
爬取JS動態生成的URL
阿新 • • 發佈:2018-12-03
愛卡汽車論壇搜尋結果頁面:
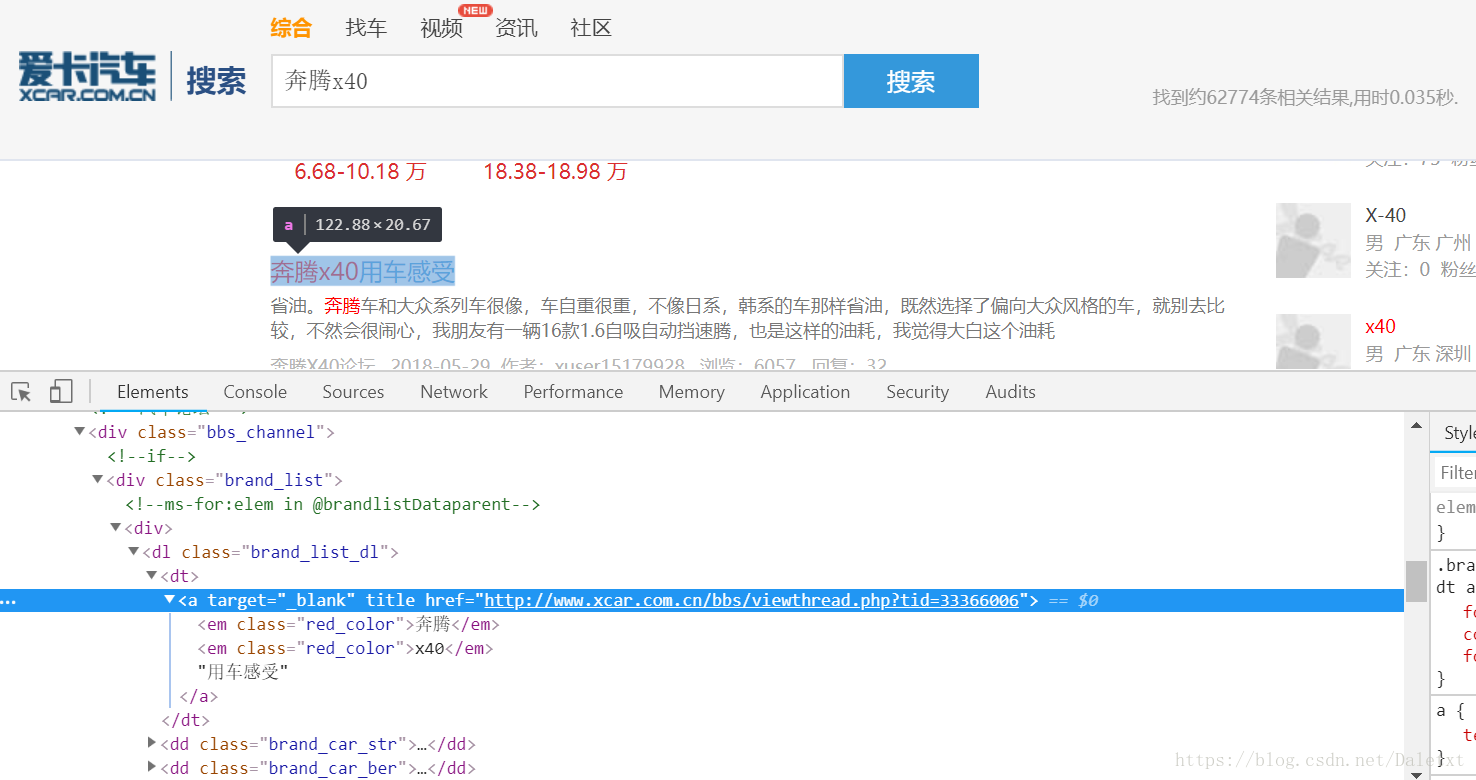
想要python爬取搜尋結果連結:a標籤中的href,但是這個url是動態生成的。
網頁原始碼:

用普通方式解析:
import urllib.request
url = "http://search.xcar.com.cn/metasearch.php#?&searchValue=奔騰x40"
data = urllib.request.urlopen(url).read()
data = data.decode('UTF-8')
print(data)解析結果:

selenium:這是一個用於web應用程測試的工具 下載方式:pip install selenium phantomjs 是一種無介面的瀏覽器,用於完成網頁的渲染 下載地址 http://phantomjs.org/download.html 解壓就可以用 開啟解壓後的檔案,找到bin下的phantomjs.exe將這個路徑放到PATH路徑下 動態解析:
from selenium import webdriver
url = "http://search.xcar.com.cn/metasearch.php#?&searchValue=奔騰x40"
driver = webdriver.PhantomJS(executable_path='E:/phantomjs/bin/phantomjs.exe')
#這個路徑就是你新增到PATH的路徑
driver.get(url)
print (driver.page_source)解析結果:

下一步如何取出: 參考文章:http://www.freebuf.com/column/142404.html 繼續: