
深度學習論文翻譯解析(十六):Squeeze-and-Excitation Networks
論文標題:Squeeze-and-Excitation Networks
論文作者:Jie Hu Li Shen Gang Sun
論文地址:https://openaccess.thecvf.com/content_cvpr_2018/papers/Hu_Squeeze-and-Excitation_Networks_CVPR_2018_paper.pdf
SENet官方Caffe實現:https://github.com/hujie-frank/SENet
民間TensorFlow實現:https://github.com/taki0112/SENet-Tensorflow
民間PyTorch實現:https://github.com/moskomule/senet.pytorch
參考的 SENet 翻譯部落格:https://blog.csdn.net/Quincuntial/article/details/78605463
宣告:小編翻譯論文僅為學習,如有侵權請聯絡小編刪除博文,謝謝!
小編是一個機器學習初學者,打算認真研究論文,但是英文水平有限,所以論文翻譯中用到了Google,並自己逐句檢查過,但還是會有顯得晦澀的地方,如有語法/專業名詞翻譯錯誤,還請見諒,並歡迎及時指出。
如果需要小編其他論文翻譯,請移步小編的GitHub地址
傳送門:請點選我
如果點選有誤:https://github.com/LeBron-Jian/DeepLearningNote
SENet 是 ImageNet 2017(ImageNet收官賽)的冠軍模型,和ResNet的出現類似,都在很大程度上減少了之前模型的錯誤率,並且複雜度低,新增引數和計算量小,下面來學習一下其論文。
SE block並不是一個完整的網路結構,而是一個子結構,可以嵌入到其他分類或檢測模型中。作者在文中將 SENet block 和 ResNeXt 插入到現有的多種分類網路中,都取得了不錯的效果。SENet 的核心思想在於通過網路根據 loss 去學習特徵權重,使得有效的 feature map 權重大,無效或效果小的 feature map 權重小的方式訓練模型達到更好的結果。當然,SE block 嵌入在原有的一些分類網路中不可避免的增加了一些引數和計算量,但是在效果面前還是可接受的。最方便的是SENet思路簡單,很容易擴充套件在已有的網路結構中。


摘要
卷積神經網路建立在卷積運算的基礎上,通過融合區域性感受野內的空間資訊和通道資訊來提取資訊特徵。為了提高網路的表達能力,許多現有的工作已經顯示出增強空間編碼的好處。在這項工作中,我們專注於通道,並提出了一種新穎的架構單元,我們稱之為“Sequeeze-and-Excitation”(SE)塊,通過顯式的建模通道之間的互相依賴關係,自適應地重新校正通道式的特徵響應。通過將這些塊堆疊在一起,我們證明了我們可以構建SENet架構,在具有挑戰性的資料集中可以進行泛化地非常好。關鍵的是,我們發現SE塊以微小的計算成本為現有的最先進的深度架構產生了顯著的效能改進。SENets 是我們 ILSVRC 2017 分類提交的基礎,它贏得了第一名,並將 top-5 的錯誤率顯著減低到 2.251%,相對於 2016年的獲勝成績取得了~25%的相對改進。


1,介紹
卷積神經網路(CNNs)已被證明是解決各種視覺任務的有效模型【19,23,29,41】。對於每個卷積層,沿著輸入通道學習一組濾波器來表達區域性空間連結模式。換句話說,期望卷積濾波器通過融合空間資訊和通道資訊進行資訊組合,而受限於區域性感受野。通過疊加一系列非線性和下采樣交織的卷積層,CNN能夠捕獲具有全域性感受野的分層模式作為強大的影象描述。最近的工作已經證明,網路的效能可以通過顯式的嵌入學習機制來改善,這種學習機制有助於捕捉空間相關性而不需要額外的監督。Inception架構推廣了一種這樣的方法【14, 39】,這表明網路可以通過在其模組中嵌入多尺度處理來取得有競爭力的準確度。最近的工作在尋找更好的模型空間依賴【1, 27】,結合空間注意力【17】。
與這些方法相反,通過引入新的架構單元,我們稱之為“Sequeeze-and-Excitation”(SE)塊,我們研究了架構設計的一個不同方向——通道關係。我們的目標是通過顯式地建模卷積特徵通道之間的相互依賴性來提高網路的表示能力。為了達到這個目的,我們提出了一種機制,使網路能夠執行特徵重新校準,通過這個機制可以學習使用全域性資訊來選擇地強調資訊特徵並抑制不太有用的特徵。

