
使用IKAnalyzer進行中文分詞
一個完整的結構如下:
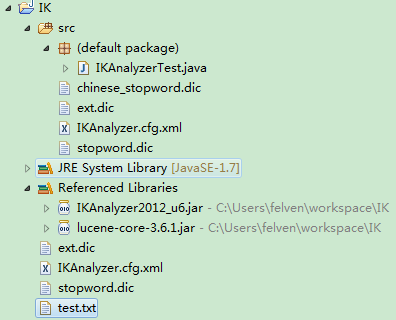
其中ext.dic和chinese_stopword.dic都是自定義的,這裡ext.dic用的是百度百科的詞條【496萬個詞條】,需要在xml裡面新增dic的位置。
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 擴充套件配置</comment> <!--使用者可以在這裡配置自己的擴充套件字典 --> 李天一,現名李冠豐。著名歌唱家李雙江和知名歌唱家夢鴿之子。根據司法機關公佈資料顯示,李天一出生於1996年4月。曾就讀北京海淀區中關村第三小學、人民大學附中、美國Shattuck-St. Mary's School(沙特克聖瑪麗學院)冰球學校。2011年9月6日,因與人鬥毆被拘留教養1年。2012年9月19日,李天一被解除教養。2013年2月22日,因涉嫌輪姦案被刑事拘留,後因可查資料顯示未成年,移交少管所。3月7日,中央電視臺新聞中心官方微博釋出了一條訊息,稱李天一因涉嫌強姦罪,已被檢察機關批捕。2013年9月,李雙江一篇舊文證實李天一成年。
測試程式如下:
import java.io.BufferedReader;import java.io.FileInputStream;import java.io.IOException;import java.io.InputStreamReader;import java.io.StringReader;import org.apache.lucene.analysis.TokenStream;import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;import org.wltea.analyzer.core.IKSegmenter;import 其中上面第一個沒有呼叫lucene庫,第二個是呼叫lucene庫進行分詞,兩者區別貌似不大。
得到結果如下:?李天一,現名李冠豐。著名歌唱家李雙江和知名歌唱家夢鴿之子。根據司法機關公佈資料顯示,李天一出生於1996年4月。曾就讀北京海淀區中關村第三小學、人民大學附中、美國Shattuck-St. Mary's School(沙特克聖瑪麗學院)冰球學校。2011年9月6日,因與人鬥毆被拘留教養1年。2012年9月19日,李天一被解除教養。2013年2月22日,因涉嫌輪姦案被刑事拘留,後因可查資料顯示未成年,移交少管所。3月7日,中央電視臺新聞中心官方微博釋出了一條訊息,稱李天一因涉嫌強姦罪,已被檢察機關批捕。2013年9月,李雙江一篇舊文證實李天一成年。啊載入擴充套件詞典:ext.dic載入擴充套件停止詞典:stopword.dic載入擴充套件停止詞典:chinese_stopword.dic李天一|現名|李冠|豐|著名|歌唱家|李雙|江和|知名|歌唱家|夢鴿|之子|根據|司法機關|公佈|資料|顯示|李天一|出生於|1996年|4月|就讀|北京|海淀區|中關村第三小學|人民大學|附中|美國|shattuck-st.|mary|s|school|沙|特克|聖瑪麗學院|冰球|學校|2011年|9月6日|與人|鬥毆|拘留|教養|1年|2012年|9月19日|李天|一被|解除|教養|2013年|2月22日|因涉嫌|輪姦案|刑事拘留|可查|資料|顯示|未成年|移交|少管所|3月7日|中央電視臺|新聞中心|官方|微博|釋出|一條|訊息|稱|李天一|因涉嫌|強姦罪|已被|檢察機關|批捕|2013年|9月|李雙江|一篇|舊文|證實|李天一|成年|李天一|現名|李冠|豐|著名|歌唱家|李雙|江和|知名|歌唱家|夢鴿|之子|根據|司法機關|公佈|資料|顯示|李天一|出生於|1996年|4月|就讀|北京|海淀區|中關村第三小學|人民大學|附中|美國|shattuck-st.|mary|s|school|沙|特克|聖瑪麗學院|冰球|學校|2011年|9月6日|與人|鬥毆|拘留|教養|1年|2012年|9月19日|李天|一被|解除|教養|2013年|2月22日|因涉嫌|輪姦案|刑事拘留|可查|資料|顯示|未成年|移交|少管所|3月7日|中央電視臺|新聞中心|官方|微博|釋出|一條|訊息|稱|李天一|因涉嫌|強姦罪|已被|檢察機關|批捕|2013年|9月|李雙江|一篇|舊文|證實|李天一|成年|
可以看到有些詞分出來不是很準確,比如上面紅色標記的部分,這裡採用了智慧匹配,但是依然出錯了,分出來的詞甚至不在詞表中。看來還是ANSJ分詞比較靠譜。