隨機矩陣; 隨機矩陣要求矩陣的每一個行和都為1,即不能出現dead end節點(不存在任何出鏈的節點),如果web網路拓樸中存在dead end,則原始隨機矩陣的條件不能成立。 但是不要忘了,因為隨機概率轉移矩陣(心靈矩陣)的存在,實際的M不存在為0的行,所以這第一個條件時滿足的。 2. 轉移矩陣A 是不可約的; 同樣的道理,正常的web拓樸不一定能滿足完全強連通的條件,但是因為隨機概率轉移矩陣(心靈矩陣)的存在,這第二個條件也成立 3. 轉移矩陣A 是非週期的; 同樣因為隨機概率轉移矩陣(心靈矩陣)的存在,週期性的定義無法滿足,所以最終的轉移矩陣可以說滿足非週期性
上述的3個條件使得收斂性的前兩個條件得到了滿足。接下來還剩最後一個問題,即'網頁排序的依據是否是真的合理'。
Relevant Link:
http://www.doc88.com/p-8018027982328.html
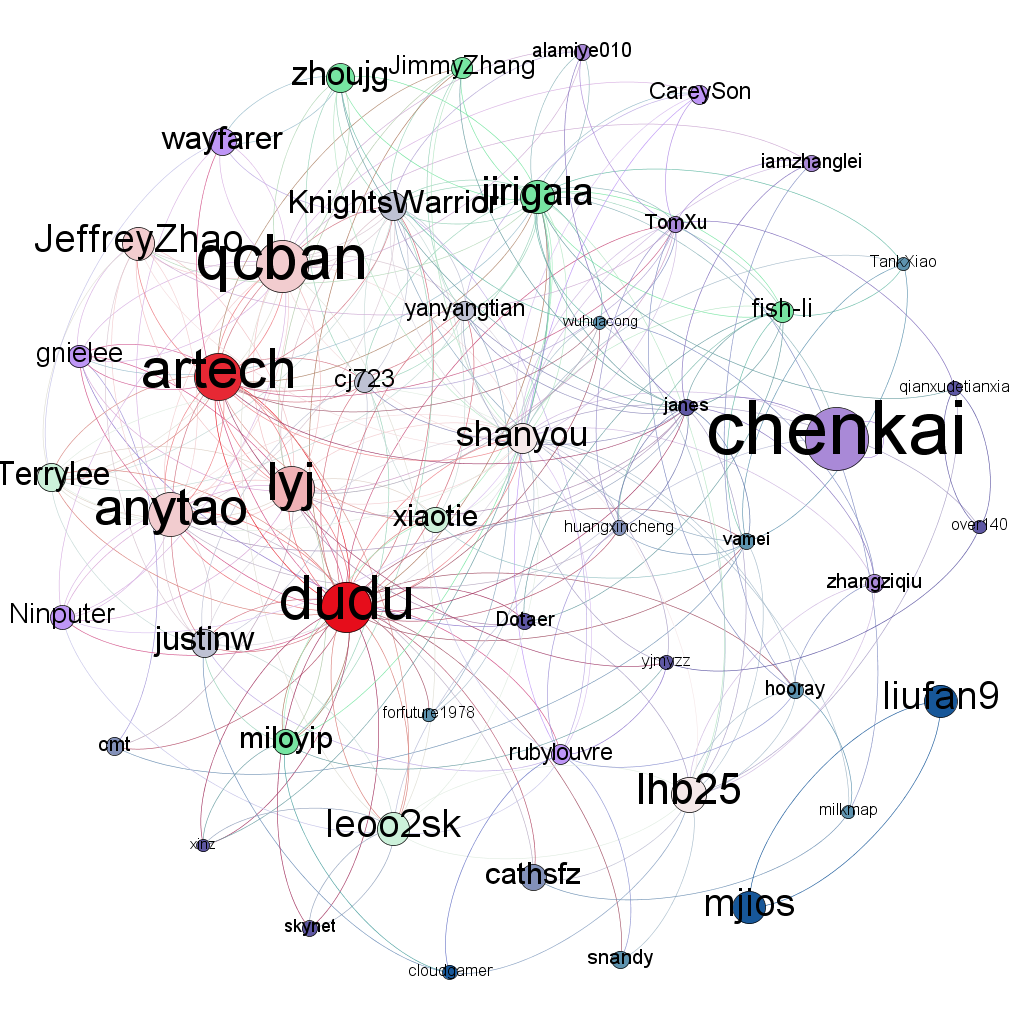
5. 部落格園使用者PageRank排名
針對部落格園的使用者建立爬蟲,以自己為起點。
從followers和follwees的關係進行深廣度遍歷,最終得到部落格園關注網拓樸,coding中。
效果類似下圖:
Relevant Link:
http://www.cnblogs.com/fengfenggirl/p/pagerank-cnblogs.html https://github.com/BigPeng/cnblogs-user-pagerank