
425. Word Squares -- back tracking + trie tree(TLE if not)
阿新 • • 發佈:2018-11-21
給你一個字元陣列,每個單詞長度一樣,你從中選單詞,組成的 二位陣列中 橫向和縱向 組成的一維陣列都一樣。
注意1: 單詞可以重複被選擇
注意2. 字串陣列可能非常的大,有1000 個
Input:
["area","lead","wall","lady","ball"]
Output:
[
[ "wall",
"area",
"lead",
"lady"
],
[ "ball",
"area",
"lead",
"lady"
]
]
分析一: 既然單詞可以重複,那就是一個組合問題,每個節點上的下一個節點都可以分解成 數組裡全部元素, 如果單詞長度為5, array 裡有1000個單詞,那麼 最後一層就有 1000^5個節點,很容易TLE。 dfs 樹為: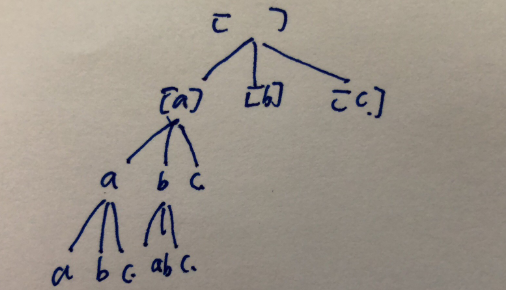
分析二: 假設單詞當都為5, 第一個單詞任意放, 第二個單詞首字母 [1][0]位置 會被 第一個單詞 [0][1] 位置所決定。
第三個word 前兩個字母, [2][0], [2][1] 會被 [0][2],[1][2] 位置所決定, 以此內推。
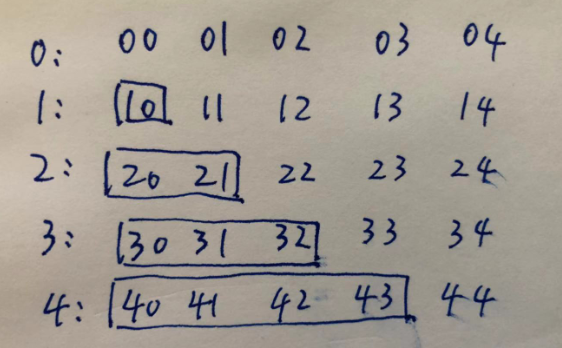
針對這個特性,可以有兩個方案:
1. 在普通dfs 中, 放 第 i個word 時, 先判斷 前 i-1個letters 是否合法,不合法則不放。
2. 用Trie , 每次主動選prefix 滿足條件的單詞來構建。比如構建 第3個單詞時, 得看 20,21 位置作為prefix 來主動選擇單詞。
對於方案一,程式碼很容易,但當 array 裡面數量很大,因為著每一層節點都很多時,會TLE, code 如下: 15/16, 16個tests 過了15個,最後一個會TLE。
class Solution { public List<List<String>> wordSquares(String[] words) { List<List<String>> result = new ArrayList<>(); dfs(newArrayList<>(), result, words); return result; } private void dfs(List<String> curResult, List<List<String>> result, String[] words){ if(curResult.size() == words[0].length()){ result.add(new ArrayList<>(curResult)); return; } //if(depth >= words[0].length()) return; for(int i=0; i<words.length; i++){ if(!validPut(curResult,words[i])) continue; dfs(curResult,result,words); curResult.remove(curResult.size()-1); } } private boolean validPut(List<String> curResult, String word){ int size = curResult.size(); for(int i=0; i<size; i++){ if(word.charAt(i) != curResult.get(i).charAt(size) ) return false; } curResult.add(word); // System.out.println(curResult); return true; } }
為了不TLE, 只能選擇用 Trie Tree 主動選擇 構建 每層節點,這樣隨著層數的增加 越到後面節點越少。