SE構建塊的基本結構如圖1所示,對於任何給定的變換 Ftr:X->U(例如卷積或一組卷積),我們可以構造一個相應的 SE塊來執行特徵重新校準,如下所示。特徵U首先通過 Sequeeze 操作,該操作跨越空間維度 W*H 聚合特徵對映來產生通道描述符。這個描述符嵌入了通道特徵相應的全域性分佈,使來自網路全域性感受野的資訊能夠被其較低層利用。這之後是一個 excitation 操作,其中通過基於通道依賴性的自門機制為每個通道學習特定採用的啟用,控制每個通道的激勵。然後特徵對映 U 被重新加權以生成 SE 塊的輸出,然後可以將其直接輸入到隨後的層中。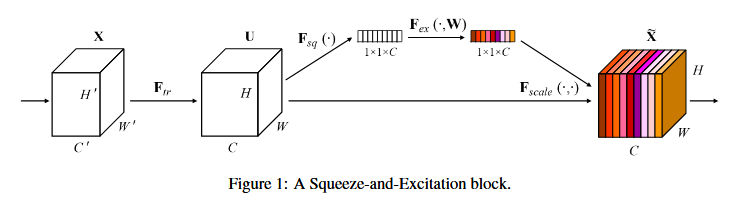
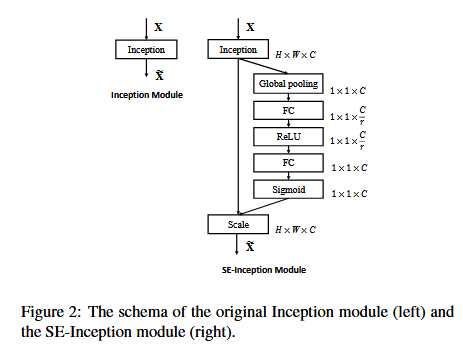
Figure 1 表示一個 SE block。主要包含 Squeeze和 Excitation兩部分。


SE網路可以通過簡單的堆疊SE構建塊的集合來生成。SE塊也可以用作架構中任意深度的原始塊的直接替換。然而,雖然構建塊的模板是通用的,正如我們6.3 節中展示的那樣,但它在不同深度的作用適應於網路的需求。在前面的層中,它學習以類不可知的方式激發資訊特徵,增強共享的較低層表示的質量。在後面的層中,SE塊越來越專業化,並以高度類特定的方式響應不同的輸入。因此,SE塊進行特徵重新校準的好處可以通過整個網路進行累積。
新CNN架構的開發是一項具有挑戰性的工程任務,通常涉及許多新的超引數和層配置的選擇。相比之下,上面概述的SE塊的設計是簡單的,並且可以直接與現有的最近架構一起使用,其卷積層可以直接用對應的SE層來替換從而進行加強。
另外,如第四節所示,SE塊在計算上是輕量級的,並且在模型複雜度和計算負擔方面僅稍微增加。為了支援這些宣告,我們開發了一些 SENets,即 SE-ResNet,SE-Inception,SE-ResNeXt 和 SE-Inception-ResNet,並在ImageNet 2012 資料集【30】上對SENets 進行了廣泛的評估。此外,為了證明SE塊的一般適用性,我們還呈現了ImageNet之外的結果,表明所提出的方法不受限於特定的資料集或任務。
使用SENets,我們贏得了ILSVRC 2017 分類競賽的第一名。我們的表現的最好的模型集合在測試集上達到了 2.251%的top-5錯誤率。與前一年的獲獎者(2.991% 的 top-5 錯誤率)相比,這表示~25%的相對改進。我們的模型和相關材料已經提供給研究界。

2,相關工作
深層架構。 大量的工作已經表明,以易於學習深度特徵的方式重構卷積神經網路的架構可以大大提高效能。VGGNets【39】和 Inception模型【43】證明深度增強可以獲得的好處,明顯超過了 ILSVRC 2014 之前的方法。批標準化(BN)【16】通過插入單元來調節層輸入穩定學習過程,改善了通過深度網路的梯度傳播,這使得可以用更深的深度進行進一步的實驗。He等人【10, 11】用ResNet表明,通過重構架構來訓練更深層次的網路是有效的,通過使用基於恆等對映的跳躍連線來學習殘差函式,從而減少跨單元的資訊流動。最近,網路層間連線的重新表述【5, 14】已被證明可以進一步改善深度網路的學習和表徵屬性。


另一種研究方法探索了調整網路模組化元件功能形式的方法。可以用分組卷積來增加基數(一組變換的大小)【15, 47】以學習更豐富的表示。多分支卷積可以解釋為這個概念的概括,使得卷積運算元可以更靈活的組合【16, 42, 43, 44】。跨通道相關性通常被對映為新的特徵組合,或者獨立的空間結構【6, 20】,或者聯合使用標準卷積濾波器【22】和1*1 卷積,然而大部分工作的目標是集中在減少模型和計算複雜度上面。這種方法反映了一個假設,即通道關係可以被表述為具有區域性感受野的例項不可知的函式的組合。相比之下,我們聲稱為網路提供一種機制來顯式建模通道之間的動態,非線性依賴關係,使用全域性資訊可以減輕學習過程,並且顯著增強網路的表達能力。
 注意力和門機制。從廣義上講,可以將注意力視為一種工具,將可用處理資源的分配偏向於輸入訊號的資訊最豐富的組成部分。這種機制的發展和理解一致是神經科學社群的一個長期研究領域,並且近年來作為一個強大補充,已經引起了深度神經網路的極大興趣。注意力已經被證明可以改善一系列任務的效能,從影象的定位和理解到基於序列的模型。它通常結合門功能(例如Softmax或Sigmoid)和序列技術來實現。最近的研究表明,它適用於影象標題和口頭閱讀等任務,其中利用它來有效的彙集多模態資料。在這些應用中,它通常用在表示較高級別抽象的一個或多個層的頂部,以用於模態之間的適應。高速網路採用門機制來調節快捷連線,使得可以學習非常深的架構。王等人受到語義分割成功的啟發,引入了一個使用沙漏模組的強大的 trunk-and-mask 注意力機制。這個高容量的單元被插入到中間階段之間的深度殘差網路中。相比之下,我們提出的SE塊是一個輕量級的門機制,專門用於以計算有效的方式對通道關係進行建模,並設計用於增強整個網路中模組的表示能力。
注意力和門機制。從廣義上講,可以將注意力視為一種工具,將可用處理資源的分配偏向於輸入訊號的資訊最豐富的組成部分。這種機制的發展和理解一致是神經科學社群的一個長期研究領域,並且近年來作為一個強大補充,已經引起了深度神經網路的極大興趣。注意力已經被證明可以改善一系列任務的效能,從影象的定位和理解到基於序列的模型。它通常結合門功能(例如Softmax或Sigmoid)和序列技術來實現。最近的研究表明,它適用於影象標題和口頭閱讀等任務,其中利用它來有效的彙集多模態資料。在這些應用中,它通常用在表示較高級別抽象的一個或多個層的頂部,以用於模態之間的適應。高速網路採用門機制來調節快捷連線,使得可以學習非常深的架構。王等人受到語義分割成功的啟發,引入了一個使用沙漏模組的強大的 trunk-and-mask 注意力機制。這個高容量的單元被插入到中間階段之間的深度殘差網路中。相比之下,我們提出的SE塊是一個輕量級的門機制,專門用於以計算有效的方式對通道關係進行建模,並設計用於增強整個網路中模組的表示能力。



3,Squeeze-and-Excitation 塊
首先 Ftr 這一步是轉換操作(嚴格說並不屬於 SENet,而是屬於原網路,可以看後面 SENet和 Inception及 ResNet 網路的結合),在文章就是一個標準的卷積操作而已。
Squeeze-and-Excitation 塊是一個計算單元,可以為任何給定的變換構建:Ftr:X->U。為了簡化說明,在接下來的表示中,我們將 Ftr 看做一個標準的卷積運算元。V=[v1, v2, ....vc] 表示學習到的一組濾波器核,Vc 指的是第c 個濾波器的引數。然後我們可以將 Ftr 的輸出寫作 U=[u1, u2, u3...uc],其中:

Ftr 得到的 U 就是 Figure 1 中的左邊第二個三維矩陣,也叫tensor,或者叫 C 個大小為 H*W 的 feature map,而 Uc 表示 U中第 c 個二維矩陣,下標 c 表示 channel。
這裡 * 表示卷積,vc = [v1c, v2c,.....vcc],X = [x1, x2,.....xc](為了簡潔表示,忽略偏置項)。這裡 Vsc 是2D空間核,因此表示 Vc 的一個單通道,作用於對應的通道 X。由於輸出是通過所有通道的和來產生的,所以通道依賴性被隱式的嵌入到 Vc中,但是這些依賴性與濾波器捕獲的空間相關性糾纏在一起(即做了sum),所以channel特徵關係與卷積核學習到的空間關係混合在一起,而SE模組就是為了抽離這種混雜,使得模型直接學習到 channel 特徵關係。我們的目標是確保能夠提高網路對資訊特徵的敏感度,以便後續轉換可以利用這些功能,並抑制不太有用的功能。我們建立通過顯式建模通道依賴性來實現這一點,以便在進入下一個轉換之前通過兩步重新校準濾波器響應,兩步為:squeeze 和 Excitation。SE構建塊的圖如圖1所示。

3.1 Squeeze:全域性資訊嵌入
為了解決利用通道依賴性的問題,我們首先考慮輸出特徵中每個通道的訊號。每個學習到的濾波器都對區域性感受野進行操作,因此變換輸出U的每個單元都無法利用該區域之外的上下文資訊。在網路較低的層次上其感受野尺寸很小,這個問題變得更嚴重。(即卷積核只是在一個區域性空間內進行操作, U 很難獲得足夠的資訊來提取 channel 之間的關係)
為了緩解這個問題,我們提出了將全域性空間資訊壓縮到一個通道的描述字元。這是通過使用全域性平均池化(global average pooling)生成 channel-wise 統計,正式的,統計z 是通過縮小U空間維度空位維度 H*W z c-th 元素的計算(原則上也可以採用更復雜的聚合策略):
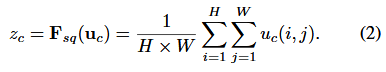
因此公式2就是將 HWC 的輸入轉換成 11C的輸出,對應 Figure 1中的 Fsq 操作。為什麼會有這一步操作呢?這一步的結果相當於表明該層C個feature map 的數值分佈情況,或者叫全域性資訊。
討論。轉換輸出U 可以被解釋為區域性描述子的集合,這些描述子的統計資訊對於整個影象來說是有表現力的。特徵工程工作中普遍使用這些資訊。我們選擇最簡單的全域性平均池化,同時也可以採用更復雜的匯聚策略。


3.2 Excitation :自適應重新校正
再接下來就是 Excitation操作,如下公式(3)。直接看最後一個等號,前面 squeeze 得到的結果是 z,這裡先用 W1 乘以 z,就是一個全連線層操作,W1的維度是 C/r*c,這個 r 是一個縮放參數,在文中取得是 16,這個引數的目的是減少 channel 個數從而降低計算量。又因為 z 的維度是 11C,所以 W1z 的結果就是 11C/r;然後再經過一個 ReLU層,輸出的維度不變;然後再和W2相乘,和 W2 相乘也是一個全連線層的過程,W2的維度是 C*C/r,因此輸出的維度就是 11C;最後再經過 Sigmoid函式,得到s。
為了利用壓縮操作中匯聚的資訊,我們接下來通過第二個操作來全面捕獲通道依賴性。為了實現這個目標,這個功能必須符合兩個標準:第一:它必須是靈活的(特別是它必須能夠學習通道之間的非線性互動);第二,它必須學習一個非互斥的關係,因為獨熱啟用相反,這裡允許強調多個通道。為了滿足這些標準,我們選擇採用一個簡單的門機制(gating機制),並使用Sigmoid啟用:
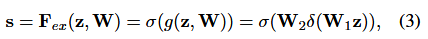
其中 δ 是指 ReLU函式,w1和w2,為了限制模型複雜度和輔助泛化,我們通過在非線性周圍形成兩個全連線(FC)層的瓶頸(bottleneck)來引數化門機制,即降維層引數為 W1,降維比例為 r(我們把它設定為 16,這個引數選擇在 6.3 節中討論),一個ReLU,然後是一個引數為W2的升維層。塊的最終輸出通過重新調節帶有啟用的變換輸出 U得到:
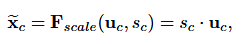
其中 X=[x1,x2,....xc] 和 Fscale(Uc, Sc) 指的是特徵對映 Uc 和標量 Sc之間的對應通道乘積。
討論。啟用作為適應特定輸入描述符 z 的通道權重。在這方面,SE塊本質上引入了以輸入為條件的動態特徵,有助於提高特徵辨別力。
這個 s 其實是本文的核心,它是用來刻畫 tensor U 中 C 個feature map 的權重。而且這個權重是通過前面這些全連線層和非線性層學習得到的,因此可以 end-to-end 訓練。這兩個全連線層的作用就是融合各通道的 feature map 資訊,因為前面的 squeeze 都是在某個 channel 的 feature map 裡面操作。

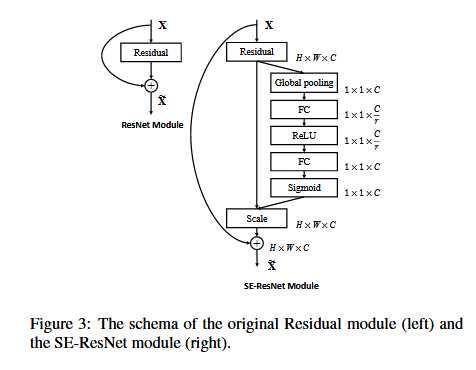
3.3 模型:SE-Inception 和 SE-ResNet
SE模組的靈活性在於它可以直接應用現有的網路結構中。可以直接應用 SE塊在AlexNet和VGGNet。SE塊的靈活性意味著它可以直接應用到標準卷積之外的變換。為了說明這一點,我們開發SENets 通過整個 SE塊與複雜的現代架構設計。
對於非殘差網路,比如Inception Network,SE blocks 構造網路通過變換 F 是整個inception模組。通過這種變化對於每一次這樣的模型架構,我們構造一個 SE-Inception 網路。此外,SE blocks 足夠靈活的在殘差網路中使用。圖3描述了一個 SE-ResNet模組的模式。這裡,SE塊變換 F 被殘餘的 non-identity 分支模組。擠壓和激勵行動之前求和與身份分支。更多的變異與ResNeXt 整合,Inception-ResNet Mobilenet 和 ShuffleNet 可以由類似的計劃。我們描述的架構 SE ResNet-50 SE-ResNeXt-50 在表1。

