
機器學習實戰筆記6—AdaBoost
注:此係列文章裡的部分演算法和深度學習筆記系列裡的內容有重合的地方,深度學習筆記裡是看教學視訊做的筆記,此處文章是看《機器學習實戰》這本書所做的筆記,雖然演算法相同,但示例程式碼有所不同,多敲一遍沒有壞處,哈哈。(裡面用到的資料集、程式碼可以到網上搜索,很容易找到。)。Python版本3.6
機器學習十大算法系列文章:
機器學習實戰筆記1—k-近鄰演算法
機器學習實戰筆記2—決策樹
機器學習實戰筆記3—樸素貝葉斯
機器學習實戰筆記4—Logistic迴歸
機器學習實戰筆記5—支援向量機
機器學習實戰筆記6—AdaBoost
機器學習實戰筆記7—K-Means
此係列原始碼在我的GitHub裡:
一,演算法原理:
A) Boosting提升演算法
AdaBoost是典型的Boosting演算法,屬於Boosting家族的一員。在說AdaBoost之前,先說說Boosting提升演算法。Boosting演算法是將“弱學習演算法“提升為“強學習演算法”的過程,主要思想是“三個臭皮匠頂個諸葛亮”。一般來說,找到弱學習演算法要相對容易一些,然後通過反覆學習得到一系列弱分類器,組合這些弱分類器得到一個強分類器。Boosting演算法要涉及到兩個部分,加法模型和前向分步演算法。加法模型就是說強分類器由一系列弱分類器線性相加而成。一般組合形式如下:
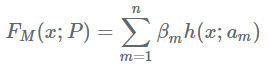
其中,h(x;) 就是一個個的弱分類器,
是弱分類器學習到的最優引數,
就是弱學習在強分類器中所佔比重,P是所有
和
的組合。這些弱分類器線性相加組成強分類器。前向分步就是說在訓練過程中,下一輪迭代產生的分類器是在上一輪的基礎上訓練得來的。也就是可以寫成這樣的形式:
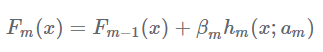
由於採用的損失函式不同,Boosting演算法也因此有了不同的型別,AdaBoost就是損失函式為指數損失的Boosting演算法。
B) AdaBoost原理理解
基於Boosting的理解,對於AdaBoost,我們要搞清楚兩點:
- 每一次迭代的弱學習h(x;
)有何不一樣,如何學習?
- 弱分類器權值如何確定?
對於第一個問題,AdaBoost改變了訓練資料的權值,也就是樣本的概率分佈,其思想是將關注點放在被錯誤分類的樣本上,減小上一輪被正確分類的樣本權值,提高那些被錯誤分類的樣本權值。然後,再根據所採用的一些基本機器學習演算法進行學習,比如邏輯迴歸。
對於第二個問題,AdaBoost採用加權多數表決的方法,加大分類誤差率小的弱分類器的權重,減小分類誤差率大的弱分類器的權重。這個很好理解,正確率高分得好的弱分類器在強分類器中當然應該有較大的發言權。
C) 舉例
為了加深理解,我們來舉一個例子。有如下的訓練樣本,我們需要構建強分類器對其進行分類。x是特徵,y是標籤。
| 序號 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
令權值分佈D1=(,
,…,
),
並假設一開始的權值分佈是均勻分佈:=0.1,i=1,2,…,10
現在開始訓練第一個弱分類器。我們發現閾值取2.5時分類誤差率最低,得到弱分類器為:
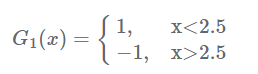
當然,也可以用別的弱分類器,只要誤差率最低即可。這裡為了方便,用了分段函式。得到了分類誤差率e1=0.3。
第二步計算在強分類器中的係數
,這個公式先放在這裡,下面再做推導。
第三步更新樣本的權值分佈,用於下一輪迭代訓練。由公式:

其中計算公式,將下列公式中的m換成1帶入即可,(m表示第m次迭代)

