
大資料教程(8.1)mapreduce核心思想
阿新 • • 發佈:2018-11-25
上一章介紹了hadoop的HDFS檔案系統的原理及API使用。本章博主將繼續對hadoop的mapreduce程式設計框架進行分享。
mapreduce原理篇
mapreduce是一個分散式運算程式的程式設計框架,是使用者開發“基於hadoop的資料分析應用”的核心框架;mapreduce的核心功能是將使用者編寫的業務邏輯程式碼和自帶的預設元件整合成一個完整的分散式運算程式,併發執行在一個hadoop叢集上;
為什麼要mapreduce:
(1).海量資料在單機上處理因為硬體資源限制,無法勝任
(2).而一旦將單機版程式擴充套件到叢集來分散式執行,將極大增加程式的複雜度和開發難度
(3).引入mapreduce框架後,開發人員可以將絕大部分工作集中在業務邏輯的開發上,而將分散式計算中的複雜性交由框架來處理
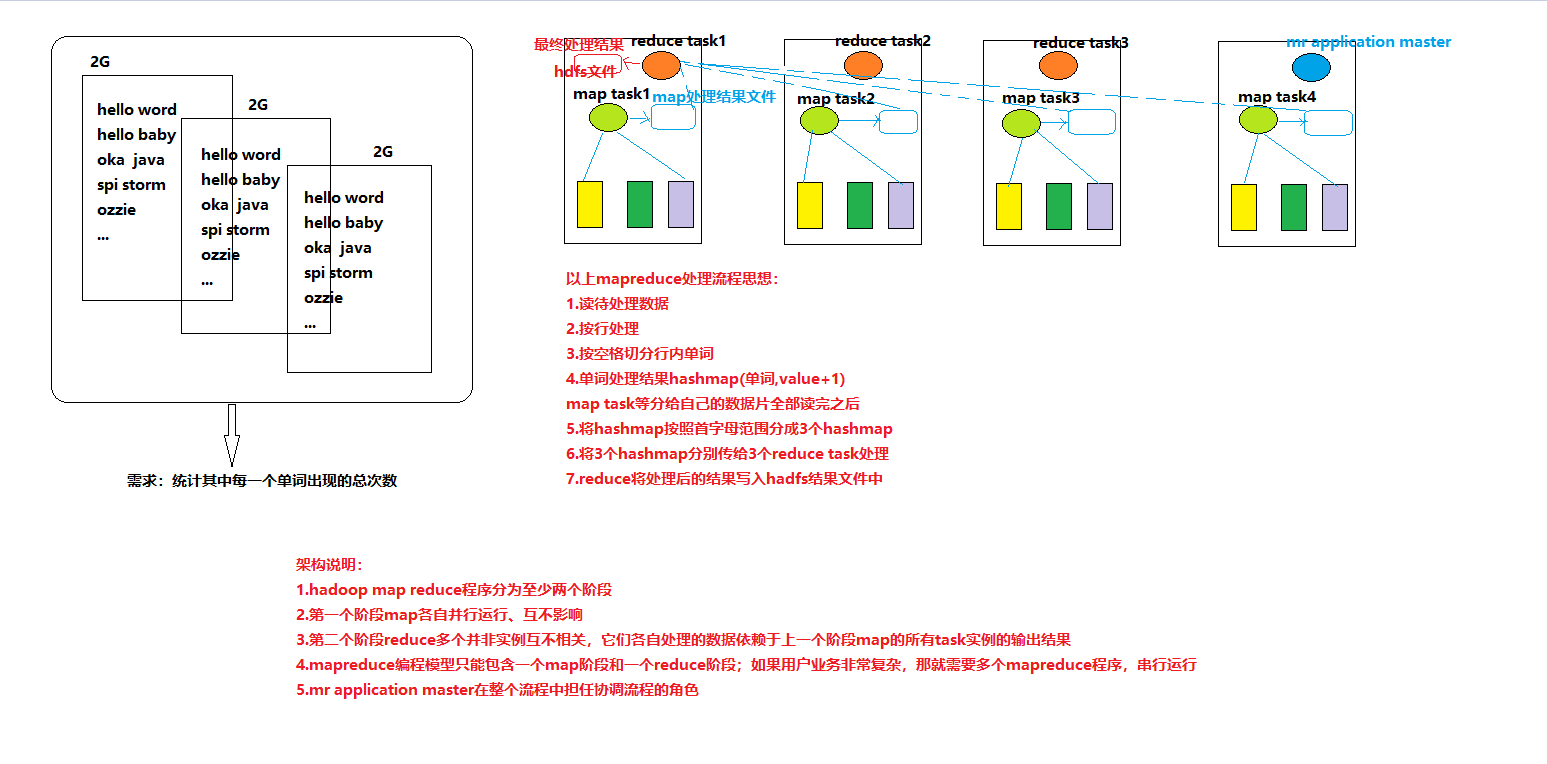
mapreduce的整體結構包含:一個完整的mapreduce程式在分散式執行時有三類例項程序;
1.MRAppMaster(mapreduce application master):負責整個程式的過程排程及狀態協調
2.MapTask:負責map階段的整個資料處理流程
3.ReduceTask:負責reduce階段的整個資料處理流程
mapredcue核心框架設計思想:
最後寄語,以上是博主本次文章的全部內容,如果大家覺得博主的文章還不錯,請點贊;如果您對博主其它伺服器大資料技術或者博主本人感興趣,請關注博主部落格,並且歡迎隨時跟博主溝通交流。