
人工智慧(一):技術發展史
2018年11月24日星期六
我分六篇文章,大概把我學到的人工智慧課程給大家介紹一下,與君共享。
這六篇文章會從人工智慧的歷史開始講起,然後機器學習的核心方法——SVM的基本知識,再講決策樹的相關知識,最後講近幾年非常受歡迎的深度學習。
人工智慧是利用智慧學習演算法,將大量資料中的經驗來改善系統自身的效能,從而實現人類智慧所能作的事情。可以這麼說,人工智慧離不開資料分析和機器學習,研究智慧資料分析的理論和方法已經成為人工智慧的必要基礎之一。人工智慧是電腦科學的一個分支,它企圖瞭解智慧的實質,並生產出一種新的能以人類智慧相似的方式做出反應的智慧機器,該領域的研究包括機器人、語言識別、影象識別、自然語言處理和專家系統等。人工智慧從誕生以來,理論和技術日益成熟,應用領域也不斷擴大,可以設想,未來人工智慧帶來的科技產品,將會是人類智慧的“容器”。人工智慧可以對人的意識、思維的資訊過程的模擬。人工智慧不是人的智慧,但能像人那樣思考、也可能超過人的智慧。
人工智慧的開始始終繞不開艾倫·麥席森·圖靈(Alan Mathison Turing,1912年6月23日-1954年6月7日)這個人,作為一個二戰的英雄,一個偉大的數學家,密碼學家,邏輯學家,他有著獨特的想法,抽象的思維,傳奇的經歷(他的個人經歷可以看2014年的電影《模仿遊戲》,一個戰爭勝利背後的英雄)。
1950年,阿蘭·麥席森·圖靈提出關於機器思維的問題,他的論文“計算機和智慧(Computingmachiery and intelligence),引起了廣泛的注意和深遠的影響。1950年10月,圖靈發表論文《機器能思考嗎》。這一劃時代的作品,使圖靈贏得了“人工智慧之父”的桂冠。也宣告了人工智慧(AI)時代的到來。
當然,事物的發展絕非偶然,AI時代的到來肯定也有著歷史的必然,非常古老的歷史我們就不談了,直接從圖靈開始,我們以時間發展的軌跡來介紹其中技術的演變,我在以後的文章中再詳細介紹其中一些關鍵的人物,讓我們膜拜大神吧。

一、1950-1970年代,人工智慧的“推理時代”。
赫本於1949年基於神經心理學的學習機制開啟機器學習的第一步。此後被稱為Hebb學習規則。Hebb學習規則是一個無監督學習規則,這種學習的結果是使網路能夠提取訓練集的統計特性,從而把輸入資訊按照它們的相似性程度劃分為若干類。這一點與人類觀察和認識世界的過程非常吻合,人類觀察和認識世界在相當程度上就是在根據事物的統計特徵進行分類。
![]()
從上面的公式可以看出,權值調整量與輸入輸出的乘積成正比,顯然經常出現的模式將對權向量有較大的影響。在這種情況下,Hebb學習規則需預先定置權飽和值,以防止輸入和輸出正負始終一致時出現權值無約束增長。
Hebb學習規則與“條件反射”機理一致,並且已經得到了神經細胞學說的證實。比如巴甫洛夫的條件反射實驗:每次給狗餵食前都先響鈴,時間一長,狗就會將鈴聲和食物聯絡起來。以後如果響鈴但是不給食物,狗也會流口水(當然這個實驗也被認為是廣告學、神經學的開始)。
1950年,阿蘭·圖靈創造了圖靈測試來判定計算機是否智慧。圖靈測試認為,如果一臺機器能夠與人類展開對話(通過電傳裝置)而不能被辨別出其機器身份,那麼稱這臺機器具有智慧。這一簡化使得圖靈能夠令人信服地說明“思考的機器”是可能的。

