
決策樹-剪枝演算法(二)
ID3演算法的的原理,它是以資訊熵為度量,用於決策樹節點的屬性選擇,每次優選資訊量最多
的屬性,以構造一顆熵值下降最快的決策樹,到葉子節點處的熵值為0,此時每個葉子節點對應的例項集中的例項屬於同一類。
理想的決策樹有三種:
1.葉子節點數最少
2.葉子加點深度最小
3.葉子節點數最少且葉子節點深度最小。
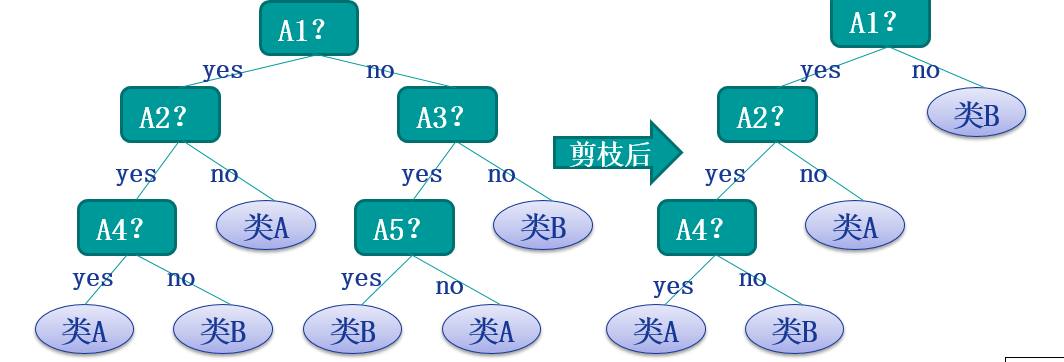
在實際的操作中還會設計到ID3演算法的收斂,過度擬合等問題下面依次進行描述
1.ID演算法收斂
2.過度擬合問題
1.ID3演算法的收斂
當ID3確定根節點以及後續節點之後,因此當演算法滿足以下條件該分支的既可以結束
1.該群資料的每一個數據都已經歸類到同一類別中
2.該群資料已經沒有辦法找到新的屬性進行節點分割
3.該群資料已經沒有任何尚未處理的資料。
2.過度擬合問題
原因:
造成多度擬合的潛在原因主要以下兩個方面
1.噪聲導致的過度擬合
比如錯誤的分類,或者屬性值。
2.缺乏代表性樣本所導致的過度擬合
方法:
1.預剪枝
通過提前停止樹的構建而對樹剪枝,一旦停止,節點就是樹葉,該樹葉持有子集元祖最頻繁的類。
停止決策樹生長最簡單的方法有:
1.定義一個高度,當決策樹達到該高度時就停止決策樹的生長
2.達到某個節點的例項具有相同的特徵向量,及時這些例項不屬於同一類,也可以停止決策樹的生長。這個方法對於處理
資料的資料衝突問題比較有效。
3.定義一個閾值,當達到某個節點的例項個數小於閾值時就可以停止決策樹的生長
4.定義一個閾值,通過計算每次擴張對系統性能的增益,並比較增益值與該閾值大小來決定是否停止決策樹的生長。
2.後剪枝方法
後剪枝(postpruning):它首先構造完整的決策樹,允許樹過度擬合訓練資料,然後對那些置信度不夠的結點子樹用葉子結點來代替,該葉子的類標號用該結點子樹中最頻繁的類標記。相比於先剪枝,這種方法更常用,正是因為在先剪枝方法中精確地估計何時停止樹增長很困難。
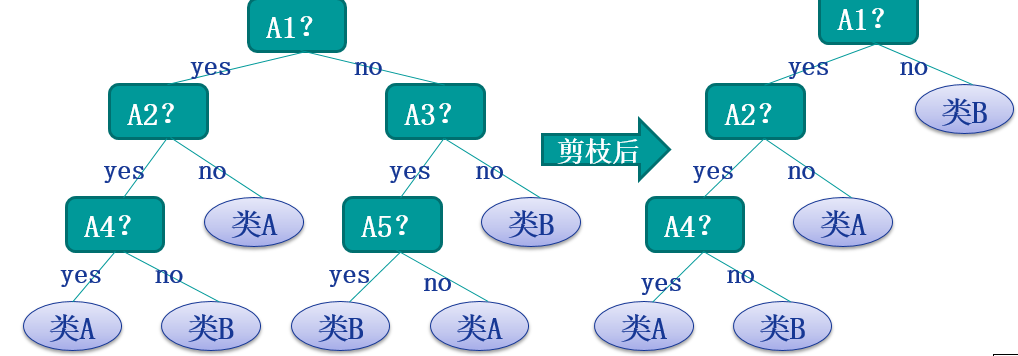
以上可以理解為後剪枝的基本思想,其中後剪枝方法主要有以下幾個方法:
Reduced-Error Pruning(REP,錯誤率降低剪枝)
