
機器學習一個小目標——Task6
阿新 • • 發佈:2018-11-24
1. 任務
使用網格搜尋對模型進行調優並採用五折交叉驗證的方式進行模型評估
2. 網格搜尋
2.1 什麼是Grid Search 網格搜尋?
網格搜尋是一種調參手段;在所有候選的引數選擇中,通過迴圈遍歷,嘗試每一種可能性,表現最好的引數就是最終的結果。其原理就像是在數組裡找最大值。(為什麼叫網格搜尋?以有兩個引數的模型為例,引數a有3種可能,引數b有4種可能,把所有可能性列出來,可以表示成一個3*4的表格,其中每個cell就是一個網格,迴圈過程就像是在每個網格里遍歷、搜尋,所以叫grid search)
2.2 Simple Grid Search:簡單的網格搜尋
原始資料集劃分成訓練集和測試集以後,其中測試集除了用作調整引數,也用來測量模型的好壞
缺點:導致最終的評分結果比實際效果要好。(因為測試集在調參過程中,送到了模型裡,而我們的目的是將訓練模型應用在unseen data上)
解決方法:對訓練集再進行一次劃分,分成訓練集和驗證集,這樣劃分的結果就是:原始資料劃分為3份,分別為:訓練集、驗證集和測試集;其中訓練集用來模型訓練,驗證集用來調整引數,而測試集用來衡量模型表現好壞。然而,這種簡單的grid search方法,其最終的表現好壞與初始資料的劃分結果有很大的關係,為了處理這種情況,我們採用交叉驗證的方式來減少偶然性。
2.3 實現程式碼(使用SVM模型)
#!/usr/bin/env python 3.6
#-*- coding:utf-8 -*-
# @File : GridSearch.py
# @Date : 2018-11-23
# @Author : 黑桃
# @Software: PyCharm
import pickle
from sklearn.svm import SVC
path = "E:/MyPython/Machine_learning_GoGoGo/"
"""=====================================================================================================================
1 讀取資料
"""
print("0 讀取特徵")
f = open(path + 'feature/feature_V3.pkl', 'rb')
X_train,X_test,y_train,y_test = pickle.load(f)
f.close()
print("訓練集:{} 測試集:{}".format(X_train.shape[0],X_test.shape[0]))
"""=====================================================================================================================
2 網格搜尋
"""
# X_train,X_val,y_train,y_val = train_test_split(X_train,y_train,test_size=0.3,random_state=1)
X_train,X_val,y_train,y_val = X_train,X_test,y_train,y_test
print("訓練集:{} 驗證集:{} 測試集:{}".format(X_train.shape[0],X_val.shape[0],X_test.shape[0]))
best_score = 0
for gamma in [0.001,0.01,0.1,1,10,100]:
for C in [0.001,0.01,0.1,1,10,100]:
svm = SVC(gamma=gamma,C=C)
svm.fit(X_train,y_train)
score = svm.score(X_val,y_val)
print("當前gamma值:{} , 當前C值:{}, 當前分數:{}".format(gamma, C, score))
if score > best_score:
best_score = score
best_parameters = {'gamma':gamma,'C':C}
svm = SVC(**best_parameters) #使用最佳引數,構建新的模型
svm.fit(X_train,y_train) #使用訓練集和驗證集進行訓練,more data always results in good performance.
