
Cross-Entropy Error、Classification Error、Mean Squared Error
一、引言
神經網路中,損失函式的選擇希望能夠有以下效果:
1、不同的預測結果能夠產生不同的損失,越好的結果損失要越小
2、在損失較大的情況下,學習的速率要相對較快
二、對比
1、區分性
假設有以下兩組資料,computed代表計算出來的概率,targets代表實際的標籤,correct代表分類結果是否正確
資料組1:

資料組2:

Classification Error
可以看到資料組1的分類損失為:1/3=0.33,其中樣本1和樣本2只是剛剛好達到正確分類的概率值,而樣本3就偏離正確分類非常遠;
而資料組2的分類損失為:1/3=0.33,其中樣本1和樣本2相對較好的分到了正確的類別,而樣本3距離正確的類別也不是相當遠。
但以上兩者的損失均為0.33,實際並沒有體現出兩者的區別,放到模型中,即是體現不出訓練的效果。
Mean Squared Error
對於MSE,同樣可以計算其損失:
在資料組1中,樣本1的平方損失為:(0.3 - 0)^2 + (0.3 - 0)^2 + (0.4 - 1)^2 = 0.09 + 0.09 + 0.36 = 0.54
相當於資料組1的MSE損失為:(0.54 + 0.54 + 1.34) / 3 = 0.81;
同樣,資料組2的MSE損失為:(0.14 + 0.14 + 0.74) / 3 = 0.34。
相比於分類損失,均方損失較好的體現了兩組資料的不同。
Cross-Entropy Error
對於交叉熵,同樣計算其損失,具體計算公式就不列舉了,如下:
資料組1的平均交叉熵損失為:-(ln(0.4) + ln(0.4) + ln(0.1)) / 3 = 1.38;
資料組2的平均交叉熵損失為:-(ln(0.7) + ln(0.7) + ln(0.3)) / 3 = 0.64。
交叉熵損失同樣能夠體現出兩組資料的區別。
從區分性可以得到,分類損失表現最差,均方損失與平均交叉熵損失表現較為良好。
2、學習速率
Mean Squared Error
在談及學習速率時,實際上談論的是什麼呢?在神經網路中,拋開learning rate這個引數,假設存在一個簡單網路:
在反向傳播時,通過計算代價函式的偏導
和
來改變權重與偏置,所以實際上說學習速率慢說的是偏導很小。
對於上述簡單網路,其表示式為z=wx+b,啟用函式選擇sigmoid,則有a=σ(z),假設存在樣本x=1,y=0,根據均方根損失函式有,

對損失函式求偏導,可得,
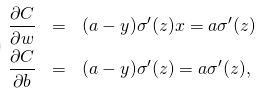
可以看到,最終偏導的大小有a與σ的偏導同時決定,再看看σ的圖形:
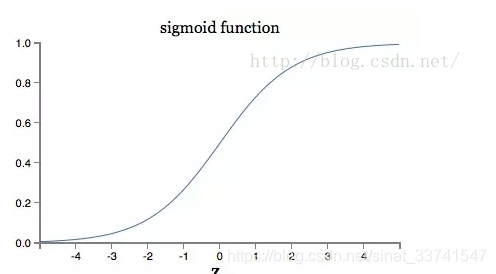
由影象可以看到,當輸出接近1時,曲線變得非常平坦,相應的偏導變得非常小,也就是學習速度變慢了,這也是經常被提到的啟用函式飽和。
所以均方損失面對以上情況時,效果較差。
Cross-Entropy Error
假設存在以下網路,
,
,樣本x,標籤為y,
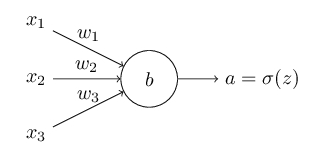
那麼交叉熵損失函式可定義為,
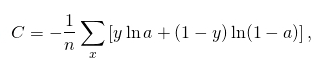
對損失函式求偏導,可得,
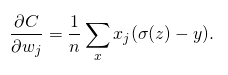
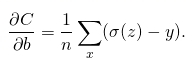
到這裡可以看到,最終偏導由σ(z)-y決定,即是由預測的結果與實際標籤的損失決定,誤差越大學習速度越快。
由學習速度可以看到,交叉熵相對均方損失表現更好。
三、其他
1、https://jamesmccaffrey.wordpress.com/2013/11/05/why-you-should-use-cross-entropy-error-instead-of-classification-error-or-mean-squared-error-for-neural-network-classifier-training/
2、https://yq.aliyun.com/ziliao/576107