4,模型和計算複雜度
對於提出的SE block 在實踐中是可行的。它必須提供一個有效的模型複雜度和計算開銷,這對可伸縮性是重要的。為了說明模組的成本,作為例子我們比較了 ResNet-50 和 SE-ResNet-50,其中 SE-ResNet-50 的 精確度是明顯優於 ResNet-50,接近更深的 ResNet-101 網路(如表2所示)。對於 224*224 畫素的輸入影象,ResNet-50單次前向傳播需要 ~ 3.86 CFLOP。每個 SE 塊利用壓縮階段的全域性平均池化操作和激勵階段中的兩個小的全連線層,接下來是廉價的通道縮放操作。總的來說,SE-ResNet-50 需要 ~3.87 GFLOP,相對於原始的 ResNet-50 只相對增加了 0.26%。


在實踐中,訓練的批資料大小為 256 張影象,ResNet-50 的一次前向傳播和反向傳播花費 190 ms,而 SE-ResNet-50 則花費 209 ms(兩個時間都在具有8個NVIDIA Titan X GPU 的伺服器上執行)。我們認為這是一個合理的開銷,因為在現有的 GPU 庫中,全域性池化和小型內積操作的優化程度較低。此外,由於其對嵌入式裝置應用的重要性,我們還對每個模型的 CPU 推斷時間進行了基準測試:對於 224*224 畫素的輸入影象,ResNet-50 花費了 164ms,相比之下,SE-ReNet-50 花費了 167ms。SE塊所需的小的額外計算開銷對於其對模型效能的貢獻來說是合理的(在第6節中詳細討論)。

接下來,我們考慮所提出的塊引入的附加引數。所有附加引數都包含在門機制的兩個全連線層中,構成網路總容量的一小部分。更確切的說,引入的附加引數的數量由下式計算:

其中 r 表示減少比率(我們在所有的實驗中將 r 設定為 16),S指的是階段數量(每個階段是指在共同的空間維度的特徵對映上執行的塊的集合),Cs 表示階段 s 的輸出通道的維度,Ns表示重複的塊編號。總的來說,SE-ResNet-50 在 ResNet-50 所要求的 ~2500 萬引數之外引入了 ~250萬附加引數,相對增加了 ~10% 的引數總數量。這些附加引數中的大部分來自於網路的最後階段,其中激勵在最大的通道維度上執行。然而,我們發現SE塊相對昂貴的最終階段可以在效能的邊際成本上被移除,將相對引數增加減少到 ~4%,這在引數使用是關鍵考慮的情況下可能證明是有用的。


5,實現
每個普通網路及其相應的 SE 對應訓練相同的優化方案。在訓練過程中,我們遵循標準的做法,使用隨機大小裁剪到 224*224 畫素(299*299 用於 Inception-ResNet-v2 和 SE-Inception-ResNet-v2)和隨機的水平翻轉進行資料增強。輸入影象通過通道減去均值進行歸一化。另外,我們採用【32】中描述的資料均衡策略進行小批量此案有,以補償類別不同的不均勻分佈。網路在我們的分散式學習系統“ROCS”上進行訓練,能夠處理大型網路的高效並行訓練。使用同步 SGD 進行優化,動量為 0.9,小批量資料的大小為 1024(在4個伺服器的每個 GPU 上分成 32張影象的子批次,每個伺服器包含 8 個GPU)。初始學習率設為 0.6,每 30個迭代週期減少 10 倍。使用【8】中描述的權重初始化策略,所有模型都從零開始訓練 100 個迭代週期。
當測試時,我們應用中心裁剪評估驗證集,其中從每幅影象裁剪 224*224 畫素,其間斷的邊緣首次被縮放到 256(在 Inception-ResNet-v2 和 SE-Inception-ResNet-v2中,從每幅影象的較短邊緣首次被縮放到 352的影象裁剪為 299*299)





