
Spark執行原理和RDD解密
1.實戰解析Spark執行原理
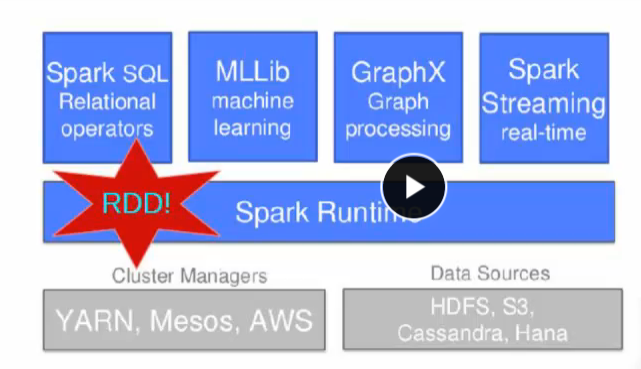
互動式查詢(shell,sql)
批處理(機器學習,圖計算)
首先,spark是基於記憶體的分散式高效計算框架,採用一棧式管理機制,同時支援流處理,實時互動式出,批處理三種方式,Spark特別支援迭代式計算,因此,他對機器學習,圖計算具有較強的支援,為此他提供了機器學習和圖計算介面。
(1)分散式:Distributed Computation
分散式多臺機器執行 特徵:
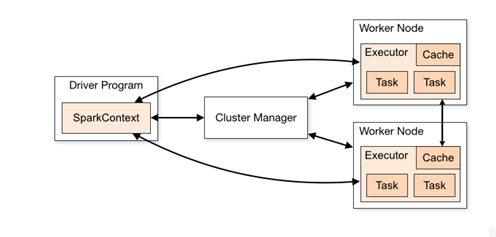
整個Spark有個提交程式的客戶端,提交給叢集,叢集中中有很多臺機器,作業執行在分散式節點上的,Spark程式提交到叢集執行,節點一般處理一部分資料,分散式作並行化,
客戶端->叢集節點
圖書館管理員查詢圖書,館長Cluster manager,1000個人,分散式計算,每個書架總數多少,分散式用到平行計算
先有叢集資源管理服務(Cluster Manager)和執行作業任務的結點(Worker Node),然後就是每個應用的任務控制結點Driver和每個機器節點上有具體任務的執行程序(Executor);Executor有二個優點:一個是多執行緒來執行具體的任務,而不是像MR那樣採用程序模型,減少了任務的啟動開稍。二個是Executor上會有一個BlockManager儲存模組,類似於KV系統(記憶體和磁碟共同作為儲存裝置),當需要迭代多輪時,可以將中間過程的資料先放到這個儲存系統上,下次需要時直接讀該儲存上資料,而不需要讀寫到hdfs等相關的檔案系統裡,或者在互動式查詢場景下,事先將表Cache到該儲存系統上,提高讀寫IO效能。另外Spark在做Shuffle時,在Groupby,Join等場景下去掉了不必要的Sort操作,相比於MapReduce只有Map和Reduce二種模式,Spark還提供了更加豐富全面的運算操作如filter,groupby,join等。
(2)基於記憶體
Spark能有效利用記憶體
300萬條資料,1,2,3機器分別算100萬條資料,資料首先考慮Memory,若只能放50萬條,另外50萬條磁碟,儘量放記憶體(速度很快)
(3) 擅長迭代式計算,是Spark的真正精髓
第一個階段計算-》第二個階段計算-》第三個階段計算
計算之後可以把結果移到另一臺機器——shuffle,從一個節點移到另一個節點。
Hadoop Map+Reduce兩階段(每次都要讀寫磁碟)
Spark可以在第一個階段後還有很多階段(迭代式)更加靈活(每次計算結果優先考慮放記憶體,下個階段可以讀記憶體中資料)
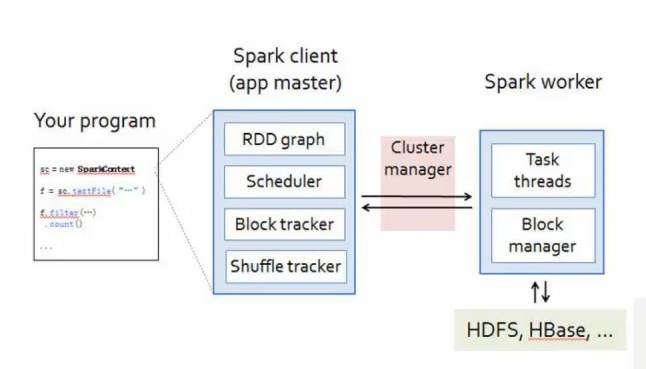
Spark排程器DAG Schedule Lineage
為什麼還是很多公司使用Java語言開發Spark?
