
word2vec原理(三) 基於Negative Sampling的模型
轉自http://www.cnblogs.com/pinard/p/7249903.html
在上一篇中我們講到了基於Hierarchical Softmax的word2vec模型,本文我們我們再來看看另一種求解word2vec模型的方法:Negative Sampling。
1. Hierarchical Softmax的缺點與改進
在講基於Negative Sampling的word2vec模型前,我們先看看Hierarchical Softmax的的缺點。的確,使用霍夫曼樹來代替傳統的神經網路,可以提高模型訓練的效率。但是如果我們的訓練樣本里的中心詞ww是一個很生僻的詞,那麼就得在霍夫曼樹中辛苦的向下走很久了。能不能不用搞這麼複雜的一顆霍夫曼樹,將模型變的更加簡單呢?
Negative Sampling就是這麼一種求解word2vec模型的方法,它摒棄了霍夫曼樹,採用了Negative Sampling(負取樣)的方法來求解,下面我們就來看看Negative Sampling的求解思路。
2. 基於Negative Sampling的模型概述
既然名字叫Negative Sampling(負取樣),那麼肯定使用了取樣的方法。取樣的方法有很多種,比如之前講到的大名鼎鼎的MCMC。我們這裡的Negative Sampling取樣方法並沒有MCMC那麼複雜。
比如我們有一個訓練樣本,中心詞是ww,它周圍上下文共有2c2c個詞,記為context(w)context(w)。由於這個中心詞ww,的確和context(w)context(w)相關存在,因此它是一個真實的正例。通過Negative Sampling取樣,我們得到neg個和ww不同的中心詞wi,i=1,2,..negwi,i=1,2,..neg,這樣context(w)context(w)和$$w_i$就組成了neg個並不真實存在的負例。利用這一個正例和neg個負例,我們進行二元邏輯迴歸,得到負取樣對應每個詞$w_i$對應的模型引數$\theta_{i}$,和每個詞的詞向量。
從上面的描述可以看出,Negative Sampling由於沒有采用霍夫曼樹,每次只是通過取樣neg個不同的中心詞做負例,就可以訓練模型,因此整個過程要比Hierarchical Softmax簡單。
不過有兩個問題還需要弄明白:1)如果通過一個正例和neg個負例進行二元邏輯迴歸呢? 2) 如何進行負取樣呢?
我們在第三節討論問題1,在第四節討論問題2.
3. 基於Negative Sampling的模型梯度計算
Negative Sampling也是採用了二元邏輯迴歸來求解模型引數,通過負取樣,我們得到了neg個負例(context(w),wi)i=1,2,..neg(context(w),wi)i=1,2,..neg。為了統一描述,我們將正例定義為w0w0。
在邏輯迴歸中,我們的正例應該期望滿足:
P(context(w0),wi)=σ(xTw0θwi),yi=1,i=0P(context(w0),wi)=σ(xw0Tθwi),yi=1,i=0
我們的負例期望滿足:
P(context(w0),wi)=1−σ(xTw0θwi),yi=0,i=1,2,..negP(context(w0),wi)=1−σ(xw0Tθwi),yi=0,i=1,2,..neg
我們期望可以最大化下式:
∏i=0negP(context(w0),wi)=σ(xTw0θw0)∏i=1neg(1−σ(xTw0θwi))∏i=0negP(context(w0),wi)=σ(xw0Tθw0)∏i=1neg(1−σ(xw0Tθwi))
利用邏輯迴歸和上一節的知識,我們容易寫出此時模型的似然函式為:
∏i=0negσ(xTw0θwi)yi(1−σ(xTw0θwi))1−yi∏i=0negσ(xw0Tθwi)yi(1−σ(xw0Tθwi))1−yi
此時對應的對數似然函式為:
L=∑i=0negyilog(σ(xTw0θwi))+(1−yi)log(1−σ(xTw0θwi))L=∑i=0negyilog(σ(xw0Tθwi))+(1−yi)log(1−σ(xw0Tθwi))
和Hierarchical Softmax類似,我們採用隨機梯度上升法,僅僅每次只用一個樣本更新梯度,來進行迭代更新得到我們需要的xwi,θwi,i=0,1,..negxwi,θwi,i=0,1,..neg, 這裡我們需要求出xw0,θwi,i=0,1,..negxw0,θwi,i=0,1,..neg的梯度。
首先我們計算θwiθwi的梯度:
∂L∂θwi=yi(1−σ(xTw0θwi))xw0−(1−yi)σ(xTw0θwi)xw0=(yi−σ(xTw0θwi))xw0(1)(2)(1)∂L∂θwi=yi(1−σ(xw0Tθwi))xw0−(1−yi)σ(xw0Tθwi)xw0(2)=(yi−σ(xw0Tθwi))xw0
同樣的方法,我們可以求出xw0xw0的梯度如下:
∂L∂xw0=∑i=0neg(yi−σ(xTw0θwi))θwi∂L∂xw0=∑i=0neg(yi−σ(xw0Tθwi))θwi
有了梯度表示式,我們就可以用梯度上升法進行迭代來一步步的求解我們需要的xw0,θwi,i=0,1,..negxw0,θwi,i=0,1,..neg。
4. Negative Sampling負取樣方法
現在我們來看看如何進行負取樣,得到neg個負例。word2vec取樣的方法並不複雜,如果詞彙表的大小為VV,那麼我們就將一段長度為1的線段分成VV份,每份對應詞彙表中的一個詞。當然每個詞對應的線段長度是不一樣的,高頻詞對應的線段長,低頻詞對應的線段短。每個詞ww的線段長度由下式決定:
len(w)=count(w)∑u∈vocabcount(u)len(w)=count(w)∑u∈vocabcount(u)
在word2vec中,分子和分母都取了3/4次冪如下:
len(w)=count(w)3/4∑u∈vocabcount(u)3/4len(w)=count(w)3/4∑u∈vocabcount(u)3/4
在取樣前,我們將這段長度為1的線段劃分成MM等份,這裡M>>VM>>V,這樣可以保證每個詞對應的線段都會劃分成對應的小塊。而M份中的每一份都會落在某一個詞對應的線段上。在取樣的時候,我們只需要從MM個位置中取樣出negneg個位置就行,此時取樣到的每一個位置對應到的線段所屬的詞就是我們的負例詞。
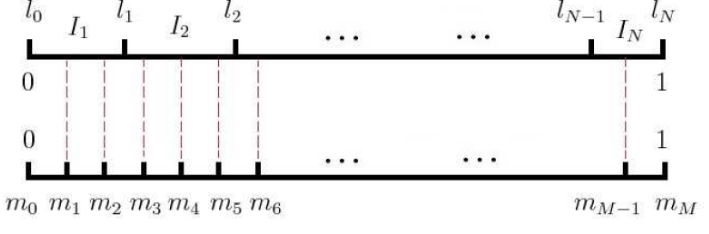
在word2vec中,MM取值預設為108108。
5. 基於Negative Sampling的CBOW模型
有了上面Negative Sampling負取樣的方法和邏輯迴歸求解模型引數的方法,我們就可以總結出基於Negative Sampling的CBOW模型演算法流程了。梯度迭代過程使用了隨機梯度上升法:
輸入:基於CBOW的語料訓練樣本,詞向量的維度大小McountMcount,CBOW的上下文大小2c2c,步長ηη, 負取樣的個數neg
輸出:詞彙表每個詞對應的模型引數θθ,所有的詞向量xwxw
1. 隨機初始化所有的模型引數θθ,所有的詞向量ww
2. 對於每個訓練樣本(context(w0),w0)(context(w0),w0),負取樣出neg個負例中心詞wi,i=1,2,...negwi,i=1,2,...neg
3. 進行梯度上升迭代過程,對於訓練集中的每一個樣本(context(w0),w0,w1,...wneg)(context(w0),w0,w1,...wneg)做如下處理:
a) e=0, 計算xw0=12c∑i=12cxixw0=12c∑i=12cxi
b) for i= 0 to neg, 計算:
f=σ(xTw0θwi)f=σ(xw0Tθwi)
g=(yi−f)ηg=(yi−f)η
e=e+gθwie=e+gθwi
θwi=θwi+gxw0θwi=θwi+gxw0
c) 對於context(w)context(w)中的每一個詞向量xkxk(共2c個)進行更新:
xk=xk+exk=xk+e
d) 如果梯度收斂,則結束梯度迭代,否則回到步驟3繼續迭代。
6. 基於Negative Sampling的Skip-Gram模型
有了上一節CBOW的基礎和上一篇基於Hierarchical Softmax的Skip-Gram模型基礎,我們也可以總結出基於Negative Sampling的Skip-Gram模型演算法流程了。梯度迭代過程使用了隨機梯度上升法:
輸入:基於Skip-Gram的語料訓練樣本,詞向量的維度大小McountMcount,Skip-Gram的上下文大小2c2c,步長ηη, , 負取樣的個數neg。
輸出:詞彙表每個詞對應的模型引數θθ,所有的詞向量xwxw
1. 隨機初始化所有的模型引數θθ,所有的詞向量ww
2. 對於每個訓練樣本(context(w0),w0)(context(w0),w0),負取樣出neg個負例中心詞wi,i=1,2,...negwi,i=1,2,...neg
3. 進行梯度上升迭代過程,對於訓練集中的每一個樣本(context(w0),w0,w1,...wneg)(context(w0),w0,w1,...wneg)做如下處理:
a) for i =1 to 2c:
i) e=0
ii) for j= 0 to neg, 計算:
f=σ(xTw0iθwj)f=σ(xw0iTθwj)
g=(yj−f)ηg=(yj−f)η
e=e+gθwje=e+gθwj
θwj=θwj+gxw0iθwj=θwj+gxw0i
iii) 對於context(w)context(w)中的每一個詞向量xkxk(共2c個)進行更新:
xk=xk+exk=xk+e
b)如果梯度收斂,則結束梯度迭代,演算法結束,否則回到步驟a繼續迭代。
7. Negative Sampling的模型原始碼和演算法的對應
這裡給出上面演算法和word2vec原始碼中的變數對應關係。
在原始碼中,基於Negative Sampling的CBOW模型演算法在464-494行,基於Hierarchical Softmax的Skip-Gram的模型演算法在520-542行。大家可以對著原始碼再深入研究下演算法。
在原始碼中,neule對應我們上面的ee, syn0對應我們的xwxw, syn1neg對應我們的θwiθwi, layer1_size對應詞向量的維度,window對應我們的cc。negative對應我們的neg, table_size對應我們負取樣中的劃分數MM。
另外,vocab[word].code[d]指的是,當前單詞word的,第d個編碼,編碼不含Root結點。vocab[word].point[d]指的是,當前單詞word,第d個編碼下,前置的結點。這些和基於Hierarchical Softmax的是一樣的。
以上就是基於Negative Sampling的word2vec模型,希望可以幫到大家,後面會講解用gensim的python版word2vec來使用word2vec解決實際問題。