大資料Map Reduce 和 MPP資料庫 的區別
下面在這篇文章裡對MR的解釋很好, 從原理的角度出發, map reduce其實就是二分查詢的一個逆過程, 不過因為計算節點有限, 所以map和reduce前都預先有一個分割槽的步驟. 二分查詢要求資料是排序好的, 所以Map Reduce之間會有一個shuffle的過程對Map的結果排序. Reduce的輸入是排好序的.
https://blog.csdn.net/dreamy_lin/article/details/81391859
MR分而治之的策略和資料庫行業中另一種資料庫 Massively Parallel Processor 即大規模並行處理資料庫(典型代表 AWS Redshift 和 Teradata 以及微軟的 Azure SQL Data Warehouse)有什麼區別呢?
MPP的思路簡單粗暴, 把資料分塊, 交給不同節點儲存, 查詢的時候各塊的節點有獨立的計算資源分別處理, 然後彙總到一個leader node(又叫control node), 具體的優化和傳統的關係型資料庫很相似, 涉及到了索引, 統計資訊等概念. MPP有shared everything /Disk / Nothing之別.
舉例來說說區別:
比如一張銷售表, 其中有一列產品類別, 現在要知道各個產品類別的銷量.
| 類別a | 1 |
| 類別a | 2 |
| 類別b | 3 |
| 類別b | 1 |
| 類別c | 4 |
MR處理方法: 在map階段,對每個hdfs的block統計各個類別銷量, 然後shuffle根據類別列排序, reduce階段合併
MPP處理方法: 每個block有單獨的計算節點統計各個類別銷量, 彙總結果到leader node, leader做個合併,在這個案例裡就是做幾次加法
可以看到在這個場景中MPP的效率絕對比MR高的多, 因為省去了shuffle排序的過程. 其他步驟都很相似.
在實際應用中的確MPP有更高的效率, 所以對於結構化的大資料, MPP至今仍是首選.
MR 或者 Spark勝過MPP的地方在於非結構化的資料處理上, 比如大量日誌檔案或者大量tweet. 或者在一些複雜的演算法應用上MR或Spark的可程式設計性顯得更加靈活. Hadoop複雜的ecosystem對於複雜情況有著更好的應對, 而對於結構化的大資料, 要是出一些純統計數字的報表的話, Hadoop有點虎落平陽被犬欺的感覺. 一些大公司的架構也是MPP和Hadoop兩者兼具的. 既有用MPP處理傳統的BI報表業務, 又有使用Hadoop做一些深入分析的應用. 未來MPP和hadoop能否融合起來, 是一個值得觀察的發展方向.
以下為轉載:
Shared Everything:一般是針對單個主機,完全透明共享CPU/MEMORY/IO,並行處理能力是最差的,典型的代表SQLServer
Shared Disk:各個處理單元使用自己的私有 CPU和Memory,共享磁碟系統。典型的代表Oracle Rac, 它是資料共享,可通過增加節點來提高並行處理的能力,擴充套件能力較好。其類似於SMP(對稱多處理)模式,但是當儲存器介面達到飽和的時候,增加節點並不能獲得更高的效能 。
Shared Nothing:各個處理單元都有自己私有的CPU/記憶體/硬碟等,不存在共享資源,類似於MPP(大規模並行處理)模式,各處理單元之間通過協議通訊,並行處理和擴充套件能力更好。典型代表DB2 DPF和hadoop ,各節點相互獨立,各自處理自己的資料,處理後的結果可能向上層彙總或在節點間流轉。
我們常說的 Sharding 其實就是Share Nothing架構,它是把某個表從物理儲存上被水平分割,並分配給多臺伺服器(或多個例項),每臺伺服器可以獨立工作,具備共同的schema,比如MySQL Proxy和Google的各種架構,只需增加伺服器數就可以增加處理能力和容量。
- 首先MPP 必須消除手工切分資料的工作量。 這是MySQL 在網際網路應用中的主要侷限性。
-
另外MPP 的切分必須在任何時候都是平均的 , 不然某些節點處理的時間就明顯多於另外一些節點。
對於工作負載是不是要平均分佈有同種和異種之分,同種就是所有節點在資料裝載的時候都同時轉載,異種就是可以指定部分節點專門用來裝載資料(邏輯上的不 是物理上) , 而其他所有節點用來負責查詢。 Aster Data 和Greenplum 都屬於這種。 兩者之間並沒有明顯的優勢科研,同種的工作負載情況下,需要軟體提供商保證所有節點的負載是平衡的。 而異種的工作負載可以在你覺得資料裝載很慢的情況下手工指定更多節點裝載資料 。 區別其實就是自動化和手工控制,看個人喜好而已。
-
另外一個問題是查詢如何被初始化的。 比如要查詢銷售最好的10件商品,每個節點都要先計算出自己的最好的10件商品,然後向上彙總,彙總的過程,肯定有些節點做的工作比其他節點要多。
上面只是一個簡單的單表查詢,如果是兩個表的連線查詢,可能還會涉及到節點之間計算的中間過程如何傳遞的問題。 是將大表和小表都平均分佈,然後節點計算的時候將得到的結果彙總(可能要兩次彙總),還是將大表平均分佈,小表的資料傳輸給每個節點,這樣彙總就只需要一 次。 (其中一個特例可以參考後面給出的Oracle Partition Wise Join) 。 兩種執行計劃很難說誰好誰壞,資料量的大小可能會產生不同的影響。 有些特定的廠商專門對這種執行計劃做過了優化的,比如EMC Greenplum 和 HP Vertica 。 這其中涉及到很多取捨問題,比如資料分佈模式,資料重新分佈的成本,中間交換資料的網絡卡速度,儲存介質讀寫的速度和資料量大小(計算過程一般都會用臨時表 儲存中間過程)。
轉載部分的原文連結:
https://blog.csdn.net/seteor/article/details/10532085