1. 人才問題
2. 整合更加容易,J2EE做前端程式的很多
3. 維護更加容易
Spark SQL只能取代Hive的計算引擎,不能取代Hive的資料儲存
在driver上驅動程式執行,執行在worker上
處理資料來源:HDFS、HBase、Hive、DB、S3(Amazon S3,全名為亞馬遜簡易儲存服務(Amazon Simple Storage Service),由亞馬遜公司,利用他們的亞馬遜網路服務系統所提供的網路線上儲存服務)
處理資料輸出:HDFS、HBase、Hive、DB、S3,或返回driver(也就是程式本身)
2.RDD解密
通用的分散式彈性資料集
RDD是Spark的核心
RDD代表要處理的資料,處理的時候是分散式的
(1)一系列分片,在節點中儲存,記憶體中,記憶體中放不下資料,將一部分資料放在磁碟上,自動在記憶體和磁碟中切換(彈性之一)
(2)第900個出錯,一共1000個任務,可以從第900個重新計算,無需從頭開始進行計算,提高錯誤恢復速度
(3)Task1000個計算步驟,第900個進行恢復,失敗3-5次,預設4次
(4)Task失敗,整個階段失敗,再次提交Stage,1000000-5個不會提交,只提交失敗的5個Task(預設3次)
彈性之一:自動的進行記憶體和磁碟資料儲存的切換
彈性之二:基於Lineage的高校容錯
彈性之三:Task如果失敗會自動進行特定次數的重試
彈性之四:Stage如果失敗會自動進行特定次數的重試
快取時機:
1.計算任務特別耗時
2.計算鏈條很長(計算代價)1000個,第900個恢復
3.Shuffle之後,進行快取,失敗之後,不需要進行重新Shuffle(從其他地方抽取資料)
4.CheckPoint把資料整個放入磁碟,CheckPoint之前步驟無需重新計算
RDD是一系列資料分片,資料分片分佈在不同機器的不同節點上,按partition進行管理,partition就是一個數據集合 RDD包含函式的計算
最常用的RDD在Hadoop上
啟動檔案系統

啟動Spark


叢集唯一的介面:SparkContext ,SparkContext是一切工作都要經過的地方,SparkContext建立RDD

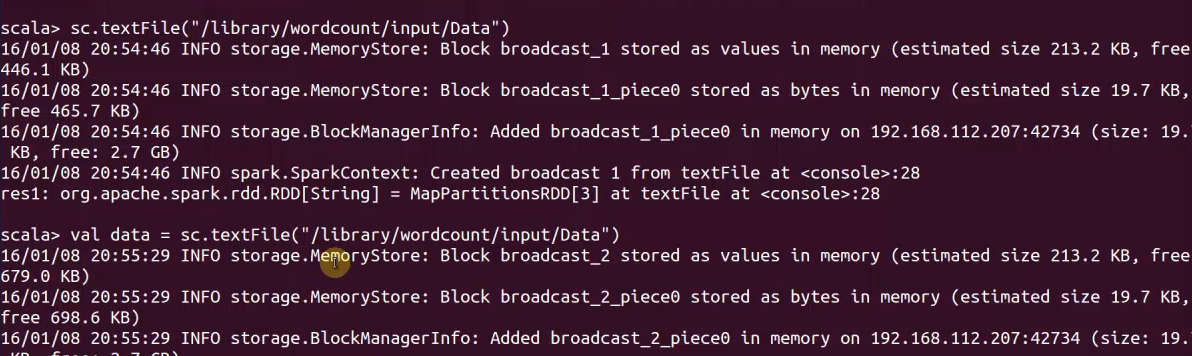
自動獲取,是本地還是叢集
spark一切操作皆RDD,每次操作都會產生RDD

data.textFile
是lazy的,transformation,不執行
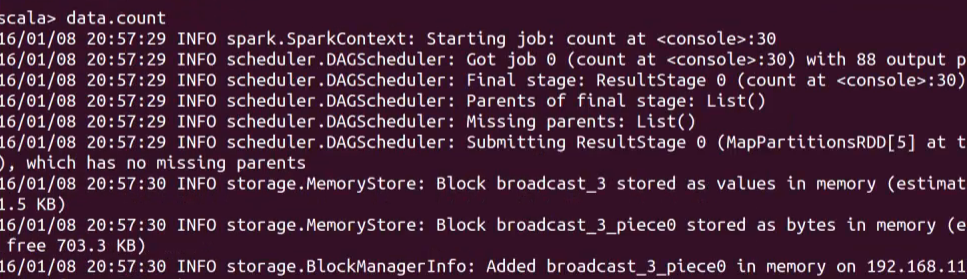
data.count
是action,所以會執行
hdfs分片和spark rdd的分割槽有什麼關係?
