機器學習一個小目標——Task3
阿新 • • 發佈:2018-12-22
任務
構建xgboost和lightgbm模型進行預測
遇到的問題
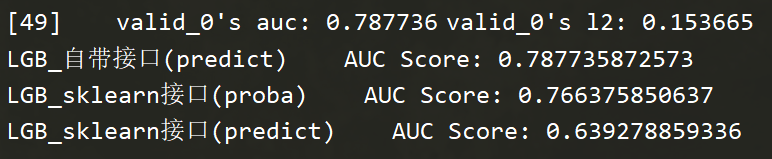
- LGB和XGB自帶介面預測(predict)的都是概率
- LGB和XGBa用sklearn的介面(predict)是分類結果,預測(proba)是概率
- 訓練之前都要將資料轉化為相應模型所需的格式
- 怎麼設定引數還不太瞭解
實現程式碼
XGB
#!/usr/bin/env python 3.6
#-*- coding:utf-8 -*-
# @File : XGBoost.py
# @Date : 2018-11-17
# @Author : 黑桃
# @Software: PyCharm
import xgboost as LGB
#!/usr/bin/env python 3.6
#-*- coding:utf-8 -*-
# @File : Lightgbm.py
# @Date : 2018-11-17
# @Author : 黑桃
# @Software: PyCharm
import lightgbm as lgb
import pickle
from sklearn import metrics
from sklearn.externals import joblib
path = "E:/MyPython/Machine_learning_GoGoGo/"
"""=====================================================================================================================
1 讀取特徵
"""
print("0 讀取特徵")
f = open(path + 'feature/feature_V1.pkl', 'rb')
train, test, y_train,y_test= pickle.load(f)
f.close()
"""【將資料格式轉換成lgb模型所需的格式】"""
lgb_train = lgb.Dataset(train, y_train)
lgb_eval = lgb.Dataset(test, y_test, reference=lgb_train)
"""=====================================================================================================================
2 設定模型訓練引數
"""
"""【LGB_自帶介面的引數】"""
params = {
'task': 'train',
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': {'l2', 'auc'},
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9,
'bagging_fraction': 0.8,
'bagging_freq': 5,
'verbose': 0
}
"""=====================================================================================================================
3 模型訓練
"""
##分類使用的是 LGBClassifier
##迴歸使用的是 LGBRegression
"""【LGB_自帶介面訓練】"""
model_lgb = lgb.train(params,lgb_train,num_boost_round=100,valid_sets=lgb_eval,early_stopping_rounds=10)
# y_lgb_proba = model_lgb.predict_proba(test)
"""【LGB_sklearn介面訓練】"""
lgb_sklearn = lgb.LGBMClassifier(learning_rate=0.1,
max_bin=150,
num_leaves=32,
max_depth=11,
reg_alpha=0.1,
reg_lambda=0.2,
# objective='multiclass',
n_estimators=300,)
lgb_sklearn.fit(train,y_train)
"""【儲存模型】"""
print('3 儲存模型')
joblib.dump(model_lgb, path + "model/lgb.pkl")
joblib.dump(lgb_sklearn, path + "model/lgb_sklearn.pkl")
"""=====================================================================================================================
4 模型預測
"""
"""【LGB_自帶介面預測】"""
y_lgb_pre = model_lgb.predict(test, num_iteration=model_lgb.best_iteration)
"""【LGB_sklearn介面預測】"""
y_sklearn_pre= lgb_sklearn.predict(test)
y_sklearn_proba= lgb_sklearn.predict_proba(test)[:,1]
"""=====================================================================================================================
5 模型評分
"""
print('LGB_自帶介面(predict) AUC Score:', metrics.roc_auc_score(y_test, y_lgb_pre) )
print('LGB_sklearn介面(proba) AUC Score:', metrics.roc_auc_score(y_test, y_sklearn_proba) )
print('LGB_sklearn介面(predict) AUC Score:', metrics.roc_auc_score(y_test, y_sklearn_pre) )
## [lightgbm的原生版本與sklearn 介面版本對比](https://blog.csdn.net/PIPIXIU/article/details/82709899)
## [lightGBM原理、改進簡述](https://blog.csdn.net/niaolianjiulin/article/details/76584785)
## [LightGBM 如何調參](https://blog.csdn.net/aliceyangxi1987/article/details/80711014)
模型評分
【roc_auc_score】
直接根據真實值(必須是二值)、預測值(可以是0/1,也可以是proba值)計算出auc值,中間過程的roc計算省略。