
word2vec原理(二) 基於Hierarchical Softmax的模型
轉自http://www.cnblogs.com/pinard/p/7243513.html
在word2vec原理(一) CBOW與Skip-Gram模型基礎中,我們講到了使用神經網路的方法來得到詞向量語言模型的原理和一些問題,現在我們開始關注word2vec的語言模型如何改進傳統的神經網路的方法。由於word2vec有兩種改進方法,一種是基於Hierarchical Softmax的,另一種是基於Negative Sampling的。本文關注於基於Hierarchical Softmax的改進方法,在下一篇討論基於Negative Sampling的改進方法。
1. 基於Hierarchical Softmax的模型概述
我們先回顧下傳統的神經網路詞向量語言模型,裡面一般有三層,輸入層(詞向量),隱藏層和輸出層(softmax層)。裡面最大的問題在於從隱藏層到輸出的softmax層的計算量很大,因為要計算所有詞的softmax概率,再去找概率最大的值。這個模型如下圖所示。其中VV是詞彙表的大小,
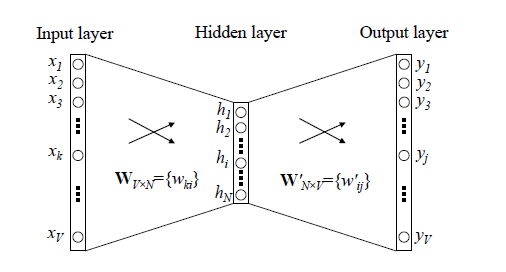
word2vec對這個模型做了改進,首先,對於從輸入層到隱藏層的對映,沒有采取神經網路的線性變換加啟用函式的方法,而是採用簡單的對所有輸入詞向量求和並取平均的方法。比如輸入的是三個4維詞向量:(1,2,3,4),(9,6,11,8),(5,10,7,12)(1,2,3,4),(9,6,11,8),(5,10,7,12),那麼我們word2vec對映後的詞向量就是(5,6,7,8)(5,6,7,8)。由於這裡是從多個詞向量變成了一個詞向量。
第二個改進就是從隱藏層到輸出的softmax層這裡的計算量個改進。為了避免要計算所有詞的softmax概率,word2vec取樣了霍夫曼樹來代替從隱藏層到輸出softmax層的對映。我們在上一節已經介紹了霍夫曼樹的原理。如何對映呢?這裡就是理解word2vec的關鍵所在了。
由於我們把之前所有都要計算的從輸出softmax層的概率計算變成了一顆二叉霍夫曼樹,那麼我們的softmax概率計算只需要沿著樹形結構進行就可以了。如下圖所示,我們可以沿著霍夫曼樹從根節點一直走到我們的葉子節點的詞w2w2。

和之前的神經網路語言模型相比,我們的霍夫曼樹的所有內部節點就類似之前神經網路隱藏層的神經元,其中,根節點的詞向量對應我們的投影后的詞向量,而所有葉子節點就類似於之前神經網路softmax輸出層的神經元,葉子節點的個數就是詞彙表的大小。在霍夫曼樹中,隱藏層到輸出層的softmax對映不是一下子完成的,而是沿著霍夫曼樹一步步完成的,因此這種softmax取名為"Hierarchical Softmax"。
如何“沿著霍夫曼樹一步步完成”呢?在word2vec中,我們採用了二元邏輯迴歸的方法,即規定沿著左子樹走,那麼就是負類(霍夫曼樹編碼1),沿著右子樹走,那麼就是正類(霍夫曼樹編碼0)。判別正類和負類的方法是使用sigmoid函式,即:
P(+)=σ(xTwθ)=11+e−xTwθP(+)=σ(xwTθ)=11+e−xwTθ
其中xwxw是當前內部節點的詞向量,而θθ則是我們需要從訓練樣本求出的邏輯迴歸的模型引數。
使用霍夫曼樹有什麼好處呢?首先,由於是二叉樹,之前計算量為VV,現在變成了log2Vlog2V。第二,由於使用霍夫曼樹是高頻的詞靠近樹根,這樣高頻詞需要更少的時間會被找到,這符合我們的貪心優化思想。
容易理解,被劃分為左子樹而成為負類的概率為P(−)=1−P(+)P(−)=1−P(+)。在某一個內部節點,要判斷是沿左子樹還是右子樹走的標準就是看P(−),P(+)P(−),P(+)誰的概率值大。而控制P(−),P(+)P(−),P(+)誰的概率值大的因素一個是當前節點的詞向量,另一個是當前節點的模型引數θθ。
對於上圖中的w2w2,如果它是一個訓練樣本的輸出,那麼我們期望對於裡面的隱藏節點n(w2,1)n(w2,1)的P(−)P(−)概率大,n(w2,2)n(w2,2)的P(−)P(−)概率大,n(w2,3)n(w2,3)的P(+)P(+)概率大。
回到基於Hierarchical Softmax的word2vec本身,我們的目標就是找到合適的所有節點的詞向量和所有內部節點θθ, 使訓練樣本達到最大似然。那麼如何達到最大似然呢?