Pesimistic-Error Pruning(PEP,悲觀錯誤剪枝)
Cost-Complexity Pruning(CCP,代價複雜度剪枝)
EBP(Error-Based Pruning)(基於錯誤的剪枝)
以下分別進行說明:
1.REP
REP方法是一種比較簡單的後剪枝的方法,在該方法中,可用的資料被分成兩個樣例集合:一個訓練集用來形成學習到的決策樹,一個分離的驗證集用來評估這個決策樹在後續資料上的精度,確切地說是用來評估修剪這個決策樹的影響。
這個方法的動機是:即使學習器可能會被訓練集中的隨機錯誤和巧合規律所誤導,但驗證集合不大可能表現出同樣的隨機波動。所以驗證集可以用來對過度擬合訓練集中的虛假特徵提供防護檢驗。
該剪枝方法考慮將書上的每個節點作為修剪的候選物件,決定是否修剪這個結點有如下步驟組成:
1:刪除以此結點為根的子樹
2:使其成為葉子結點
3:賦予該結點關聯的訓練資料的最常見分類
4:當修剪後的樹對於驗證集合的效能不會比原來的樹差時,才真正刪除該結點
因為訓練集合的過擬合,使得驗證集合資料能夠對其進行修正,反覆進行上面的操作,從底向上的處理結點,刪除那些能夠最大限度的提高驗證集合的精度的結點,直到進一步修剪有害為止(有害是指修剪會減低驗證集合的精度)。
REP是最簡單的後剪枝方法之一,不過由於使用獨立的測試集,原始決策樹相比,修改後的決策樹可能偏向於過度修剪。這是因為一些不會再測試集中出現的很稀少的訓練集例項所對應的分枝在剪枝過如果訓練集較小,通常不考慮採用REP演算法。
儘管REP有這個缺點,不過REP仍然作為一種基準來評價其它剪枝演算法的效能。它對於兩階段決策樹學習方法的優點和缺點提供了了一個很好的學習思路。由於驗證集合沒有參與決策樹的建立,所以用REP剪枝後的決策樹對於測試樣例的偏差要好很多,能夠解決一定程度的過擬合問題。
2.PEP
悲觀錯誤剪枝法是根據剪枝前後的錯誤率來判定子樹的修剪。該方法引入了統計學上連續修正的概念彌補REP中的缺陷,在評價子樹的訓練錯誤公式中添加了一個常數,假定每個葉子結點都自動對例項的某個部分進行錯誤的分類。
