
大資料教程(8.3)wordcount程式執行過程的解析
上一篇部落格分享了wordcount的原始碼編寫、原理實現,本節將對wordcount在hadoop內部執行過程進行解析。
執行流程圖如下:
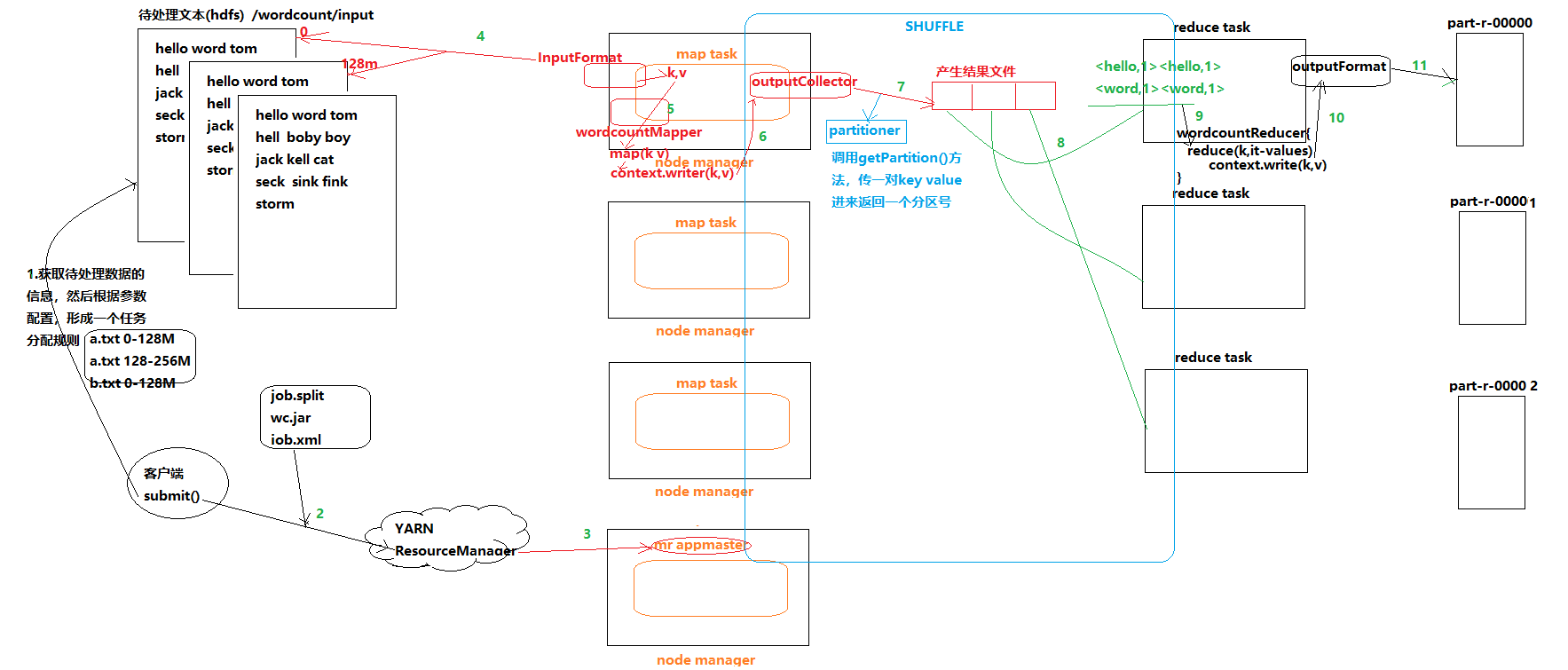
上圖中說明:mr appmaster啟動後,會根據任務分配規則進行任務的啟動,也就是map task和reduce task的啟動都由它來進行協調。當然在啟動map task和reduce task時還有很多判斷條件,如資料片的機器距離、繁忙程度等等。
最後寄語,以上是博主本次文章的全部內容,如果大家覺得博主的文章還不錯,請點贊;如果您對博主其它伺服器大資料技術或者博主本人感興趣,請關注博主部落格,並且歡迎隨時跟博主溝通交流。
相關推薦
大資料教程(8.3)wordcount程式執行過程的解析
上一篇部落格分享了wordcount的原始碼編寫、原理實現,本節將對wordcount在hadoop內部執行過程進行解析。 執行流程圖如下:
大資料教程(8.2)wordcount程式原理及程式碼實現/執行
上一篇部落格分享了mapreduce的程式設計思想,本節博主將帶小夥伴們瞭解wordcount程式的原理和程式碼實現/執行細節。通過本節可以對mapreduce程式有一個大概的認識,其實hadoop中的map、reduce程
大資料教程(8.4)移動流量分析案例
前面分享了使用mapreduce做wordcount單詞統計的實現與原理。本篇博主將繼續分享一個移動流量分析的經典案例,來幫助在實際工作中理解和使用hadoop平臺。 &n
大資料教程(7.3)namenode管理元資料的機制&datanode工作機制介紹
前面兩篇部落格介紹了HDFS客戶端讀寫資料流程,本篇博主將帶給小夥伴們namenode和datanode的工作機制的分享。
大資料教程(8.1)mapreduce核心思想
上一章介紹了hadoop的HDFS檔案系統的原理及API使用。本章博主將繼續對hadoop的mapreduce程式設計框架進行分享。 mapreduce原理篇
大資料教程(8.5)mapreduce原理之並行度
上一篇部落格介紹了mapreduce的移動流量分析的實戰案例,本篇將繼續分享mapreduce的並行度原理。 一、mapTask並行度的決定機制
大資料教程(8.6)yarn客戶端提交job的流程梳理和總結&自定義partition程式設計
上一篇部落格博主分享了mapreduce的並行原理,本篇部落格將繼續分享yarn客戶端提交job的流程和自定義partition程式設計。 一、
大資料教程(8.7)流量彙總排序的mr實現
上一章我們有講到一個mapreduce案例——移動流量排序,如果我們要將最後的輸出結果按總流量大小逆序輸出,該怎麼實現呢?本節博主將分享這個實現的過程。 一、分析 &