6,實驗
在這一部分,我們在 ImageNet 2012 資料集上進行了大量的實驗【30】,其目的是:首先探索提出的 SE 塊對不同深度基礎網路的影響;其次,調查它與最先進的網路架構整合後的能力,旨在公平比較 SENets 和 非 SENets,而不是推動效能。接下來,我們將介紹 ILSVRC 2017 分類任務模型的結果和詳細資訊。此外,我們在 Places 365-Challenge 場景分類資料集【48】上進行了實驗,以研究 SENets 是否能夠很好地泛化到其他資料集。最後,我們研究激勵的作用,並根據實驗現象給出了一些分析。
網路深度。我們首先將 SE-ResNet 與一系列標準 ResNet架構進行比較。每個 ResNet及其相應的 SE-ResNet 都使用相同的優化方案進行訓練。驗證集上不同網路的效能如表2所示,表明SE塊在不同深度上的網路上計算複雜度極小增加,始終提高效能。
6.1 ImageNet 分類
ImageNet 2012 資料集包含來自 1000 個類別的 128 萬張訓練影象和 5 萬張驗證影象。我們在訓練集上訓練網路,並在驗證集上使用中心裁剪影象評估來報告 top-1 和 top-5 的錯誤率,其中每張影象短邊首先歸一化為 256,然後從每張影象中裁剪出 224*224 個畫素,(對於Inception-ResNet-v2 和 SE-Inception-ResNet-v2,每幅影象的短邊首先歸一化到 352,然而裁剪出 299*299個畫素)。
值得注意的是,SE-ResNet-50 實現了單裁剪影象 6.62% 的 top-5 驗證錯誤率,超過了 ResNet-50(7.48%)0.86%,接近更深的 ResNet-101 網路(6.52% 的 top-5 錯誤率),且只有 ResNet-101 一半的計算開銷(3.87 GFLOPs vs 7.58 GFLOPs)。這種模式在更大的深度上重複,SE-ResNet-101(6.07%的 top-5 錯誤率)不僅可以匹配,而且超過了更深的 ResNet-152 網路(6.34% 的 top-5 錯誤率)。圖4分別描繪了 SE-ResNets 和 ResNets 的訓練和驗證曲線。雖然應該注意 SE 塊本身增加了深度,但是他們的計算效率極高,即使在擴充套件的基礎架構的深度達到收益遞增的點上也能產生良好的回報。而且,我們看到通過對各種不同深度的訓練,效能改進是一致的,這表明 SE 塊引起的改進可以與增加基礎架構更多深度結合使用。

與現代架構整合。接下來我們將研究 SE 塊與另外兩種最先進的架構 Inception-ResNet-v2 和 ResNeXt 的結合效果。Inception 架構將卷積模式構造為分解濾波器的多分支組合,反映了 Inception假設,可以獨立對映空間相關性和跨通道相關性。相比之下,ResNeXt 體架設斷言,可以通過聚合稀疏連線(在通過維度中)卷積特徵的組合來獲得更豐富的表示。兩種方法都在模組中引入先前結構化的相關性。我們構造了這些網路的 SENet等價物,SE-Inception-ResNet-v2 和 SE-ResNeXt(表1給出了 SE-ResNeXt-50(32*4d)的配置)。像前面的實驗一樣,原始網路和他們對應的 SENet 網路都使用相同的優化方案。
表2中給出的結果說明在 SE 塊引入到兩種架構中會引起顯著的效能改善。尤其是 SE-ResNeXt-50 的 top-5 錯誤率是 5.49%,優化於它直接對應的 ResNeXt-50(5.90%的 top-5 錯誤率)以及更深的 ResNeXt-101(5.57% 的 top-5 錯誤率),這個模型幾乎有兩倍的引數和計算開銷。對於 Inception-ResNet-v2 的實驗,我們猜測可能是裁剪策略的差異導致了其報告結果與我們重新實現的結果之間的差距,因為他們的原始影象大小尚未在【38】中澄清,而我們從相對較大的影象(其中較短邊被歸一化為 352)中裁剪出 299*299 大小的區域。SE-Inception-ResNet-v2 (4.79%的 top-5 錯誤率)比我們重新實現的 Inception-ResNet-v2(5.21%的 top-5 錯誤率)要低 0.42%(相對改進了 8.1%)也優於【38】中報告的結果。每個網路的優化曲線如圖5所示,說明了在整個訓練過程中 SE塊產生了一致的改進。 最後,我們評估了兩個代表模型MobileNet【13】和 ShuffleNet【52】的體系結構,在表3中展示了 SE 塊可以持續改善了準確性大幅增加計算成本較低。這些實驗證明改進由 SE 塊可用於結合廣泛的架構。此外,這個結果也適用於 殘差和非殘差基礎的模型。
最後,我們評估了兩個代表模型MobileNet【13】和 ShuffleNet【52】的體系結構,在表3中展示了 SE 塊可以持續改善了準確性大幅增加計算成本較低。這些實驗證明改進由 SE 塊可用於結合廣泛的架構。此外,這個結果也適用於 殘差和非殘差基礎的模型。