把一顆子樹(具有多個葉子節點)的分類用一個葉子節點來替代的話,在訓練集上的誤判率肯定是上升的,但是在新資料上不一定。於是我們需要把子樹的誤判計算加上一個經驗性的懲罰因子。對於一顆葉子節點,它覆蓋了N個樣本,其中有E個錯誤,那麼該葉子節點的錯誤率為(E+0.5)/N。這個0.5就是懲罰因子,那麼一顆子樹,它有L個葉子節點,那麼該子樹的誤判率估計為:
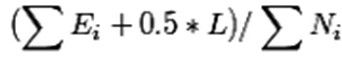
這樣的話,我們可以看到一顆子樹雖然具有多個子節點,但由於加上了懲罰因子,所以子樹的誤判率計算未必佔到便宜。剪枝後內部節點變成了葉子節點,其誤判個數J也需要加上一個懲罰因子,變成J+0.5。那麼子樹是否可以被剪枝就取決於剪枝後的錯誤J+0.5在的標準誤差內。對於樣本的誤差率e,我們可以根據經驗把它估計成各種各樣的分佈模型,比如是二項式分佈,比如是正態分佈。
那麼一棵樹錯誤分類一個樣本值為1,正確分類一個樣本值為0,該樹錯誤分類的概率(誤判率)為e(e為分佈的固有屬性,可以通過統計出來),那麼樹的誤判次數就是伯努利分佈,我們可以估計出該樹的誤判次數均值和標準差:
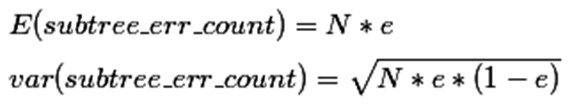
把子樹替換成葉子節點後,該葉子的誤判次數也是一個伯努利分佈,其概率誤判率e為(E+0.5)/N,因此葉子節點的誤判次數均值為
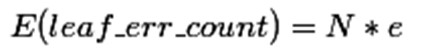
使用訓練資料,子樹總是比替換為一個葉節點後產生的誤差小,但是使用校正後有誤差計算方法卻並非如此,當子樹的誤判個數大過對應葉節點的誤判個數一個標準差之後,就決定剪枝:
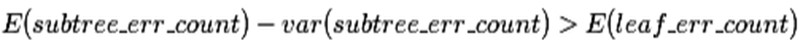
這個條件就是剪枝的標準。當然並不一定非要大一個標準差,可以給定任意的置信區間,我們設定一定的顯著性因子,就可以估算出誤判次數的上下界。
話不多說,上例子:
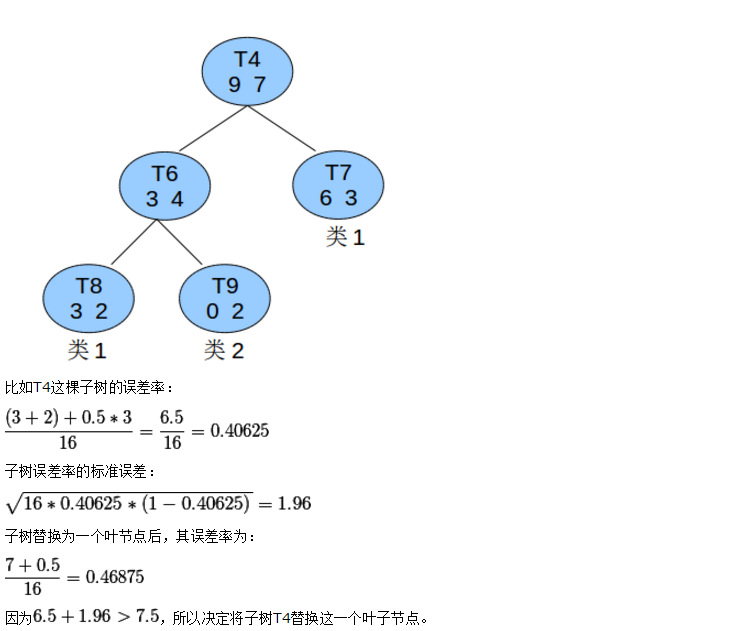
在上述例子中T8種的類1可以認為是識別錯誤的T4這課子樹的估計錯誤為5,T4子樹的最後葉子節點為3個
上述是悲觀錯誤剪枝。
悲觀剪枝的準確度比較高,但是依舊會存在以下的問題:
1.PeP演算法實用的從從上而下的剪枝策略,這種剪枝會導致和預剪枝同樣的問題,造成剪枝過度。
2.Pep剪枝會出現剪枝失敗的情況。d