spark讀取資料時,RDD相當於HDFS的一個Block,Partion size=Block Size(128M)最後一條記錄跨兩個Block,128M左右
分割槽,可以進行hash,Range等等,不同分割槽策略

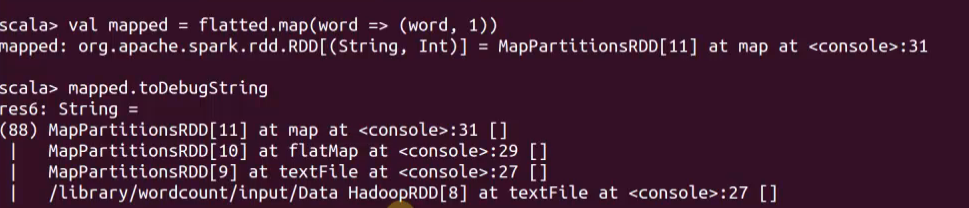
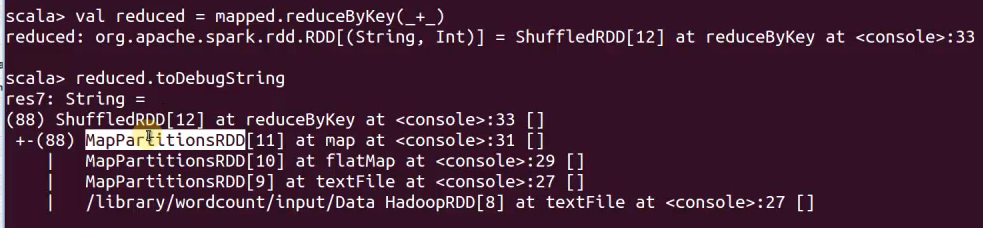
Reduce後進行shuffle

傳入HDFS

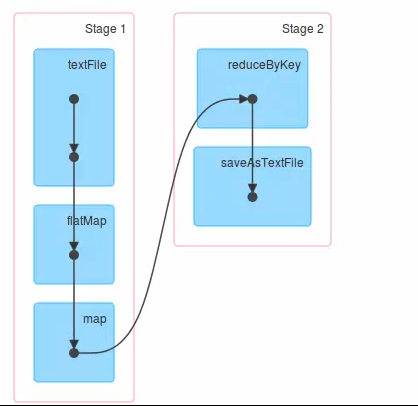
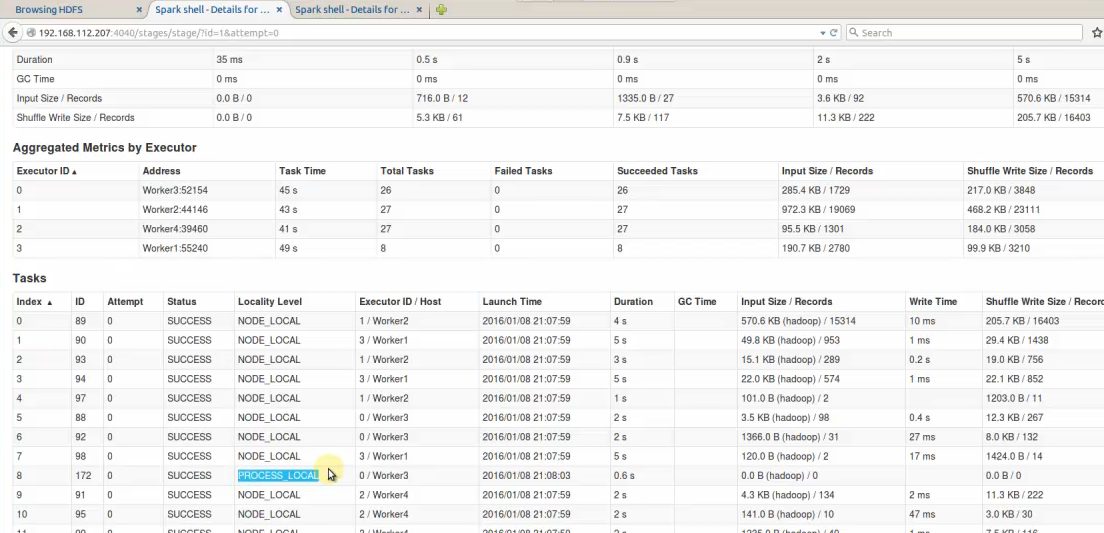
Any shuffle後的資料
Process _LOCAL
Cloudera Manager 中Spark不是最新版本的,而且不能手動更新,(開發商提供,不推薦),不推薦使用(懶人)
Spark+Tachyon+HDFS,將來是黃金組合
相關推薦
第7課:實戰解析spark執行原理和rdd解密
1.spark執行優勢 善於使用記憶體,磁碟,迭代式計算是其核心 2.現在為什麼很多公司都是使用java開發spark a.scala高手較少,java高手較多 b.專案對接比較容易 c.系統運維方便 3.spark只能取代hive的儲存引擎,不能取代hive的數倉部分 4.資料輸
Spark執行原理和RDD解密
1.實戰解析Spark執行原理 互動式查詢(shell,sql) 批處理(機器學習,圖計算) 首先,spark是基於記憶體的分散式高效計算框架,採用一棧式管理機制,同時支援流處理,實時互動式出,批處理三種方式,Spark特別支援迭代式計算,因此,他對機器學
Spark Shuffle原理和Shuffle的問題解決和優化
摘要: 1 shuffle原理 1.1 mapreduce的shuffle原理 1.1.1 map task端操作 1.1.2 reduce task端操作 1.2 spark現在的SortShuffleManager 2 Shuffle操作
Java中的instanceof運算子的執行原理和使用參考 Java中的instanceof運算子的執行原理和使用參考
原 Java中的instanceof運算子的執行原理和使用參考 2017年11月13日 09:28:34 boker_han 閱讀數:894
(轉)Spark核心技術原理透視一(Spark執行原理)
Spark核心技術原理透視一(Spark執行原理) 在大資料領域,只有深挖資料科學領域,走在學術前沿,才能在底層演算法和模型方面走在前面,從而佔據領先地位。 來源:加米穀大資料 在大資料領域,只有深挖資料科學領域,走在學術前沿,才能在底層演算法和模型方面走在前面,從而佔據領先地位。 Sp
Spark shuffle原理和詳細圖解
