
《Squeeze-and-Excitation Networks(SENet)》
阿新 • • 發佈:2018-11-24
動機
- 卷積神經網路已被證明是解決各種視覺任務的有效模型。對於每個卷積層,沿著輸入通道學習一組濾波器來表達區域性空間連線模式。
- 換句話說,期望卷積濾波器通過融合空間資訊和通道資訊進行資訊組合,而受限於區域性感受野。通過疊加一系列非線性和下采樣交織的卷積層,CNN能夠捕獲具有全域性感受野的分層模式作為強大的影象描述。
- 最近的工作已經證明,網路的效能可以通過顯式地嵌入學習機制來改善,這種學習機制有助於捕捉空間相關性而不需要額外的監督。Inception架構推廣了一種這樣的方法,這表明網路可以通過在其模組中嵌入多尺度處理來取得有競爭力的準確度。最近的工作在尋找更好地模型空間依賴,結合空間注意力。
- 與這些方法相反,通過引入新的架構單元,我們稱之為*“Squeeze-and-Excitation”* (SE)塊,我們研究了架構設計的一個不同方向——通道關係。我們的目標是通過顯式地建模卷積特徵通道之間的相互依賴性來提高網路的表示能力。為了達到這個目的,我們提出了一種機制,使網路能夠執行特徵重新校準,通過這種機制可以學習使用全域性資訊來選擇性地強調資訊特徵並抑制不太有用的特徵;
方法
Squeeze-and-Excitation塊
- Excitation部分是用2個全連線來實現 ,第一個全連線把C個通道壓縮成了C/r個通道來降低計算量(後面跟了RELU),第二個全連線再恢復回C個通道(後面跟了Sigmoid),r是指壓縮的比例。作者嘗試了r在各種取值下的效能 ,最後得出結論r=16時整體效能和計算量最平衡。
為什麼要加全連線層呢?這是為了利用通道間的相關性來訓練出真正的scale。一次mini-batch個樣本的squeeze輸出並不代表通道真實要調整的scale值,真實的scale要基於全部資料集來訓練得出,而不是基於單個batch,所以後面要加個全連線層來進行訓練。可以拿SE Block和下面3種錯誤的結構比較來進一步理解:
圖2最上方的結構,squeeze的輸出直接scale到輸入上,沒有了全連線層,某個通道的調整值完全基於單個通道GAP的結果,事實上只有GAP的分支是完全沒有反向計算、沒有訓練的過程的,就無法基於全部資料集來訓練得出通道增強、減弱的規律。
圖2中間是經典的卷積結構,有人會說卷積訓練出的權值就含有了scale的成分在裡面,也利用了通道間的相關性,為啥還要多個SE Block?那是因為這種卷積有空間的成分在裡面,為了排除空間上的干擾就得先用GAP壓縮成一個點後再作卷積,壓縮後因為沒有了Height、Width的成分,這種卷積就是全連線了。
圖2最下面的結構,SE模組和傳統的卷積間採用並聯而不是串聯的方式,這時SE利用的是Ftr輸入X的相關性來計算scale,X和U的相關性是不同的,把根據X的相關性計算出的scale應用到U上明顯不合適。

資料集
- SENets是我們ILSVRC 2017分類提交的基礎,它贏得了第一名,並將
top-5錯誤率顯著減少到2.251%2.251%,相對於2016年的獲勝成績取得了∼25%∼25%的相對改進
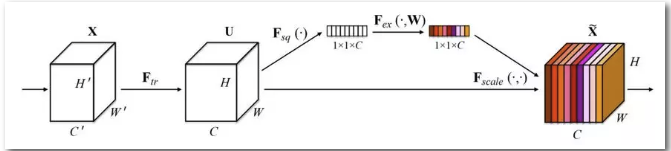
- SENet是基於特徵通道之間的關係提出的,下圖是SENet的Block單元,圖中的Ftr是傳統的卷積結構,X和U是Ftr的輸入和輸出,這些都是以往結構中已存在的。SENet增加的部分是U後的結構:對U先做一個Global Average Pooling(稱為Squeeze過程),輸出是一個1x1xC的資料,再經過兩級全連線(稱為Excitation過程),最後用sigmoid把輸出限制到[0,1]的範圍,把這個值作為scale再乘到U的C個通道上,作為下一級的輸入資料。這種結構的原理是想通過控制scale的大小,把重要的特徵增強,不重要的特徵減弱,從而讓提取的特徵指向性更強。
- 下圖是把SENet模型分別用於Inception網路和ResNet網路,下圖左邊部分是原始網路,右邊部分是加了SENet之後的網路,分別變成SE-Inception和SE-ResNet。網路中的r是壓縮引數,先通過第一個全連線層把1x1xC的資料壓縮為1x1xC/r,再通過第二個全連線層把資料擴充套件到1x1xC。