2. 基於Hierarchical Softmax的模型梯度計算
我們使用最大似然法來尋找所有節點的詞向量和所有內部節點θθ。先拿上面的w2w2例子來看,我們期望最大化下面的似然函式:
∏i=13P(n(wi),i)=(1−11+e−xTwθ1)(1−11+e−xTwθ2)11+e−xTwθ3∏i=13P(n(wi),i)=(1−11+e−xwTθ1)(1−11+e−xwTθ2)11+e−xwTθ3
對於所有的訓練樣本,我們期望最大化所有樣本的似然函式乘積。
為了便於我們後面一般化的描述,我們定義輸入的詞為ww,其從輸入層詞向量求和平均後的霍夫曼樹根節點詞向量為xwxw, 從根節點到ww所在的葉子節點,包含的節點總數為lwlw, ww在霍夫曼樹中從根節點開始,經過的第ii個節點表示為pwipiw,對應的霍夫曼編碼為dwi∈{0,1}diw∈{0,1},其中i=2,3,...lwi=2,3,...lw。而該節點對應的模型引數表示為θwiθiw, 其中i=1,2,...lw−1i=1,2,...lw−1,沒有i=lwi=lw是因為模型引數僅僅針對於霍夫曼樹的內部節點。
定義ww經過的霍夫曼樹某一個節點j的邏輯迴歸概率為P(dwj|xw,θwj−1)P(djw|xw,θj−1w),其表示式為:
P(dwj|xw,θwj−1)={σ(xTwθwj−1)1−σ(xTwθwj−1)dwj=0dwj=1P(djw|xw,θj−1w)={σ(xwTθj−1w)djw=01−σ(xwTθj−1w)djw=1
那麼對於某一個目標輸出詞ww,其最大似然為:
∏j=2lwP(dwj|xw,θwj−1)=∏j=2lw[σ(xTwθwj−1)]1−dwj[1−σ(xTwθwj−1)]dwj∏j=2lwP(djw|xw,θj−1w)=∏j=2lw[σ(xwTθj−1w)]1−djw[1−σ(xwTθj−1w)]djw
在word2vec中,由於使用的是隨機梯度上升法,所以並沒有把所有樣本的似然乘起來得到真正的訓練集最大似然,僅僅每次只用一個樣本更新梯度,這樣做的目的是減少梯度計算量。這樣我們可以得到ww的對數似然函式LL如下:
L=log∏j=2lwP(dwj|xw,θwj−1)=∑j=2lw((1−dwj)log[σ(xTwθwj−1)]+dwjlog[1−σ(xTwθwj−1)])L=log∏j=2lwP(djw|xw,θj−1w)=∑j=2lw((1−djw)log[σ(xwTθj−1w)]+djwlog[1−σ(xwTθj−1w)])
要得到模型中ww詞向量和內部節點的模型引數θθ, 我們使用梯度上升法即可。首先我們求模型引數θwj−1θj−1w的梯度:
∂L∂θwj−1=(1−dwj)(σ(xTwθwj−1)(1−σ(xTwθwj−1)σ(xTwθwj−1)xw−dwj(σ(xTwθwj−1)(1−σ(xTwθwj−1)1−σ(xTwθwj−1)xw=(1−dwj)(1−σ(xTwθwj−1))xw−dwjσ(xTwθwj−1)xw=(1−dwj−σ(xTwθwj−1))xw(1)(2)(3)(1)∂L∂θj−1w=(1−djw)(σ(xwTθj−1w)(1−σ(xwTθj−1w)σ(xwTθj−1w)xw−djw(σ(xwTθj−1w)(1−σ(xwTθj−1w)1−σ(xwTθj−1w)xw(2)=(1−djw)(1−σ(xwTθj−1w))xw−djwσ(xwTθj−1w)xw(3)=(1−djw−σ(xwTθj−1w))xw