可以看出,被分類正確的樣本權值減小了,被錯誤分類的樣本權值提高了。
第四步得到第一輪迭代的強分類器:
![]()
以此類推,經過第二輪……第N輪,迭代多次直至得到最終的強分類器。迭代範圍可以自己定義,比如限定收斂閾值,分類誤差率小於某一個值就停止迭代,比如限定迭代次數,迭代1000次停止。這裡資料簡單,在第3輪迭代時,得到強分類器:
![]()
的分類誤差率為0,結束迭代。
F(x)=sign((x))就是最終的強分類器。
二,演算法的優缺點:
優點:泛華錯誤率低,易編碼,可以應用在大部分分類器上,無引數調整。
缺點:對離群點敏感。
適用資料型別:
三,例項程式碼:
A)基於單層決策樹構建弱分類器
建立AdaBoost演算法之前,我們必須先建立弱分類器,並儲存樣本的權重。弱分類器使用單層決策樹(decision stump),也稱決策樹樁,它是一種簡單的決策樹,通過給定的閾值,進行分類。
A1) 資料集視覺化
為了訓練單層決策樹,我們需要建立一個訓練集,編寫程式碼如下:
'''
Created on Nov 11, 2018
Adaboost is short for Adaptive Boosting
@author: SXL
'''
# -*-coding:utf-8 -*-
from numpy import *
import numpy as np
import matplotlib.pyplot as plt
def loadSimpData():
datMat = matrix([[ 1. , 2.1],
[ 2. , 1.1],
[ 1.3, 1. ],
[ 1. , 1. ],
[ 2. , 1. ]])
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
return datMat,classLabels
"""
資料視覺化
dataMat - 資料矩陣
labelMat - 資料標籤
Returns:無
"""
def showDataSet(dataMat, labelMat):
data_plus = [] #正樣本
data_minus = [] #負樣本
for i in range(len(dataMat)):
if labelMat[i] > 0:
data_plus.append(dataMat[i])
else:
data_minus.append(dataMat[i])
data_plus_np = np.array(data_plus) #轉換為numpy矩陣
data_minus_np = np.array(data_minus) #轉換為numpy矩陣
plt.scatter(np.transpose(data_plus_np)[0], np.transpose(data_plus_np)[1]) #正樣本散點圖
plt.scatter(np.transpose(data_minus_np)[0], np.transpose(data_minus_np)[1]) #負樣本散點圖
plt.show()
if __name__ == '__main__':
dataArr,classLabels = loadSimpData()
showDataSet(dataArr,classLabels)程式碼結果:

可以看到,如果想要試著從某個座標軸上選擇一個值(即選擇一條與座標軸平行的直線)來將所有的藍色圓點和橘色圓點分開,這顯然是不可能的。這就是單層決策樹難以處理的一個著名問題。通過使用多顆單層決策樹,我們可以構建出一個能夠對該資料集完全正確分類的分類器。
A2) 構建單層決策樹
我們設定一個分類閾值,比如我橫向切分,如下圖所示:

藍橫線上邊的是一個類別,藍橫線下邊是一個類別。顯然,此時有一個藍點分類錯誤,計算此時的分類誤差,誤差為1/5 = 0.2。這個橫線與座標軸的y軸的交點,就是我們設定的閾值,通過不斷改變閾值的大小,找到使單層決策樹的分類誤差最小的閾值。同理,豎線也是如此,找到最佳分類的閾值,就找到了最佳單層決策樹,編寫程式碼如下:
"""
單層決策樹分類函式
dataMatrix - 資料矩陣
dimen - 第dimen列,也就是第幾個特徵
threshVal - 閾值
threshIneq - 標誌
Returns:retArray - 分類結果
"""
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
retArray = np.ones((np.shape(dataMatrix)[0],1)) #初始化retArray為1
if threshIneq == 'lt': #lt:less than,
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0 #如果小於閾值,則賦值為-1
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0 #如果大於閾值,則賦值為-1
return retArray
"""
找到資料集上最佳的單層決策樹
dataArr - 資料矩陣
classLabels - 資料標籤
D - 樣本權重
Returns:
bestStump - 最佳單層決策樹資訊
minError - 最小誤差
bestClasEst - 最佳的分類結果
"""
def buildStump(dataArr,classLabels,D):
dataMatrix = np.mat(dataArr); labelMat = np.mat(classLabels).T #轉化成mat矩陣
m,n = np.shape(dataMatrix) #獲取資料集的維度資訊
numSteps = 10.0; bestStump = {}; bestClasEst = np.mat(np.zeros((m,1))) #bestStump最佳單層決策樹資訊 bestClasEst - 最佳的分類結果
minError = float('inf') #最小誤差初始化為正無窮大
for i in range(n): #遍歷所有特徵
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max() #找到特徵中最小的值和最大值
stepSize = (rangeMax - rangeMin) / numSteps #計算步長
for j in range(-1, int(numSteps) + 1): #第二層迴圈,對每個步長
for inequal in ['lt', 'gt']: #第三層迴圈,大於和小於的情況,均遍歷。lt:less than,gt:greater than
threshVal = (rangeMin + float(j) * stepSize) #計算閾值
predictedVals = stumpClassify(dataMatrix, i, threshVal, inequal)#計算分類結果
errArr = np.mat(np.ones((m,1))) #初始化誤差矩陣
errArr[predictedVals == labelMat] = 0 #分類正確的,賦值為0
weightedError = D.T * errArr #計算誤差
print("split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError))
if weightedError < minError: #找到誤差最小的分類方式
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEst
if __name__ == '__main__':
dataArr,classLabels = loadSimpData() #載入資料
D = np.mat(np.ones((5, 1)) / 5) #D是資料集中每個特徵的權重向量
bestStump,minError,bestClasEst = buildStump(dataArr,classLabels,D)
print('bestStump:\n', bestStump)
print('minError:\n', minError)
print('bestClasEst:\n', bestClasEst)
程式碼結果:

程式碼不難理解,就是通過遍歷,改變不同的閾值,計算最終的分類誤差,找到分類誤差最小的分類方式,即為我們要找的最佳單層決策樹。這裡lt表示less than,表示分類方式,對於小於閾值的樣本點賦值為-1,gt表示greater than,也是表示分類方式,對於大於閾值的樣本點賦值為-1。經過遍歷,我們找到,訓練好的最佳單層決策樹的最小分類誤差為0.2,就是對於該資料集,無論用什麼樣的單層決策樹,分類誤差最小就是0.2。這就是我們訓練好的弱分類器。接下來,使用AdaBoost演算法提升分類器效能,將分類誤差縮短到0,看下AdaBoost演算法是如何實現的。
五 使用AdaBoost提升分類器效能
B)使用AdaBoost提升分類器效能
在上面,我們構建了一個基於加權輸入值進行決策的分類器。現在我們擁有了實現一個完整AdaBoost演算法所需要的所有資訊。
整個實現的虛擬碼如下:
對每次迭代:
利用buildStump()函式找到最佳的單層決策樹
將最佳單層決策樹加入到單層決策樹陣列
計算-alpha
計算新的權重向量D
更新累計類別估計值
如果錯誤率等於0,則退出迴圈實現程式碼:
#使用AdaBoost提升分類器效能
def adaBoostTrainDS(dataArr, classLabels, numIt = 40):
weakClassArr = [] #弱分類器陣列
m = np.shape(dataArr)[0] #獲得資料長度
D = np.mat(np.ones((m, 1)) / m) #初始化權重
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(numIt): #迭代次數
bestStump, error, classEst = buildStump(dataArr, classLabels, D) #構建單層決策樹
print("D:",D.T)
alpha = float(0.5 * np.log((1.0 - error) / max(error, 1e-16))) #計算弱學習演算法權重alpha,使error不等於0,因為分母不能為0
bestStump['alpha'] = alpha #儲存弱學習演算法權重
weakClassArr.append(bestStump) #儲存單層決策樹
print("classEst: ", classEst.T) # classEst最佳的分類結果
expon = np.multiply(-1 * alpha * np.mat(classLabels).T, classEst) #np.multiply元素乘法,計算e的指數項
D = np.multiply(D, np.exp(expon)) #np.exp返回e的冪次方,e是一個常數為2.71828
D = D / D.sum() #根據樣本權重公式,更新樣本權重
#計算AdaBoost誤差,當誤差為0的時候,退出迴圈
aggClassEst += alpha * classEst
print("aggClassEst: ", aggClassEst.T)
aggErrors = np.multiply(np.sign(aggClassEst) != np.mat(classLabels).T, np.ones((m,1))) #計算誤差 np.sign([-5., 4.5])-》array([-1., 1.])
errorRate = aggErrors.sum() / m
print("total error: ", errorRate)
if errorRate == 0.0: break #誤差為0,退出迴圈
return weakClassArr, aggClassEst
if __name__ == '__main__':
dataArr,classLabels = loadSimpData() #載入資料
weakClassArr, aggClassEst = adaBoostTrainDS(dataArr, classLabels) #adaboost訓練分類器
print("弱分類器陣列",weakClassArr)
print("強分類器",aggClassEst)程式碼結果:

在第一輪迭代中,D中的所有值都相等。於是,只有第一個資料點被錯分了。因此在第二輪迭代中,D向量給第一個資料點0.5的權重。這就可以通過變數aggClassEst的符號來了解總的類別。第二次迭代之後,我們就會發現第一個資料點已經正確分類了,但此時最後一個數據點卻是錯分了。D向量中的最後一個元素變為0.5,而D向量中的其他值都變得非常小。最後,第三次迭代之後aggClassEst所有值的符號和真是類別標籤都完全吻合,那麼訓練錯誤率為0,程式終止執行。
最後訓練結果包含了三個弱分類器,其中包含了分類所需要的所有資訊。一共迭代了3次,所以訓練了3個弱分類器構成一個使用AdaBoost演算法優化過的分類器,分類器的錯誤率為0。
一旦擁有了多個弱分類器以及其對應的alpha值,進行測試就變得想當容易了。編寫程式碼如下:
"""
AdaBoost分類函式
datToClass - 待分類樣例
classifierArr - 訓練好的分類器
Returns:分類結果
"""
def adaClassify(datToClass,classifierArr):
dataMatrix = np.mat(datToClass)
m = np.shape(dataMatrix)[0]
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(len(classifierArr)): #遍歷所有分類器,進行分類
classEst = stumpClassify(dataMatrix, classifierArr[i]['dim'], classifierArr[i]['thresh'], classifierArr[i]['ineq'])
aggClassEst += classifierArr[i]['alpha'] * classEst
print(aggClassEst)
return np.sign(aggClassEst)
if __name__ == '__main__':
dataArr,classLabels = loadSimpData()
weakClassArr, aggClassEst = adaBoostTrainDS(dataArr, classLabels)
print("分類結果:\n",adaClassify([[0,0],[5,5]], weakClassArr)) #[[0,0],[5,5]] 兩個測試點程式碼結果:

程式碼很簡單,在之前程式碼的基礎上,新增adaClassify()函式,該函式遍歷所有訓練得到的弱分類器,利用單層決策樹,輸出的類別估計值乘以該單層決策樹的分類器權重alpha,然後累加到aggClassEst上,最後通過sign函式最終的結果。可以看到,分類沒有問題,(5,5)屬於正類,(0,0)屬於負類。
C)在一個難資料集上應用AdaBoost
機器學習實戰筆記4—Logistic迴歸文章中,我們使用Logistic迴歸方法訓練馬疝病資料集,預測病馬死亡率。當時的訓練結果如下圖所示:

這個是使用Sklearn的LogisticRegression()訓練的分類器,可以看到,錯誤率約為34.9254%。可以看到錯誤率還是蠻高的,現在我們使用AdaBoost演算法,訓練出一個更強的分類器,這裡的資料集有所變化,之前的標籤是0和1,現在將標籤改為+1和-1,其他資料不變。
使用自己用Python寫的AbaBoost演算法進行訓練,新增loadDataSet函式用於載入資料集。編寫程式碼如下:
def loadDataSet(fileName): #general function to parse tab -delimited floats
numFeat = len(open(fileName).readline().split('\t')) #get number of fields
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr =[]
curLine = line.strip().split('\t')
for i in range(numFeat-1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat,labelMat
if __name__ == '__main__':
dataArr, LabelArr = loadDataSet('horseColicTraining2.txt')
weakClassArr, aggClassEst = adaBoostTrainDS(dataArr, LabelArr)
testArr, testLabelArr = loadDataSet('horseColicTest2.txt')
print(weakClassArr)
predictions = adaClassify(dataArr, weakClassArr)
errArr = np.mat(np.ones((len(dataArr), 1)))
print('訓練集的錯誤率:%.3f%%' % float(errArr[predictions != np.mat(LabelArr).T].sum() / len(dataArr) * 100))
predictions = adaClassify(testArr, weakClassArr)
errArr = np.mat(np.ones((len(testArr), 1)))
print('測試集的錯誤率:%.3f%%' % float(errArr[predictions != np.mat(testLabelArr).T].sum() / len(testArr) * 100))程式碼結果:

這裡輸出了AdaBoost演算法訓練好的分類器的組合,我們只迭代了40次,也就是訓練了40個弱分類器。最終,訓練集的錯誤率為19.732%,測試集的錯誤率為19.403%,可以看到相對於Sklearn的羅輯迴歸方法,錯誤率降低了很多。這個僅僅是我們訓練40個弱分類器的結果,如果訓練更多弱分類器,效果會更好。但是當弱分類器數量過多的時候,你會發現訓練集錯誤率降低很多,但是測試集錯誤率提升了很多,這種現象就是過擬合(overfitting)。分類器對訓練集的擬合效果好,但是缺失了普適性,只對訓練集的分類效果好,這是我們不希望看到的。
D)使用Sklearn的AdaBoost
sklearn.ensemble模組提供了很多整合方法,AdaBoost、Bagging、隨機森林等。本文使用的是AdaBoostClassifier。
# -*-coding:utf-8 -*-
import numpy as np
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
def loadDataSet(fileName):
numFeat = len((open(fileName).readline().split('\t')))
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = []
curLine = line.strip().split('\t')
for i in range(numFeat - 1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
return dataMat, labelMat
if __name__ == '__main__':
dataArr, classLabels = loadDataSet('horseColicTraining2.txt')
testArr, testLabelArr = loadDataSet('horseColicTest2.txt')
bdt = AdaBoostClassifier(DecisionTreeClassifier(max_depth = 2), algorithm = "SAMME", n_estimators = 10)
bdt.fit(dataArr, classLabels)
predictions = bdt.predict(dataArr)
errArr = np.mat(np.ones((len(dataArr), 1)))
print('訓練集的錯誤率:%.3f%%' % float(errArr[predictions != classLabels].sum() / len(dataArr) * 100))
predictions = bdt.predict(testArr)
errArr = np.mat(np.ones((len(testArr), 1)))
print('測試集的錯誤率:%.3f%%' % float(errArr[predictions != testLabelArr].sum() / len(testArr) * 100))
程式碼結果:
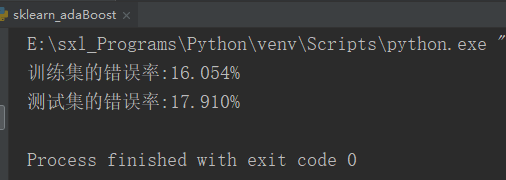
歡迎掃碼關注我的微信公眾號