ILSVRC 2017 分類競賽的結果。SENets是我們贏得第一名的基礎網路。我們獲勝輸出由一小群 SENets組成,他們採用標準的多尺度和多裁剪影象融合策略,在測試集上獲得了2.251% 的 top-5 錯誤率。這個結果表示在 2016年獲勝輸入(2.99%的 top-5錯誤率)的基礎上相對改進了 ~25%。我們的高效能網路之一是將 SE塊與修改後的 ResNeXt【43】整合在一起構造的(附錄A提供了這些修改的細節)。在表3中我們提出的架構與最新的模型在ImageNet驗證集上進行了比較。我們的毛線哦在每一張影象使用 224*224 中間裁剪評估(短邊首先歸一化到 256)取得了 18.68%的 top-1 錯誤率和 4.47% 的 top-5錯誤率。為了與以前的模型進行公平的比較,我們也提供了 320*320 的中心裁剪影象評估,在 top-1(17.28%)和 top-5(3.79%)的錯誤率度量中獲得了最低的錯誤率。
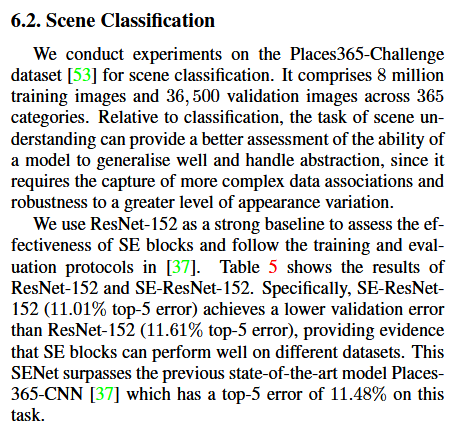
6.2 場景分類
ImageNet 資料集的大部分由單個物件支配的影象組成。為了能在更多的場景評估模型。
我們考慮在Places-365 挑戰資料上的場景分類,它包含 800萬訓練圖片和 是365個場景的36500 張驗證圖片。相對於分類,場景任務可以提供更好的理解的能力評估模型很好地概括和抽象處理,因為它需要更復雜的資料關聯和魯棒性的捕獲更大程度的外觀變化。
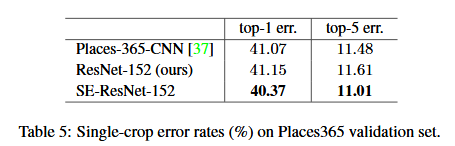
我們使用 ResNet-152 作為一個強大的基線評估 SE 塊,並按照【37】中的評估協議。表5顯示了結果 ResNet-152 和 SE-ResNet-152.具體來說,SE-ResNet-152(前5誤差 11.01%)達到驗證錯誤低於 ResNet-152(11.61% 五大錯誤),提供證據表明 SE 塊可以執行不同的資料集。這個 SENet 在任務Places-365-CNN 的 top-5 錯誤率為 11.48%。超過目前最先進的模型的。


6.3 在COCO上的目標檢測
我們在目標檢測任務中使用COCO資料集進一步評估 SE塊的普遍原理,其中COCO資料集包含 80k 訓練影象和 40k 驗證影象,我們使用 Faster R-CNN 作為檢測方法並且遵循【10】的基本實現。
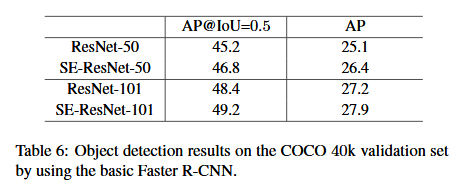
在這裡,我們的目的是評估使用SE-ResNet取代ResNet基本架構的好處,以便可以改進歸因於更好的表徵。表6顯示了通過使用 ResNet-50, ResNet-101 和他們的 SE塊的副本 在驗證集上的測試,結果分別為:SE-ResNet-50 超出了 ResNet-50模型 1.3%(大概有 5.2% 的提升)在COCO標準AP評估。並且在 IoU=0.5時有 1.6%AP。更重要的是,SE塊能夠在更深層次架構 ResNet-101中獲益,在AP評估中提高了 0.7%(大概 2.6%的提升)。