如果大家看過之前寫的邏輯迴歸原理小結,會發現這裡的梯度推導過程基本類似。
同樣的方法,可以求出xwxw的梯度表示式如下:
∂L∂xw=∑j=2lw(1−dwj−σ(xTwθwj−1))θwj−1∂L∂xw=∑j=2lw(1−djw−σ(xwTθj−1w))θj−1w
有了梯度表示式,我們就可以用梯度上升法進行迭代來一步步的求解我們需要的所有的θwj−1θj−1w和xwxw。
3. 基於Hierarchical Softmax的CBOW模型
由於word2vec有兩種模型:CBOW和Skip-Gram,我們先看看基於CBOW模型時, Hierarchical Softmax如何使用。
首先我們要定義詞向量的維度大小MM,以及CBOW的上下文大小2c2c,這樣我們對於訓練樣本中的每一個詞,其前面的cc個詞和後面的cc個詞作為了CBOW模型的輸入,該詞本身作為樣本的輸出,期望softmax概率最大。
在做CBOW模型前,我們需要先將詞彙表建立成一顆霍夫曼樹。
對於從輸入層到隱藏層(投影層),這一步比較簡單,就是對ww周圍的2c2c個詞向量求和取平均即可,即:
xw=12c∑i=12cxixw=12c∑i=12cxi
第二步,通過梯度上升法來更新我們的θwj−1θj−1w和xwxw,注意這裡的xwxw是由2c2c個詞向量相加而成,我們做梯度更新完畢後會用梯度項直接更新原始的各個xi(i=1,2,,,,2c)xi(i=1,2,,,,2c),即:
θwj−1=θwj−1+η(1−dwj−σ(xTwθwj−1))xwθj−1w=θj−1w+η(1−djw−σ(xwTθj−1w))xw
xw=xw+η∑j=2lw(1−dwj−σ(xTwθwj−1))θwj−1(i=1,2..,2c)xw=xw+η∑j=2lw(1−djw−σ(xwTθj−1w))θj−1w(i=1,2..,2c)
其中ηη為梯度上升法的步長。
這裡總結下基於Hierarchical Softmax的CBOW模型演算法流程,梯度迭代使用了隨機梯度上升法:
輸入:基於CBOW的語料訓練樣本,詞向量的維度大小MM,CBOW的上下文大小2c2c,步長ηη
輸出:霍夫曼樹的內部節點模型引數θθ,所有的詞向量ww
1. 基於語料訓練樣本建立霍夫曼樹。
2. 隨機初始化所有的模型引數θθ,所有的詞向量ww
3. 進行梯度上升迭代過程,對於訓練集中的每一個樣本(context(w),w)(context(w),w)做如下處理:
a) e=0, 計算xw=12c∑i=12cxixw=12c∑i=12cxi
b) for j = 2 to lwlw, 計算:
f=σ(xTwθwj−1)f=σ(xwTθj−1w)
g=(1−dwj−f)ηg=(1−djw−f)η
e=e+gθwj−1e=e+gθj−1w
θwj−1=θwj−1+gxwθj−1w=θj−1w+gxw
c) 對於context(w)context(w)中的每一個詞向量xixi(共2c個)進行更新:
xi=xi+exi=xi+e
d) 如果梯度收斂,則結束梯度迭代,否則回到步驟3繼續迭代。
4. 基於Hierarchical Softmax的Skip-Gram模型
現在我們先看看基於Skip-Gram模型時, Hierarchical Softmax如何使用。此時輸入的只有一個詞ww,輸出的為2c2c個詞向量context(w)context(w)。
我們對於訓練樣本中的每一個詞,該詞本身作為樣本的輸入, 其前面的cc個詞和後面的cc個詞作為了Skip-Gram模型的輸出,,期望這些詞的softmax概率比其他的詞大。