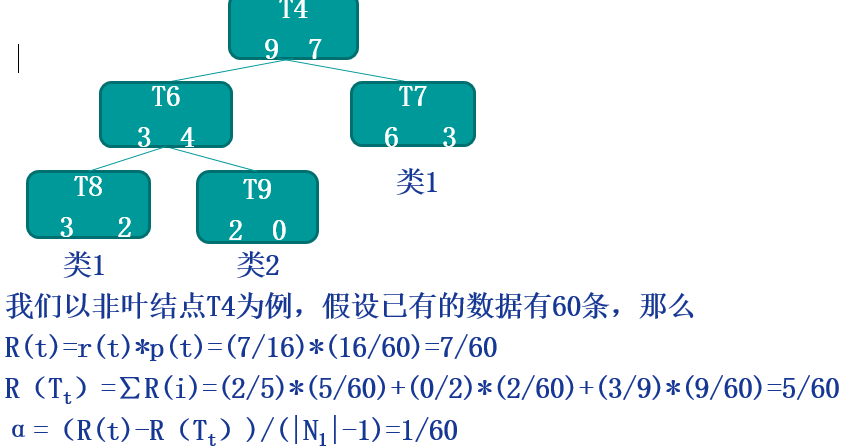
代價複雜度剪枝:
該演算法為子樹Tt定義了代價(cost)和複雜度(complexity),以及一個可由使用者設定的衡量代價與複雜度之間關係的引數α,其中,代價指在剪枝過程中因子樹Tt被葉節點替代而增加的錯分樣本,複雜度表示剪枝後子樹Tt減少的葉結點數,α則表示剪枝後樹的複雜度降低程度與代價間的關係,定義為:
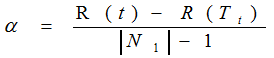
其中,
|N1|:子樹Tt中的葉節點數;
R(t):結點t的錯誤代價,計算公式為R(t)=r(t)*p(t),
r(t)為結點t的錯分樣本率,p(t)為落入結點t的樣本佔所有樣本的比例;
R(Tt):子樹Tt錯誤代價,計算公式為R(Tt)=∑R(i),i為子樹Tt的葉節點。
CCP剪枝演算法分為兩個步驟:
1.對於完全決策樹T的每個非葉結點計算α值,迴圈剪掉具有最小α值的子樹,直到剩下根節點。在該步可得到一系列的剪枝樹{T0,T1,T2......Tm},其中T0為原有的完全決策樹,Tm為根結點,Ti+1為對Ti進行剪枝的結果;
2.從子樹序列中,根據真實的誤差估計選擇最佳決策樹。
上例子:
EBP:
•第一步:計算葉節點的錯分樣本率估計的置信區間上限U •第二步:計算葉節點的預測錯分樣本數 –葉節點的預測錯分樣本數=到達該葉節點的樣本數*該葉節點的預測錯分樣本率U •第三步:判斷是否剪枝及如何剪枝 –分別計算三種預測錯分樣本數: •計運算元樹t的所有葉節點預測錯分樣本數之和,記為E1 •計運算元樹t被剪枝以葉節點代替時的預測錯分樣本數,記為E2 •計運算元樹t的最大分枝的預測錯分樣本數,記為E3 –比較E1,E2,E3,如下: •E1最小時,不剪枝 •E2最小時,進行剪枝,以一個葉節點代替t •E3最小時,採用“嫁接”(grafting)策略,即用這個最大分枝代替t 其演算法的具體過程可以參考附件以下是幾種剪枝的方法的比較:
| REP | PEP | CCP | |
| 剪枝方式 | 自底向上 | 自頂向下 | 自底向上 |
| 計算複雜度 | 0(n) | o(n) | o(n2) |
| 誤差估計 | 剪枝集上誤差估計 | 使用連續糾正 | 標準誤差 |