2014年6月8日,一個叫做尤金·古斯特曼的聊天機器人成功讓人類相信它是一個13歲的男孩,成為有史以來首臺通過圖靈測試的計算機。這被認為是人工智慧發展的一個里程碑事件。但是這比圖靈自己預測的時間晚了整整14年。
1956年夏季,以麥卡賽、明斯基、羅切斯特和申農等為首的一批有遠見卓識的年輕科學家在一起聚會,共同研究和探討用機器模擬智慧的一系列有關問題,並首次提出了“人工智慧”這一術語,它標誌著“人工智慧”這門新興學科的正式誕生。
1957年,羅森·布拉特基於神經感知科學背景提出了第二模型,非常的類似於今天的機器學習模型。這在當時是一個非常令人興奮的發現,它比赫布的想法更適用。基於這個模型羅森·布拉特設計出了第一個計算機神經網路——感知機(the perceptron),它模擬了人腦的運作方式。羅森·布拉特對感知機的定義如下:
感知機旨在說明一般智慧系統的一些基本屬性,它不會因為個別特例或通常不知道的東西所束縛住,也不會因為那些個別生物有機體的情況而陷入混亂。
The perceptron is designed to illustrate some of the fundamental properties of intelligent systems in general, without becoming too deeply enmeshed in the special, and frequently unknown, conditions which hold for particular biological organisms.
3年後,維德羅首次使用Delta學習規則(即最小二乘法)用於感知器的訓練步驟,創造了一個良好的線性分類器。
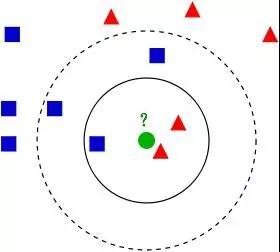
1967年,最近鄰演算法(The nearest neighbor algorithm)出現,使計算機可以進行簡單的模式識別。kNN演算法的核心思想是如果一個樣本在特徵空間中的k個最相鄰的樣本中的大多數屬於某一個類別,則該樣本也屬於這個類別,並具有這個類別上樣本的特性。這就是所謂的“少數聽從多數”原則。
1969年馬文·明斯基提出了著名的XOR問題,指出感知機線上性不可分的資料分佈上是失效的。此後神經網路的研究者進入了寒冬,直到 1980 年才再一次復甦。
從60年代中到70年代末,機器學習的發展步伐幾乎處於停滯狀態。無論是理論研究還是計算機硬體限制,使得整個人工智慧領域的發展都遇到了很大的瓶頸。雖然這個時期溫斯頓(Winston)的結構學習系統和海斯·羅思(Hayes Roth)等的基於邏輯的歸納學習系統取得較大的進展,但只能學習單一概念,而且未能投入實際應用。
這一時期,一般認為只要機器被賦予邏輯推理能力就可以實現人工智慧。不過此後人們發現,只是具備了邏輯推理能力,機器還遠遠達不到智慧化的水平。 60年代末,70年代初神經網路學習機因理論缺陷未能達到預期效果而轉入低潮。這個時期的研究目標是模擬人類的概念學習過程,並採用邏輯結構或圖結構作為機器內部描述。機器能夠採用符號來描述概念(符號概念獲取),並提出關於學習概念的各種假設。事實上,這個時期整個AI領域都遭遇了瓶頸。當時的計算機有限的記憶體和處理速度不足以解決任何實際的AI問題。要求程式對這個世界具有兒童水平的認識,研究者們很快發現這個要求太高了:1970年沒人能夠做出如此巨大的資料庫,也沒人知道一個程式怎樣才能學到如此豐富的資訊。可以說是計算能力的滯後導致了AI技術的停滯,這個階段儘管學術思想已經達到很高的水平,但是工業界的發展嚴重滯後,科學與技術是相輔相成的,任何一方發展滯後都會拖累另一方的發展。
二、1970-1990年代,人工智慧的”知識工程“時代。
這一時期,人們認為要讓機器變得有智慧,就應該設法讓機器學習知識,於是計算機系統得到了大量的開發。後來人們發現,把知識總結出來再灌輸給計算機相當困難。舉個例子來說,想要開發一個疾病診斷的人工智慧系統,首先要找好多有經驗的醫生總結出疾病的規律和知識,隨後讓機器進行學習,但是在知識總結的階段已經花費了大量的人工成本,機器只不過是一臺執行知識庫的自動化工具而已,無法達到真正意義上的智慧水平進而取代人力工作。
偉博斯在1981年的神經網路反向傳播(BP)演算法中具體提出多層感知機模型(即著名的“人工神經網路”,ANN)。雖然BP演算法早在1970年就已經以“自動微分的反向模型(reverse mode of automatic differentiation)”為名提出來了,但直到此時才真正發揮效用,並且直到今天BP演算法仍然是神經網路架構的關鍵因素。有了這些新思想,神經網路的研究又加快了。
在1985-1986年,神經網路研究人員(魯梅爾哈特,辛頓,威廉姆斯-赫,尼爾森)相繼提出了使用BP演算法訓練的多引數線性規劃(MLP)的理念,成為後來深度學習的基石。
在另一個譜系中,昆蘭於1986年提出了一種非常出名的機器學習演算法,我們稱之為“決策樹”,更具體的說是ID3演算法。這是另一個主流機器學習演算法的突破點。此外ID3演算法也被髮布成為了一款軟體,它能以簡單的規劃和明確的推論找到更多的現實案例,而這一點正好和神經網路黑箱模型相反。
決策樹是一個預測模型,他代表的是物件屬性與物件值之間的一種對映關係。樹中每個節點表示某個物件,而每個分叉路徑則代表的某個可能的屬性值,而每個葉結點則對應從根節點到該葉節點所經歷的路徑所表示的物件的值。決策樹僅有單一輸出,若欲有複數輸出,可以建立獨立的決策樹以處理不同輸出。資料探勘中決策樹是一種經常要用到的技術,可以用於分析資料,同樣也可以用來作預測。
在ID3演算法提出來以後,研究社群已經探索了許多不同的選擇或改進(如ID4、迴歸樹、CART演算法等),這些演算法仍然活躍在機器學習領域中。

