
使用Java呼叫Stanford CoreNLP 進行中文分詞
阿新 • • 發佈:2018-11-21
Stanford CoreNLP 進行中文分詞
中文分詞的工具有很多,使用斯坦福的CoreNLP進行分詞的教程網上也不少,本篇部落格是記錄自己在使用Stanford CoreNLP進行中文分詞的學習筆記。
1. 工具準備
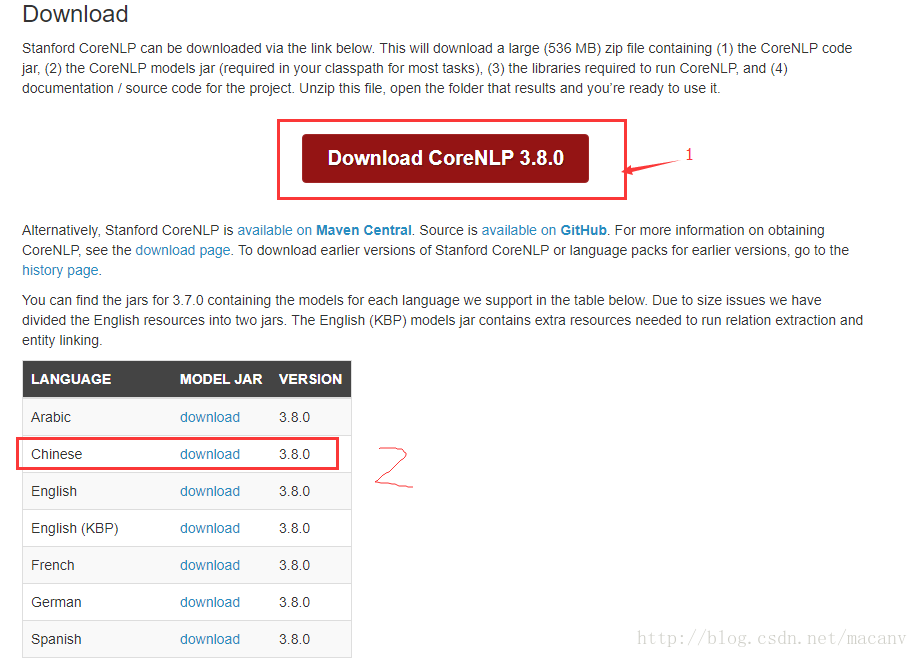
1.1 下載NLP相關包:
網址: https://stanfordnlp.github.io/CoreNLP/index.html
需要下載的包看下圖:
1.2 準備jar包
將下載下來的stanford-corenlp-full-2016-10-31解壓,在工程中匯入以下jar:
1、stanford-corenlp-full-2016-10-31/ejml-0.23.jar (斜槓前面是目錄。。。)
2、stanford-corenlp-full-2016-10-31/stanford-corenlp-3.7.0.jar
3、stanford-chinese-corenlp-2016-10-31-models.jar
2.分詞
本篇文章僅僅記錄分詞,其他的功能後續在更新,注意JDK要1.8以上。
package Seg; import edu.stanford.nlp.ling.CoreAnnotations; import edu.stanford.nlp.ling.CoreLabel; import edu.stanford.nlp.pipeline.Annotation; import edu.stanford.nlp.pipeline.StanfordCoreNLP; import edu.stanford.nlp.util.CoreMap; import edu.stanford.nlp.util.StringUtils; import java.util.List; import java.util.Properties; /** * Created by dd on 2017/6/8. * 斯坦福NLP 包,中文分詞和英文分詞 */ public class Segmentation { public void segInCh(String text){ //載入properties 檔案 // StanfordCoreNLP pipline = new StanfordCoreNLP("StanfordCoreNLP-chinese.properties"); //1.2 自定義功能 (1) // Properties properties = new Properties(); // properties.setProperty("annotators", "tokenize, ssplit, pos, lemma, ner, parse, dcoref"); // StanfordCoreNLP pipline = new StanfordCoreNLP(properties); //自定義功能(2) 自己在專案中建一個properties 檔案,然後在檔案中設定模型屬性,可以參考1中的配置檔案 String[] args = new String[] {"-props", "properies/CoreNLP-Seg-CH.properties"}; Properties properties = StringUtils.argsToProperties(args); StanfordCoreNLP pipline = new StanfordCoreNLP(properties); //自定義功能(3) /* StanfordCoreNLP pipline = new StanfordCoreNLP(PropertiesUtils.asProperties( "annotators", "tokenize,ssplit", "ssplit.isOneSentence", "true", "tokenize.language", "zh", "segment.model", "edu/stanford/nlp/models/segmenter/chinese/ctb.gz", "segment.sighanCorporaDict", "edu/stanford/nlp/models/segmenter/chinese", "segment.serDictionary", "edu/stanford/nlp/models/segmenter/chinese/dict-chris6.ser.gz", "segment.sighanPostProcessing", "true" )); */ //建立一個解析器,傳入的是需要解析的文字 Annotation annotation = new Annotation(text); //解析 pipline.annotate(annotation); //根據標點符號,進行句子的切分,每一個句子被轉化為一個CoreMap的資料結構,儲存了句子的資訊() List<CoreMap> sentences = annotation.get(CoreAnnotations.SentencesAnnotation.class); //從CoreMap 中取出CoreLabel List ,列印 for (CoreMap sentence : sentences){ for (CoreLabel token : sentence.get(CoreAnnotations.TokensAnnotation.class)){ String word = token.get(CoreAnnotations.TextAnnotation.class); System.out.println(word); } } } }
2.2 測試
String shortText = "碩士研究生產";
@Test
public void testSegCh(){
Segmentation segmentation = new Segmentation();
segmentation.segInCh(shortText);
}
2.3 執行結果

3.參考:
1: http://blog.csdn.net/churximi/article/details/51219394
2: https://blog.sectong.com/blog/corenlp_segment.html