test_score = svm.score(X_test,y_test) # evaluation模型評估
print("Best score on validation set:{}".format(best_score))
print("Best parameters:{}".format(best_parameters))
print("Best score on test set:{}".format(test_score))
3. 交叉驗證
3.1 原理
一個模型如果效能不好,要麼是因為模型過於複雜導致過擬合(高方差),要麼是模型過於簡單導致導致欠擬合(高偏差)。使用交叉驗證評估模型的泛化能力,使用交叉驗證可以減少初始資料的劃分的偶然性,使得對模型的評估更加準確。
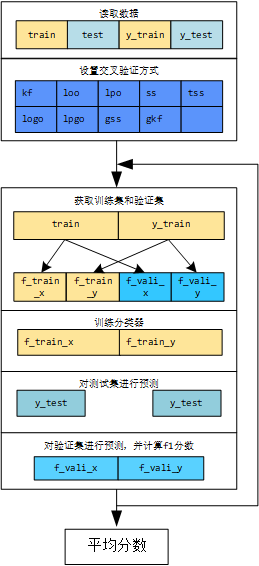
3.2 交叉驗證方式
sklearn中的交叉驗證(Cross-Validation)
"""
3.1 交叉驗證方式
"""
## 對交叉驗證方式進行指定,如驗證次數,訓練集測試集劃分比例等
kf = KFold(n_splits=5, random_state=1)
loo = LeaveOneOut()#將資料集分成訓練集和測試集,測試集包含一個樣本,訓練集包含n-1個樣本
lpo = LeavePOut(p=2000)## #將資料集分成訓練集和測試集,測試集包含p個樣本,訓練集包含n-p個樣本
ss= ShuffleSplit(n_splits=5, test_size=.25, random_state=0)
## ShuffleSplit 咋一看用法跟LeavePOut 很像,其實兩者完全不一樣,LeavePOut 是使得資料集經過數次分割後,所有的測試集出現的
##元素的集合即是完整的資料集,即無放回的抽樣,而ShuffleSplit 則是有放回的抽樣,只能說經過一個足夠大的抽樣次數後,保證測試集出
##現了完成的資料集的倍數。
tss = TimeSeriesSplit(n_splits=5)# 針對時間序列的處理,防止未來資料的使用,分割時是將資料進行從前到後切割(這個說法其實不太恰當,因為切割是延續性的。。)
3.3 下面的幾種分組的交叉驗證方式還沒弄懂 (具體是怎麼分組的)
logo = LeaveOneGroupOut()# 這個是在GroupKFold 上的基礎上混亂度又減小了,按照給定的分組方式將測試集分割下來。
lpgo = LeavePGroupsOut(n_groups=3)# 跟LeaveOneGroupOut一樣,只是一個是單組,一個是多組
gss = GroupShuffleSplit(n_splits=5, test_size=.2, random_state=0)# 這個是有放回抽樣
skf = StratifiedKFold(n_splits=3)#通過指定分組,對測試集進行無放回抽樣。【指定分組具體是怎麼指定的????】
gkf = GroupKFold(n_splits=2)# 這個跟StratifiedKFold 比較像,不過測試集是按照一定分組進行打亂的, 即先分堆,然後把這些堆打亂,每個堆裡的順序還是固定不變的。
3.4 實驗程式碼
#!/usr/bin/env python 3.6
#-*- coding:utf-8 -*-
# @File : CV1.py
# @Date : 2018-11-22
# @Author : 黑桃
# @Software: PyCharm
from pandas import Series, DataFrame
import pickle
from sklearn import svm
from sklearn.model_selection import * #劃分資料 交叉驗證
from sklearn.metrics import accuracy_score, recall_score, f1_score, roc_auc_score, roc_curve
import warnings
warnings.filterwarnings("ignore")
path = "E:/MyPython/Machine_learning_GoGoGo/"
"""=====================================================================================================================
1 讀取資料
"""
print("0 讀取特徵")
f = open(path + 'feature/feature_V3.pkl', 'rb')
train, test, y_train,y_test = pickle.load(f)
f.close()
"""=====================================================================================================================
2 進行K次訓練;用K個模型分別對測試集進行預測,並得到K個結果,再進行結果的融合
"""
preds = []
i = 0
"""=====================================================================================================================
3 交叉驗證方式
"""
## 對交叉驗證方式進行指定,如驗證次數,訓練集測試集劃分比例等
kf = KFold(n_splits=5, random_state=1)
loo = LeaveOneOut()#將資料集分成訓練集和測試集,測試集包含一個樣本,訓練集包含n-1個樣本
lpo = LeavePOut(p=2000)## #將資料集分成訓練集和測試集,測試集包含p個樣本,訓練集包含n-p個樣本
ss= ShuffleSplit(n_splits=5, test_size=.25, random_state=0)
tss = TimeSeriesSplit(n_splits=5)
logo = LeaveOneGroupOut()
lpgo = LeavePGroupsOut(n_groups=3)
gss = GroupShuffleSplit(n_splits=4, test_size=.5, random_state=0)
gkf = GroupKFold(n_splits=2)