shuffle 中Map任務產生的結果會根據所設定的partitioner演算法填充到當前執行任務所在機器的每個桶中。 Reduce任務啟動時時,會根據任務的ID,所依賴的Map任務ID以及MapS
第72課:Spark SQL UDF和UDAF解密與實戰
內容: 1.SparkSQL UDF 2.SparkSQL UDAF 一、SparkSQL UDF和SparkSQL UDAF 1.解決SparkSQL內建函式不足問題,自定義內建函式, 2.UDF:User Define Functio
微服務:Spring Boot第二篇——執行原理和HelloWorld
這次來通過一個DEMO程式來學習Spring Boot的執行原理,參考的書為《Spring Cloud與Docker 微服務架構實戰》,採用的版本為Java 1.8,Spring Boot 1.5.6(後改為1.5.4),IDE是STS(Spring Tool Suite). 首先以網頁的形式來
Spark原始碼解析(一):Spark執行流程和指令碼
Spark執行流程Spark帶註釋原始碼對於整個Spark原始碼分析系列,我將帶有註釋的Spark原始碼和分析的檔案放在我的GitHub上Spark原始碼剖析歡迎大家fork和star過程描述:1.通過Shell指令碼啟動Master,Master類繼承Actor類,通過Ac
(八)如何理解Executors框架下的四大執行緒池執行原理和適用場景
(一)由標準執行緒池ThreadPoolExecutor演變而來的四大執行緒池 (1)FixedThreadPool是一種可重用固定執行緒數的執行緒池,阻塞佇列適用的是LinkedBlockingQueue的無界阻塞佇列,適用於需要保證所有提交的任務都要被執行的
spark的原理和部署(二)on yarn
關於spark的叢集有三種部署模式, mesos yarn standalone,對應著三種不同的資源管理方式,因為前段時間搭建了hadoop叢集,所以先來了解下 on yarn的叢集部署方式。首先啟動叢集start-all.sh測試:本地執行spark-shell程式:
JSP基本功 pageContext物件page,request,session,application四個域物件的使用及區別JSP執行原理和九大隱式物件及下載檔案、訪問次數的程式碼總結出el表示式簡單
pageContext物件 pageContext物件是JSP技術中最重要的一個物件,它代表JSP頁面的執行環境,這個物件不僅封裝了對其它8大隱式物件的引用,它自身還是一個域物件,可以用來儲存資料。並且,這個物件還封裝了web開發中經常涉及到的一些常用操作,例如引入和跳轉其它資源、檢索其
Spark分散式計算和RDD模型研究