1990年, Schapire最先構造出一種多項式級的演算法,這就是最初的Boosting演算法。一年後 ,Freund提出了一種效率更高的Boosting演算法。但是,這兩種演算法存在共同的實踐上的缺陷,那就是都要求事先知道弱學習演算法學習正確的下限。
1992年,支援向量機(SVM)的出現是機器學習領域的另一大重要突破,該演算法具有非常強大的理論地位和實證結果。在90年代曾風靡整個資料探勘、機器學習、模式識別領域,至今依然很火熱。那一段時間機器學習研究也分為NN和SVM兩派。然而,在2000年左右提出了帶核函式的支援向量機後。SVM在許多以前由NN佔據的任務中獲得了更好的效果。此外,SVM相對於NN還能利用所有關於凸優化、泛化邊際理論和核函式的深厚知識。因此SVM可以從不同的學科中大力推動理論和實踐的改進(當然現在SVM依然具有強大的生命力,深度學習演算法無法解決問題時,SVM依然是很好的工具)。

神經網路與支援向量機一直處於“競爭”關係。SVM應用核函式的展開定理,無需知道非線性對映的顯式表示式;由於是在高維特徵空間中建立線性學習機,所以與線性模型相比,不但幾乎不增加計算的複雜性,而且在某種程度上避免了“維數災難”(大概意思就是在高維空間質量會無限逼近他的表面,這是多麼恐怖的事情,你的面板破了一個口,會發現自己是空的)。
而神經網路遭受到又一個質疑,通過Hochreiter等人1991年和Hochreiter等人在2001年的研究表明在應用BP演算法學習時,NN神經元飽和後會出現梯度損失(gradient loss)的情況。簡單地說,早先的神經網路演算法比較容易過訓練,大量的經驗引數需要設定;訓練速度比較慢,在層次比較少(小於等於3)的情況下效果並不比其它方法更優,因此這一時期NN與SVM相比處於劣勢。