"""【配置交叉驗證方式】"""
cv=ss
clf = svm.SVC(kernel='linear', C=1)
score_sum = 0
# 原始資料的索引不是從0開始的,因此重置索引
y_train = y_train.reset_index(drop=True)
y_test = y_test.reset_index(drop=True)
for train_idx, vali_idx in cv.split(train, y_train):
i += 1
"""獲取訓練集和驗證集"""
f_train_x = DataFrame(train[train_idx])
f_train_y = DataFrame(y_train[train_idx])
f_vali_x = DataFrame(train[vali_idx])
f_vali_y = DataFrame(y_train[vali_idx])
"""訓練分類器"""
classifier = svm.LinearSVC()
classifier.fit(f_train_x, f_train_y)
"""對測試集進行預測"""
y_test = classifier.predict(test)
preds.append(y_test)
"""對驗證集進行預測,並計算f1分數"""
pre_vali = classifier.predict(f_vali_x)
score_vali = f1_score(y_true=f_vali_y, y_pred=pre_vali, average='macro')
print("第{}折, 驗證集分數:{}".format(i, score_vali))
score_sum += score_vali
score_mean = score_sum / i
print("第{}折後, 驗證集分平均分數:{}".format(i, score_mean))
4. 網格搜尋+交叉驗證調參(直接調包實現)
4.1 實驗程式碼
#!/usr/bin/env python 3.6
#-*- coding:utf-8 -*-
# @File : GrideSearchCV.py
# @Date : 2018-11-23
# @Author : 黑桃
# @Software: PyCharm
import numpy as np
import pickle
from sklearn.tree import DecisionTreeClassifier
from xgboost.sklearn import XGBClassifier
from sklearn import svm
import lightgbm as lgb
from sklearn.model_selection import *
import warnings
warnings.filterwarnings("ignore")
# iris = load_iris()
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LogisticRegression
path = "E:/MyPython/Machine_learning_GoGoGo/"
"""=====================================================================================================================
1 讀取資料
"""
print("0 讀取特徵")
f = open(path + 'feature/feature_V3.pkl', 'rb')
X_train,X_test,y_train,y_test = pickle.load(f)
f.close()
"""
3.1 交叉驗證方式
"""
## 對交叉驗證方式進行指定,如驗證次數,訓練集測試集劃分比例等
kf = KFold(n_splits=5, random_state=1)
loo = LeaveOneOut()#將資料集分成訓練集和測試集,測試集包含一個樣本,訓練集包含n-1個樣本
lpo = LeavePOut(p=2000)## #將資料集分成訓練集和測試集,測試集包含p個樣本,訓練集包含n-p個樣本
ss= ShuffleSplit(n_splits=5, test_size=.25, random_state=0)
tss = TimeSeriesSplit(n_splits=5)
## 下面的幾種分組的交叉驗證方式還沒弄懂
logo = LeaveOneGroupOut()
lpgo = LeavePGroupsOut(n_groups=3)
gss = GroupShuffleSplit(n_splits=5, test_size=.2, random_state=0)
gkf = GroupKFold(n_splits=2)
"""=====================================================================================================================
2 模型引數設定
"""
"""【SVM】"""
SVM_linear = svm.SVC(kernel = 'linear', probability=True)
SVM_poly = svm.SVC(kernel = 'poly', probability=True)
SVM_rbf = svm.SVC(kernel = 'rbf',probability=True)
SVM_sigmoid = svm.SVC(kernel = 'sigmoid',probability=True)
SVM_param_grid = {"C":[0.001,0.01,0.1,1,10,100]}
"""【LG】"""
LG = LogisticRegression()
LG_param_grid = {"C":[0.001,0.01,0.1,1,10,100]}
"""【DT】"""
DT = DecisionTreeClassifier()
DT_param_grid = {'max_depth':range(1,5)}
params = {'max_depth':range(1,21),'criterion':np.array(['entropy','gini'])}
"""【XGB_sklearn】"""