1背景介紹現今分散式計算框架像MapReduce和Dryad都提供了高層次的原語,使使用者不用操心任務分發和錯誤容忍,非常容易地編寫出平行計算程式。然而這些框架都缺乏對分散式記憶體的抽象和支援,使其在某
Spark學習(五)---RDD原理解析和spark執行架構
這次我們介紹RDD的原理和spark執行機制 RDD依賴關係 RDD快取 RDD容錯機制 spark執行架構 spark任務排程 1. RDD原理 首先我們對之前的單詞統計的程式碼做一個畫圖展示 1.1 RDD依賴關係 RDD和它依賴的父RDD的關係有兩
Spark基本工作原理與RDD及wordcount程式例項和原理深度剖析
RDD以及其特點 1、RDD是Spark提供的核心抽象,全稱為Resillient Distributed Dataset,即彈性分散式資料集。 2、RDD在抽象上來說是一種元素集合,包含了資料。它是被分割槽的,分為多個分割槽,每個分割槽分佈在叢集中的不同節
第40課: CacheManager徹底解密:CacheManager執行原理流程圖和原始碼詳解
第40課: CacheManager徹底解密:CacheManager執行原理流程圖和原始碼詳解CacheManager管理是快取,而快取可以是基於記憶體的快取,也可以是基於磁碟的快取。CacheManager需要通過BlockManager來操作資料。 T
Struts2工作原理和執行流程圖
過濾器 map filters play servle 同時 cati 通過 spa 在struts2的應用中,從用戶請求到服務器返回相應響應給用戶端的過程中,包含了許多組件如:Controller、ActionProxy、ActionMapping、Configurati
Spark-Sql整合hive,在spark-sql命令和spark-shell命令下執行sql命令和整合調用hive
type with hql lac 命令 val driver spark集群 string 1.安裝Hive 如果想創建一個數據庫用戶,並且為數據庫賦值權限,可以參考:http://blog.csdn.net/tototuzuoquan/article/details/5
ASP.NET MVC下的異步Action的定義和執行原理
urn des {0} 不同 exce .class 遠程 是否 了解 Visual Studio提供的Controller創建向導默認為我們創建一個繼承自抽象類Controller的Controller類型,這樣的Controller只能定義同步Action方法。如果我們
JVM字節碼執行引擎和動態綁定原理
找不到 順序 入棧 兩種 運行時 mage 過程 狀態 對象 1.執行引擎 所有Java虛擬機的執行引擎都是一致的: 輸入的是字節碼文件,處理過程就是解析過程,最後輸出執行結果。 在整個過程不同的數據在不同的結構中進行處理。 2.棧幀 jvm進行方法調用和方法執行的數