
Spark shuffle原理和詳細圖解
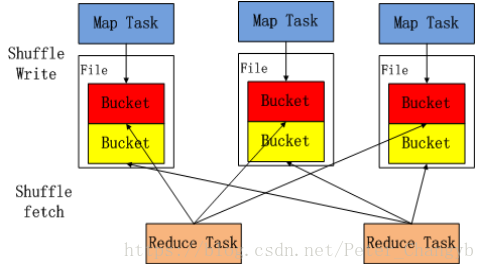
shuffle 中Map任務產生的結果會根據所設定的partitioner演算法填充到當前執行任務所在機器的每個桶中。
- Reduce任務啟動時時,會根據任務的ID,所依賴的Map任務ID以及MapStatus從遠端或本地的BlockManager獲取相應的資料作為輸入進行處理。
- Shuffle資料必須持久化磁碟,不能快取在記憶體。
Hash方式:
- shuffle不排序,效率高
- 生成MXR個shuffle中間檔案,一個分片一個檔案
- 產生和生成這些中間檔案會產生大量的隨機IO,磁碟效率低
- shuffle時需要全部資料都放在記憶體,對記憶體消耗大
- 適合資料量能全部放到記憶體,reduce操作不需要排序的場景

Sort方式:
- shuffle需要排序
- 生成M個shuffle中間資料檔案,一個Map所有分片放到一個數據檔案中,外
- 加一個索引檔案記錄每個分片在資料檔案中的偏移量
- shuffle能夠藉助磁碟(外部排序)處理龐大的資料集
- 資料量大於記憶體時只能使用Sort方式,也適用於Reduce操作需要排序的場景
相關推薦
Spark shuffle原理和詳細圖解
shuffle 中Map任務產生的結果會根據所設定的partitioner演算法填充到當前執行任務所在機器的每個桶中。 Reduce任務啟動時時,會根據任務的ID,所依賴的Map任務ID以及MapS
Spark Shuffle原理和Shuffle的問題解決和優化
摘要: 1 shuffle原理 1.1 mapreduce的shuffle原理 1.1.1 map task端操作 1.1.2 reduce task端操作 1.2 spark現在的SortShuffleManager 2 Shuffle操作
MapReduce Shuffle 和 Spark Shuffle 原理概述
Shuffle簡介 Shuffle的本意是洗牌、混洗的意思,把一組有規則的資料儘量打亂成無規則的資料。而在MapReduce中,Shuffle更像是洗牌的逆過程,指的是將map端的無規則輸出按指定的規則“打亂”成具有一定規則的資料,以便reduce端接收處理。其在MapReduce中所處的工作階段是map輸出
第7課:實戰解析spark執行原理和rdd解密
1.spark執行優勢 善於使用記憶體,磁碟,迭代式計算是其核心 2.現在為什麼很多公司都是使用java開發spark a.scala高手較少,java高手較多 b.專案對接比較容易 c.系統運維方便 3.spark只能取代hive的儲存引擎,不能取代hive的數倉部分 4.資料輸
Spark:Shuffle原理剖析與原始碼分析
spark中的Shuffle是非常重要的,shuffle不管在Hadoop中還是Spark中都是重重之重,特別是在Spark shuffle優化的時間。更是非常的重要。 普通shuffle操作的原理剖析(spark 2.x棄用) 每一個Job提交後都會生成一個ResultStage和
腦分享 | 腦結構、腦工作原理最詳細圖解
來源:深度學習進階學習社摘要:這個帖子很好地提醒了小編我,為什麼願意跟如此美麗可愛的大腦一起工作
Spark執行原理和RDD解密
1.實戰解析Spark執行原理 互動式查詢(shell,sql) 批處理(機器學習,圖計算) 首先,spark是基於記憶體的分散式高效計算框架,採用一棧式管理機制,同時支援流處理,實時互動式出,批處理三種方式,Spark特別支援迭代式計算,因此,他對機器學
spark的原理和部署(二)on yarn
關於spark的叢集有三種部署模式, mesos yarn standalone,對應著三種不同的資源管理方式,因為前段時間搭建了hadoop叢集,所以先來了解下 on yarn的叢集部署方式。首先啟動叢集start-all.sh測試:本地執行spark-shell程式:
Spark之Shuffle機制和原理
Spark Shuffle簡介 Shuffle就是對資料進行重組,由於分散式計算的特性和要求,在實現細節上更加繁瑣和複雜 在MapReduce框架,Shuffle是連線Map和Reduce之間的橋樑,Map階段通過shuffle讀取資料並輸出到對應的Reduce