6.4 分析和解釋
減少比率。公式(5)中引入的減少比率 r 是一個重要的超引數。它允許我們改變模型中 SE塊的容量和計算成本。為了研究這種關係,我們基於 SE-ResNet-50 架構進行一系列不同 r 值的實驗。表5中的比較表明,效能並沒有隨著容量的增加而單調上升。這可能是使SE塊能夠過度擬合訓練集通道依賴性的結果。尤其是我們發現設定 r=16 在精度和複雜度之間取得了很好地平衡,因此我們將這個值用於所有的實驗。
激勵的作用。雖然 SE 塊從經驗上顯示出其可以改善網路效能,但我們也想了解自門激勵機制在實踐中是如何運作的。為了更清楚的描述 SE塊的行為,本節我們研究 SE-ResNet-50 模型的樣本啟用,並考察他們在不同塊不同類別下的分佈情況。具體而言,我們從 ImageNet資料集中抽取了四個類,這些類表現出語義和外觀多樣性,即金魚,哈巴狗,狍和懸崖(圖7顯示了這些類別的示例影象),然後,我們從驗證集中為每個類抽取 50 個樣本,並計算每個階段最後的 SE塊中 50個均勻取樣通道的平均啟用(緊接著在下采樣之前),並在圖8中繪製他們的分佈。作為參考,我們也繪製所有 1000 個類的平均啟用分佈。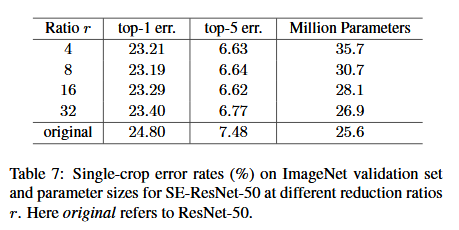
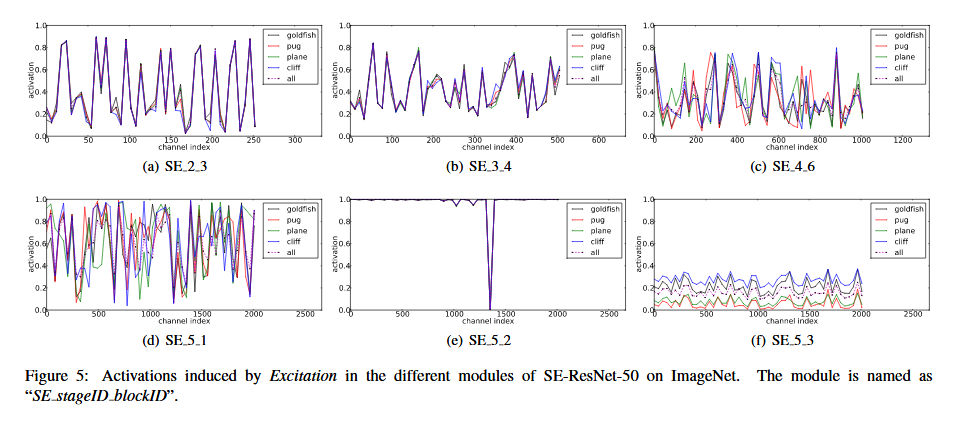


我們對SENets 中 Excitation 的作用提出以下三點看法。首先,不同類別的分佈在較低層中幾乎相同、例如,SE_2_3。這表明在網路的最初階段特徵通道的重要性很可能由不同的類別共享。然而有趣的是,第二個觀察結果是在更大的深度,每個通道的值變得更具類別特定性,因為不同類別對特徵的判別性值具有不同的偏好。SE_4_6 和 SE_5_1。這兩個觀察結果與以前的研究結果是一致的,即低層特徵通常更普遍(即分類中不可知的類別),而高層特徵具有更高的特異性。因此,表示學習從 SE塊引起的中心校準中收益,其自適應地促進特徵提取和專業化到所需要的程度。最後,我們在網路的最後階段觀察到一個有些不同的線性。SE_5_2呈現出朝向飽和狀態的有趣趨勢,其實大部分啟用接近於1,其餘啟用接近於0.在所有啟用值取1的點處,該塊將成為標準殘差塊。在網路的末端 SE_5_3中(在分類器之前緊接著是全域性池化),類似的模式出現在不同的類別上,尺度上只有輕微的變化(可以通過分類器來調整)。這表明,SE_5_2和 SE_5_3 在為網路提供重新校準方面比前面的塊更不重要。這一發現與第四節實證研究的結果是一致的,這表明,通過刪除最後一個階段的 SE 塊,總體引數數量可以顯著減少,效能只有一點損失。

7,總結
在本文中,我們提出了SE塊,這是一種新穎的架構單元,旨在通過使網路能夠執行動態通道特徵重新校準來提高網路的表達能力。大量的實驗證明了 SENets 的有效性,其在多個數據集上取得了最先進的效能。此外,他們還提供了一些關於以前架構在建模通道特徵依賴性上的侷限性的洞察,我們希望可能證明 SENets 對其他需要強判別性特徵的任務是有用的。最後,由 SE 塊引起的特徵重要性可能有助於相關領域,例如為了壓縮的網路修剪。
&n