https://blog.csdn.net/fengyuruhui123/article/details/53285537
下面這段描述了MPP(Azure Data Warehouse)中怎麼把一張大表分佈到各個節點上(https://docs.microsoft.com/en-us/azure/sql-data-warehouse/massively-parallel-processing-mpp-architecture):
Hash-distributed tables(轉者注: 在可能經常要filter或join的列上用hash來分佈)
A hash distributed table can deliver the highest query performance for joins and aggregations on large tables.
To shard data into a hash-distributed table, SQL Data Warehouse uses a hash function to deterministically assign each row to one distribution. In the table definition, one of the columns is designated as the distribution column. The hash function uses the values in the distribution column to assign each row to a distribution.
The following diagram illustrates how a full (non-distributed table) gets stored as a hash-distributed table.

- Each row belongs to one distribution.
- A deterministic hash algorithm assigns each row to one distribution.
- The number of table rows per distribution varies as shown by the different sizes of tables.
There are performance considerations for the selection of a distribution column, such as distinctness, data skew, and the types of queries that run on the system.
Round-robin distributed tables (轉者注: 純隨機分佈)
A round-robin table is the simplest table to create and delivers fast performance when used as a staging table for loads.
A round-robin distributed table distributes data evenly across the table but without any further optimization. A distribution is first chosen at random and then buffers of rows are assigned to distributions sequentially. It is quick to load data into a round-robin table, but query performance can often be better with hash distributed tables. Joins on round-robin tables require reshuffling data and this takes additional time.
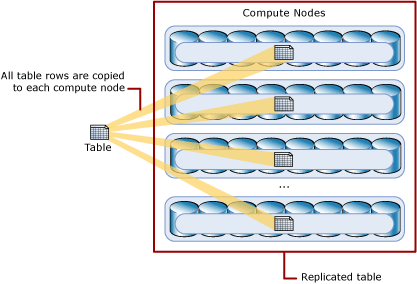
Replicated Tables (轉者注: 這就類似hadoop中的分散式快取)
A replicated table provides the fastest query performance for small tables.
A table that is replicated caches a full copy of the table on each compute node. Consequently, replicating a table removes the need to transfer data among compute nodes before a join or aggregation. Replicated tables are best utilized with small tables. Extra storage is required and there are additional overheads that are incurred when writing data which make large tables impractical.
The following diagram shows a replicated table. For SQL Data Warehouse, the replicated table is cached on the first distribution on each compute node.