spark基礎之shuffle機制和原理分析
一 概述 Shuffle就是對資料進行重組,由於分散式計算的特性和要求,在實現細節上更加繁瑣和複雜 在MapReduce框架,Shuffle是連線Map和Reduce之間的橋樑,Map階段通過shuf
HDU2665 主席樹原理解決靜態區間第K大值問題總結 有詳細圖解和程式碼解釋
鄙人不才,剛學習了一點主席樹,想自己來寫一篇關於主席樹的詳解,主要針對主席樹解決靜態(無修改)區間內第K大值的問題,可以參考HDU 2665。解決其他的問題的主席樹演算法等自己搞懂後再補上。下文如果有什麼錯誤還請指出,感激不盡! 感謝以下博文對主席樹的講解: 1.主席樹1
TCP協議的三次握手和四次揮手(詳細圖解)
TCP的概述 TCP把連線作為最基本的物件,每一條TCP連線都有兩個端點,這種斷點我們叫作套接字(socket),它的定義為埠號拼接到IP地址即構成了套接字,例如,若IP地址為192.3.4.16 而埠號為80,那麼得到的套接字為192.3.4.16:80。 T
HashMap的實現原理和底層結構 圖解+原始碼分析
雜湊表(hash table)也叫散列表,是一種非常重要的資料結構,應用場景及其豐富,許多快取技術(比如memcached)的核心其實就是在記憶體中維護一張大的雜湊表,而HashMap的實現原理也常常出現在各類的面試題中,重要性可見一斑。本文會對java集合框架中的對應實現HashMap的實現原理
利用python實現梯度下降和邏輯迴歸原理(Python詳細原始碼:預測學生是否被錄取)
本案例主要是:建立邏輯迴歸模型預測一個學生是否被大學錄取,沒有詳細介紹演算法推到, 讀者可查閱其他部落格理解梯度下降演算法的實現:https://blog.csdn.net/wangliang0633/article/details/79082901 資料格式如下:第三列表示錄取狀態,0--
spark原理和spark與mapreduce的最大區別
參考文件:https://files.cnblogs.com/files/han-guang-xue/spark1.pdf 參考網址:https://www.cnblogs.com/wangrd/p/6232826.html 對於spark個人理解: spark與mapreduce最
圖解Spark Shuffle的發展歷程
一、Spark Hash Shuffle 基於Hash的Shuffle Write操作較為簡單,這種Shuffle方式中,Shuffle Map Task會根據下游生成的Partition個數來建立中間檔案來儲存對應的Partition資料。如下圖所示,下游生
Hadoop Shuffle和Spark Shuffle的區別
一.MR的Shuffle mapShuffle 資料存到hdfs中是以塊進行儲存的,每一個塊對應一個分片,maptask就是從分片中獲取資料的 在某個節點上啟動了map Task,map Task讀取是通過k-v來讀取的,讀取的資料會放到環形快
紅黑樹 原理和演算法詳細介紹(Java)
R-B Tree簡介 R-B Tree,全稱是Red-Black Tree,又稱為“紅黑樹”,它一種特殊的二叉查詢樹。紅黑樹的每個節點上都有儲存位表示節點的顏色,可以是紅(Red)或黑(Black)。 紅黑樹的特性: (1)每個節點或者是黑色,或者是紅
紅黑樹(一)之 原理和演算法詳細介紹
概要 作者:Sky Wang 於 2013-08-08 概述:R-B Tree,又稱為“紅黑樹”。本文參考了《演算法導論》中紅黑樹相關知識,加之自己的理解,然後以圖文的形式對紅黑樹進行說明。本文的主要內容包括:紅黑樹
IntelliJ IDEA + GitHub(git) 詳細圖解 如何實現專案的版本控制和管理(on win 7 64 bit)
在IntelliJ IDEA 編輯器裡面使用GitHub,把專案放到GitHub伺服器上,實現版本管理的目的。 具體遇到並解決了下面問題。1."Cannot run program "git.exe": CreateProcess error=2, 系統找不到指定的檔案