
機器學習實戰筆記——微軟小冰的讀心術與決策樹
最近微信朋友圈很多人在轉發的一個遊戲叫做“微軟小冰讀心術”,遊戲的規則很簡單:參與遊戲的一方在腦海裡想好一個人的名字,然後微軟小冰會問你15個問題,問題的答案只能用“是”、“不是”或者“不知道”回答。



微軟小冰通過你的回答進行推斷分解,逐步縮小待猜測人名的範圍,決策樹的工作原理與這些問題類似,使用者輸入一系列資料,然後會給出遊戲的答案。
一、決策樹簡介
決策樹(decision tree)是機器學習與資料探勘中一種十分常用的分類和迴歸方法,屬於有監督學習(supervised learning)演算法。通俗來說,決策樹分類的思想類似於找物件。現在想象一個女孩的母親要給這個女孩介紹男朋友,於是有了下面的對話:
女兒:多大年紀了?
母親:26。
女兒:長的帥不帥?
母親:挺帥的。
女兒:收入高不?
母親:不算很高,中等情況。
女兒:是公務員不?
母親:是,在稅務局上班呢。
女兒:那好,我去見見。
這個女孩的決策過程就是典型的決策樹方法。相當於通過年齡、長相、收入和是否公務員對將男人分為兩個類別:見和不見。假設這個女孩對男人的要求是:30歲以下、長相中等以上並且是高收入者或中等以上收入的公務員,那麼這個可以用下圖表示女孩的決策邏輯:
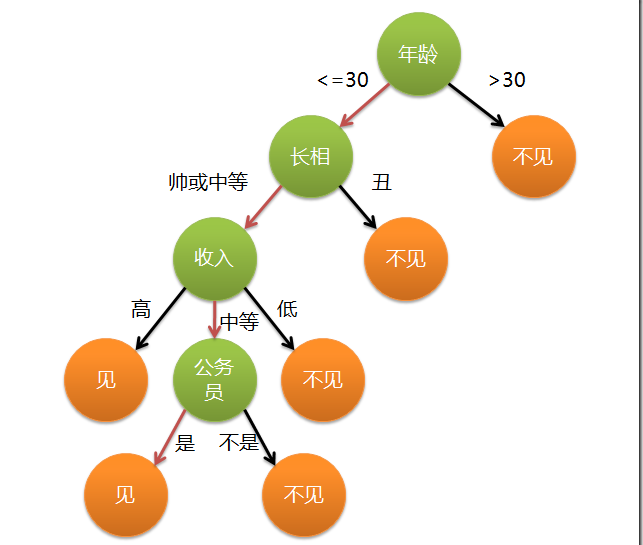
決策樹是一種樹型結構,其中每個內部結點表示在一個屬性上的測試,每個分支代表一個測試輸出,每個葉結點代表一個類別。
決策樹學習是以例項為基礎的歸納學習,決策樹學習採用的是自頂向下的遞迴方法,其基本思想是以資訊熵為度量構造一棵熵值(熵的概念請參考資訊理論的書籍)下降最快的樹,到葉子結點處的熵值為零,此時,每個葉結點中的例項都屬於同一類。
二、決策樹的構造
1.建立分支
建立分支的虛擬碼函式createBranch()如下所示:
檢測資料集中的每一個子項是否屬於同一類;
If so return 類標籤;
Else
尋找劃分資料集的最好特徵;
劃分資料集;
建立分支結點;
for 每個劃分的子集
呼叫函式createBranch()並增加返回結果到分支結點中
return 分支結點;
上面的虛擬碼createBranch()是一個遞迴函式,在倒數第二行直接呼叫了它本身。

上表的資料包含5個海洋生物,特徵包括:不浮出水面是否可以生存,以及是否有腳蹼。
我們可以將這些生物分成兩類:魚類和非魚類,現在我們想要決定依據第一個特徵還是第二個特徵來劃分資料。
在討論這個問題前,我們先了解決策樹演算法中的一些資訊理論概念:
1.資訊量
定義事件X發生的資訊量為:
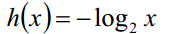
某事件發生的概率越小,則該事件的資訊量越大,一定發生和一定不會發生的必然事件的資訊量為0。
例如,今天是22號,別人說明天是23號,這就沒有一點資訊量。
2.資訊熵
資訊熵是資訊量的期望,定義為:
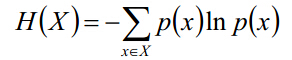
其中p(x)是,事件x發生的概率。資訊熵一般用來表徵事件或變數的不確定性,變數的不確定性越大,資訊熵就越大。一個系統越有序,它的資訊熵就越小,反之,一個混亂的系統資訊熵越大,所以資訊熵是系統有序化程度的一個度量。
3.聯合熵和條件熵
兩個隨機變數X、Y的聯合分佈形成聯合熵H(X,Y),已知Y發生的前提下,X的熵叫做條件熵H(X|Y)。