大資料教程(9.3)MR執行在yarn叢集流程分析&&本地模式除錯MR程式_
mapreduce在yarn叢集中流程分析: 在windows本地環境的除錯需要先安裝好windows環境,具體請看windows安裝篇;
大資料教程(9.3)MR執行在yarn叢集流程分析&&本地模式除錯MR程式_
mapreduce在yarn叢集中流程分析: 在windows本地環境的除錯需要先安裝好windows環境,具體請看windows安裝篇;
大資料教程(13.3)azkaban簡介&安裝
開發十年,就只剩下這套架構體系了! >>>
大資料教程(8.8)MR內部的shuffle過程詳解&combiner的執行機制及程式碼實現
之前的文章已經簡單介紹過mapreduce的運作流程,不過其內部的shuffle過程並未深入講解;本篇部落格將分享shuffle的全過程。
大資料教程(8.8)MR內部的shuffle過程詳解&combiner的執行機制及程式碼實現
之前的文章已經簡單介紹過mapreduce的運作流程,不過其內部的shuffle過程並未深入講解;本篇部落格將分享shuffle的全過程。
大資料教程(7.4)HDFS的java客戶端API(流處理方式)
博主上一篇部落格分享了namenode和datanode的工作原理,本章節將繼前面的HDFS的java客戶端簡單API後深度講述HDFS流處理API。 &nb
大資料教程(7.5)hadoop中內建rpc框架的使用教程
博主上一篇部落格分享了hadoop客戶端java API的使用,本章節帶領小夥伴們一起來體驗下hadoop的內建rpc框架。首先,由於hadoop的內建rpc框架的設計目的是為了內部的元件提供
大資料教程(9.4)用java -jar的方式執行mr程式
上一篇部落格分享了mapreduce在yarn上的執行流程,本篇博主將分享 1.如何使用:jar -jar的方式執行mr程式、2.如何在本地提交mapreduce程式到叢集上去執行;
大資料教程(9.5)用MR實現sql中的jion邏輯
上一篇部落格講解了使用jar -jar的方式來執行提交MR程式,以及通過修改YarnRunner的原始碼來實現MR的windows開發環境提交到叢集的方式。本篇博主將分享sql中常見的join操作。 &nbs
大資料教程(9.6)map端join實現
上一篇文章講了mapreduce配合實現join,本節博主將講述在map端的join實現; 一、需求 &n
大資料教程(13.2)Flume多個agent連線
上一節介紹了Flume如何將資料收集到hdfs檔案系統上
大資料教程(13.4)azkaban例項演示
開發十年,就只剩下這套架構體系了! >>>