三、2000年至今,人工智慧的”資料探勘“時代。
隨著各種機器學習演算法的提出和應用,特別是深度學習技術的發展,人們希望機器能夠通過大量資料分析,從而自動學習出知識並實現智慧化水平。這一時期,隨著計算機硬體水平的提升,大資料分析技術的發展,機器採集、儲存、處理資料的水平有了大幅提高。特別是深度學習技術對知識的理解比之前淺層學習有了很大的進步,Alpha Go和中韓圍棋高手過招大幅領先就是目前人工智慧的高水平代表之一。
2001年,決策樹模型由佈雷曼博士提出,它是通過整合學習的思想將多棵樹整合的一種演算法,它的基本單元是決策樹,而它的本質屬於機器學習的一大分支——整合學習(Ensemble Learning)方法。隨機森林的名稱中有兩個關鍵詞,一個是“隨機”,一個就是“森林”。“森林”我們很好理解,一棵叫做樹,那麼成百上千棵就可以叫做森林了,這樣的比喻還是很貼切的,其實這也是隨機森林的主要思想—整合思想的體現。
其實從直觀角度來解釋,每棵決策樹都是一個分類器(假設現在針對的是分類問題),那麼對於一個輸入樣本,N棵樹會有N個分類結果。而隨機森林集成了所有的分類投票結果,將投票次數最多的類別指定為最終的輸出,這就是一種最簡單的 Bagging 思想。
在機器學習發展分為兩個部分,淺層學習(Shallow Learning)和深度學習(Deep Learning)。淺層學習起源上世紀20年代人工神經網路的反向傳播演算法的發明,使得基於統計的機器學習演算法大行其道,雖然這時候的人工神經網路演算法也被稱為多層感知機,但由於多層網路訓練困難,通常都是隻有一層隱含層的淺層模型。
神經網路研究領域領軍者Hinton在2006年提出了神經網路Deep Learning演算法(即深度學習),使神經網路的能力大大提高,向支援向量機(SVM)發出挑戰。 2006年,機器學習領域的泰斗Hinton和他的學生Salakhutdinov在頂尖學術刊物《Scince》上發表了一篇文章,開啟了深度學習在學術界和工業界的浪潮。(隨後,隨著工業界GPU在大型計算機上的應用,深度學習迎來了爆發)
這篇文章有兩個主要的訊息:1)很多隱層的人工神經網路具有優異的特徵學習能力,學習得到的特徵對資料有更本質的刻劃,從而有利於視覺化或分類;2)深度神經網路在訓練上的難度,可以通過“逐層初始化”( layer-wise pre-training)來有效克服,在這篇文章中,逐層初始化是通過無監督學習實現的。

當前統計學習領域最熱門方法主要有deep learning和SVM(supportvector machine),它們是統計學習的代表方法。可以認為神經網路與支援向量機都源自於感知機。
神經網路模型貌似能夠實現更加艱難的任務,如目標識別、語音識別、自然語言處理等。但是,應該注意的是,這絕對不意味著其他機器學習方法的終結。儘管深度學習的成功案例迅速增長,但是對這些模型的訓練成本是相當高的,調整外部引數也是很麻煩。同時,SVM的簡單性促使其仍然最為廣泛使用的機器學習方式。

現在深度學習已經應用在各類學科之中,並且很多都取得了很好的效果。
2016年3月,阿爾法圍棋與圍棋世界冠軍、職業九段棋手李世石進行圍棋人機大戰,以4比1的總比分獲勝;2016年末2017年初,該程式在中國棋類網站上以“大師”(Master)為註冊帳號與中日韓數十位圍棋高手進行快棋對決,連續60局無一敗績;2017年5月,在中國烏鎮圍棋峰會上,它與排名世界第一的世界圍棋冠軍柯潔對戰,以3比0的總比分獲勝。圍棋界公認阿爾法圍棋的棋力已經超過人類職業圍棋頂尖水平,在GoRatings網站公佈的世界職業圍棋排名中,其等級分曾超過排名人類第一的棋手柯潔。而李世石取得的那一場勝利也被認為是人類的最後一場勝利,該事件也被認為是人工智慧發展的里程碑。
筆者在這裡提一個問題,你認為“人工智慧”能取代人類嗎?
參考文獻:
http://smart.blogchina.com/507540031.html
http://blog.csdn.net/andrewseu/article/details/53488664