Skip-Gram模型和CBOW模型其實是反過來的,在上一篇已經講過。
在做CBOW模型前,我們需要先將詞彙表建立成一顆霍夫曼樹。
對於從輸入層到隱藏層(投影層),這一步比CBOW簡單,由於只有一個詞,所以,即xwxw就是詞ww對應的詞向量。
第二步,通過梯度上升法來更新我們的θwj−1θj−1w和xwxw,注意這裡的xwxw周圍有2c2c個詞向量,此時如果我們期望P(xi|xw),i=1,2...2cP(xi|xw),i=1,2...2c最大。此時我們注意到由於上下文是相互的,在期望P(xi|xw),i=1,2...2cP(xi|xw),i=1,2...2c最大化的同時,反過來我們也期望P(xw|xi),i=1,2...2cP(xw|xi),i=1,2...2c最大。那麼是使用P(xi|xw)P(xi|xw)好還是P(xw|xi)P(xw|xi)好呢,word2vec使用了後者,這樣做的好處就是在一個迭代視窗內,我們不是隻更新xwxw一個詞,而是xi,i=1,2...2cxi,i=1,2...2c共2c2c個詞。這樣整體的迭代會更加的均衡。因為這個原因,Skip-Gram模型並沒有和CBOW模型一樣對輸入進行迭代更新,而是對2c2c個輸出進行迭代更新。
這裡總結下基於Hierarchical Softmax的Skip-Gram模型演算法流程,梯度迭代使用了隨機梯度上升法:
輸入:基於Skip-Gram的語料訓練樣本,詞向量的維度大小MM,Skip-Gram的上下文大小2c2c,步長ηη
輸出:霍夫曼樹的內部節點模型引數θθ,所有的詞向量ww
1. 基於語料訓練樣本建立霍夫曼樹。
2. 隨機初始化所有的模型引數θθ,所有的詞向量ww,
3. 進行梯度上升迭代過程,對於訓練集中的每一個樣本(w,context(w))(w,context(w))做如下處理:
a) for i =1 to 2c:
i) e=0
ii)for j = 2 to lwlw, 計算:
f=σ(xTiθwj−1)f=σ(xiTθj−1w)
g=(1−dwj−f)ηg=(1−djw−f)η
e=e+gθwj−1e=e+gθj−1w
θwj−1=θwj−1+gxiθj−1w=θj−1w+gxi
iii)
xi=xi+exi=xi+e
b)如果梯度收斂,則結束梯度迭代,演算法結束,否則回到步驟a繼續迭代。
5. Hierarchical Softmax的模型原始碼和演算法的對應
這裡給出上面演算法和word2vec原始碼中的變數對應關係。
在原始碼中,基於Hierarchical Softmax的CBOW模型演算法在435-463行,基於Hierarchical Softmax的Skip-Gram的模型演算法在495-519行。大家可以對著原始碼再深入研究下演算法。
在原始碼中,neule對應我們上面的ee, syn0對應我們的xwxw, syn1對應我們的θij−1θj−1i, layer1_size對應詞向量的維度,window對應我們的cc。
另外,vocab[word].code[d]指的是,當前單詞word的,第d個編碼,編碼不含Root結點。vocab[word].point[d]指的是,當前單詞word,第d個編碼下,前置的結點。
以上就是基於Hierarchical Softmax的word2vec模型,下一篇我們討論基於Negative Sampling的word2vec模型。