機器學習一個小目標——Task2
阿新 • • 發佈:2018-11-20
【任務二】
構建SVM和決策樹模型進行預測【時間】11.16(今天)
遇到的問題
- 資料歸一化未完成
- 資料眾數填充未完成
實現程式碼
資料處理
#!/usr/bin/env python 3.6
#-*- coding:utf-8 -*-
# @File : feature.py
# @Date : 2018-11-16
# @Author : 黑桃
# @Software: PyCharm
import pickle
import pandas as pd #資料分析
from pandas import Series,DataFrame
from 讀取特徵 進行訓練
SVM
import pickle
import time
from sklearn.svm import LinearSVC
from sklearn.metrics import f1_score,mean_squared_error,r2_score
print("開始......")
t_start = time.time()
path = "E:/MyPython/Machine_learning_GoGoGo/"
"""=====================================================================================================================
1 讀取特徵
"""
print("0 讀取原特徵")
f = open(path + 'feature/V1.pkl', 'rb')
train, test, y_train,y_test = pickle.load(f)
f.close()
"""=====================================================================================================================
2 模型訓練
"""
print("支援向量機模型訓練")
Lin_SVC = LinearSVC()
Lin_SVC.fit(train,y_train)
"""=====================================================================================================================
3 模型預測
"""
y_test_pre = Lin_SVC.predict(test)
"""=====================================================================================================================
4 模型評分
"""
f1 = f1_score(y_test, y_test_pre, average='macro')
print("f1分數:{}".format(f1))
r2 = r2_score(y_test, y_test_pre)
print("f2分數:{}".format(r2))
score = Lin_SVC.score(test, y_test)
print("驗證集分數:{}".format(score))
決策樹
import pickle
import time
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import f1_score,r2_score
print("開始......")
t_start = time.time()
path = "E:/MyPython/Machine_learning_GoGoGo/"
"""=====================================================================================================================
1 讀取特徵
"""
print("0 讀取特徵")
f = open(path + 'feature/V1.pkl', 'rb')
train, test, y_train,y_test = pickle.load(f)
f.close()
"""=====================================================================================================================
2 模型訓練
"""
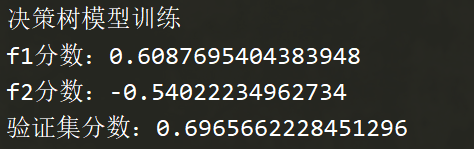
print("決策樹模型訓練")
DT = DecisionTreeClassifier()
DT.fit(train,y_train)
"""=====================================================================================================================
3 模型預測
"""
y_test_pre = DT.predict(test)
"""=====================================================================================================================
4 決策樹模型評分
"""
f1 = f1_score(y_test, y_test_pre, average='macro')
print("f1分數:{}".format(f1))
r2 = r2_score(y_test, y_test_pre)
print("f2分數:{}".format(r2))
score = DT.score(test, y_test)
print("驗證集分數:{}".format(score))
評分結果