# XGB_sklearn = XGBClassifier(n_estimators=30,#三十棵樹
# learning_rate =0.3,
# max_depth=3,
# min_child_weight=1,
# gamma=0.3,
# subsample=0.8,
# colsample_bytree=0.8,
# objective= 'binary:logistic',
# nthread=12,
# scale_pos_weight=1,
# reg_lambda=1,
# seed=27)
XGB_sklearn = XGBClassifier()
XGB_sklearn_param_grid = {"max_depth":[1,10,100]}
# param_test4 = {
# 'min_child_weight':[6,8,10,12],
# 'gamma':[i/10.0 for i in range(0,5)],
# 'subsample':[i/10.0 for i in range(6,10)],
# 'colsample_bytree':[i/10.0 for i in range(6,10)],
# 'reg_alpha': [1e-5, 1e-2, 0.1, 1, 100]
# }
"""【LGB_sklearn】"""
LGB_sklearn = lgb.LGBMClassifier()
# LGB_sklearn = lgb.LGBMClassifier(learning_rate=0.1,
# max_bin=150,
# num_leaves=32,
# max_depth=11,
# reg_alpha=0.1,
# reg_lambda=0.2,
# # objective='multiclass',
# n_estimators=300,)
LGB_sklearn_param_grid = {"max_depth":[1,10,100]}
def GridSearch(clf,param_grid,cv,name):
grid_search = GridSearchCV(clf,param_grid,cv=cv) #例項化一個GridSearchCV類
grid_search.fit(X_train,y_train) #訓練,找到最優的引數,同時使用最優的引數例項化一個新的SVC estimator。
print(name+"_Test set score:{}".format(grid_search.score(X_test,y_test)))
print(name+"_Best parameters:{}".format(grid_search.best_params_))
print(name+"_Best score on train set:{}".format(grid_search.best_score_))
GridSearch(LGB_sklearn,LGB_sklearn_param_grid,kf,"LGB_sklearn")
GridSearch(LG,LG_param_grid,kf,"LG")
GridSearch(SVM_linear,SVM_param_grid,kf,"SVM_linear")
GridSearch(DT,DT_param_grid,kf,"DT")
GridSearch(XGB_sklearn,XGB_sklearn_param_grid,kf,"XGB_sklearn")
GridSearch(SVM_rbf,SVM_param_grid,kf,"SVM_rbf")
GridSearch(SVM_sigmoid,SVM_param_grid,kf,"SVM_sigmoid")
GridSearch(SVM_poly,SVM_param_grid,kf,"SVM_poly")
4.2 實驗結果
| 模型 | 交叉驗證方式 | 網格搜尋引數 | 最優引數 | 訓練集最優評分 | 測試集最優評分 |
|---|---|---|---|---|---|
| LGB_sklearn | kf | LGB_sklearn_param_grid = {“max_depth”:[1,10,100]} | {‘max_depth’: 1} | 0.7915848527349229 | 0.7863751051303617 |
| SVM_linear | kf | SVM_param_grid = {“C”:[0.001,0.01,0.1,1,10,100]} | {‘C’: 10} | 0.7870967741935484 | 0.7922624053826746 |
| SVM_poly | kf | SVM_param_grid = {“C”:[0.001,0.01,0.1,1,10,100]} | {‘C’: 100} | 0.7573632538569425 | 0.7485281749369218 |
| SVM_rbf | kf | SVM_param_grid = {“C”:[0.001,0.01,0.1,1,10,100]} | {‘C’: 100} | 0.7876577840112202 | 0.7855340622371741 |
| SVM_sigmoid | kf | SVM_param_grid = {“C”:[0.001,0.01,0.1,1,10,100]} | {‘C’: 100} | 0.7856942496493688 | 0.7729184188393609 |
| DT | kf | DT_param_grid = {‘max_depth’:range(1,5)} | {‘max_depth’: 4} | 0.7685834502103787 | 0.7729184188393609 |
| LG | kf | LG_param_grid = {“C”:[0.001,0.01,0.1,1,10,100]} | {‘C’: 1} | 0.7929873772791024 | 0.7973086627417998 |
| XGB_sklearn | kf | XGB_sklearn_param_grid = {“max_depth”:[1,10,100]} | {‘max_depth’: 100} | 0.7921458625525947 | 0.7914213624894869 |
5. 參考資料
模型的選擇與調優:交叉驗證與網格搜尋
Machine Learning-模型評估與調參 ——K折交叉驗證
sklearn中的交叉驗證(Cross-Validation)
Grid Search 網格搜尋