4.互資訊兩個隨機變數X、Y的互資訊定義為X、Y的資訊熵減去X、Y的聯合熵。
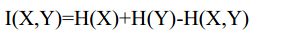
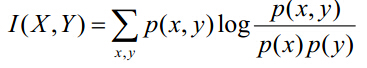
5.資訊增益
資訊熵又稱為先驗熵,是在資訊傳送前資訊量的數學期望,後驗熵是指資訊傳送後,從信宿(即資訊的接收者)角度對資訊量的數學期望。一般先驗熵大於後驗熵,先驗熵與後驗熵的差就是資訊增益,反映的是資訊消除隨機不確定性的程度。

決策樹學習中的資訊增益等價於訓練集中類別與特徵的互資訊。
資訊增益表示得知特徵A的資訊而使得類X的資訊的不確定性減少的程度。
劃分資料集的最大原則是:將無序的資料變得更加有序。劃分資料集前後資訊傳送的變化就行資訊增益,通過計算每個特徵值劃分資料集獲得的資訊增益,我們就可以根據獲得資訊增益最高的特徵來選擇其作為劃分資料的特徵。

資訊增益的計算方法:

(1)計算給定資料集的資訊熵
from math import log
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet: #the the number of unique elements and their occurance
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2) #log base 2
return shannonEnt(2)建立資料集
利用createDataSet()函式得到表3-1所示的簡單魚鑑定資料集:
def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
labels = ['no surfacing','flippers']
#change to discrete values
return dataSet, labels
(3)劃分資料集
對每個特徵劃分資料集的結果計算一次資訊熵,然後判斷按照哪個特徵劃分資料集是最後的劃分方式。
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis] #chop out axis used for splitting
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet程式碼解析:spiltDataSet()的三個輸入引數分別是待劃分資料集dataSet、劃分資料集的特徵axis、需要返回的特徵的值。遍歷資料集中的每個元素,一旦發現符合要求的值,則將其新增到新建立的列表中。

選擇最好的資料集劃分方式:
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 #the last column is used for the labels
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures): #iterate over all the features
featList = [example[i] for example in dataSet]#create a list of all the examples of this feature
uniqueVals = set(featList) #get a set of unique values
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy #calculate the info gain; ie reduction in entropy
if (infoGain > bestInfoGain): #compare this to the best gain so far
bestInfoGain = infoGain #if better than current best, set to best
bestFeature = i
return bestFeature #returns an integer
程式碼執行結果告訴我們,第0個特徵是最好的用於劃分資料集的特徵。資料集的資料來源於表3-1,

如果我們按照第一個特徵屬性劃分資料,也就是說第一個特徵為1的放在一組,第一個特徵是0的放在另一個組,按照這種方式劃分的話,第一個特徵為1的海洋生物分組將有兩個屬於魚類,一個屬於非魚類;另一個分組則全部屬於非魚類。
如果我們按照第二個特徵分組,第一個海洋生物分組將有兩個屬於魚類,兩個屬於非魚類;另一個分組則只有一個非魚類。
可以看出,第一種劃分很好地處理了相關資料。
(4)遞迴構建決策樹
def majorityCnt(classList):
classCount={}
for vote in classList:
if vote not in classCount.keys(): classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]建立決策樹的函式程式碼:
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]#stop splitting when all of the classes are equal
if len(dataSet[0]) == 1: #stop splitting when there are no more features in dataSet
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:] #copy all of labels, so trees don't mess up existing labels
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
return myTree 
三、決策樹的過擬合
決策樹對訓練資料一般有很好的分類能力,但對未知的預測資料未必有好的分類能力,泛化能力較弱,即可能發生過擬合現象。
解決過擬合的方法:
1.剪枝
2.隨機森林