Hadoop生態叢集之HDFS
、HDFS是什麼
二、HDFS的搭建
三、HDFS的組成
四、HDFS的儲存流程和原理
五、HDFS的shell命令
一、HDFS是什麼
HDFS是hadoop叢集中的一個分散式的我檔案儲存系統。他將多臺叢集組建成一個叢集,進行海量資料的儲存。為超大資料集的應用處理帶來了很多便利。
和其他的分散式檔案儲存系統相比他有以下優點:
高容錯:即在HDFS執行過程中,若其中一臺機器宕機了,也無需擔心資料的丟失,因為在儲存的過程中進行了備份,備份數量可以選擇,這個將在後面的部落格說明。
成本低:即使配置條件不足的情況下,都可以搭建一個HDFS,對硬體的要求不高。
易擴充套件:若出現叢集容量不足的情況,直接新增機器,進行配置即可,無需太麻煩的操作。
高吞吐量:HDFS能夠提供比較吞吐量的資料訪問,這裡是訪問不是修改
在滿足以上有點的同時,也存在一些不足:
對於對資料的訪問時間要求較高的情況下,HDFS並沒有什麼優勢,這一點會在原理上進行解釋。
不利於同時有大量的用使用者進行檔案的修改操作。
二、HDFS的平臺搭建
搭建HDFS叢集的方式有很多種,目前在企業工作中應用較多的是通過cloudera manager來對整個hadoop叢集進行搭建,同時提供一整套的監控平臺進行監控,大大提高了維護成本。但是對於初學者來說還是進行原始碼的方式安裝
這樣有助於大家更加深入的瞭解HDFS的工作原理和配置引數的作用,小編在這就通過這種方式進行安裝,當然如果有興趣的讀者,我會在接下來的時間通過cloudera manager的方式進行搭建。
搭建準備:注意這是在linux機器上進行搭建,如對如何配置linux環境的同學不動的話,可以在網上進行搜尋,小編也會更新博文給大家提供便利。
主機名:hdp-01 對應的ip地址:192.168.33.61 主機名:hdp-02 對應的ip地址:192.168.33.62 主機名:hdp-03 對應的ip地址:192.168.33.63 主機名:hdp-04 對應的ip地址:192.168.33.64
第一步:關閉防火牆
[[email protected] ~]# service iptables stop # 臨時關閉
[[email protected] ~]# chkconfig iptables off # 關閉防火牆開機自動啟動
第二步:安裝jdk,因為hdfs是通過java語言開發的,所以需要我們安裝java的執行環境
jdk下載地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
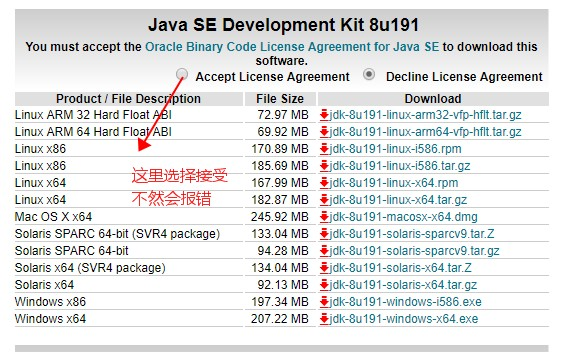
tar -zxvf jdk-8u191-linux-x64.tar.gz
對應整個叢集環境,為了方便管理可以將安裝包上傳到 /usr/local/src下面
解壓:
二、HDFS資料儲存原理
要了解HDFS資料的儲存原理,就必須知道HDFS的工作原理,通過工作原理,我們就可以得出HDFS的資料儲存原理。
hdfs有著檔案系統共同的特徵:
1、有目錄結構,頂層目錄是: /
2、系統中存放的就是檔案
3、系統可以提供對檔案的:建立、刪除、修改、檢視、移動等功能
hdfs跟普通的單機檔案系統有區別:
1、單機檔案系統中存放的檔案,是在一臺機器的作業系統中
2、hdfs的檔案系統會橫跨N多的機器
3、單機檔案系統中存放的檔案,是在一臺機器的磁碟上
4、hdfs檔案系統中存放的檔案,是落在n多機器的本地單機檔案系統中(hdfs是一個基於linux本地檔案系統之上的檔案系統)
hdfs的工作機制:簡單的講,hdfs是分散式的檔案儲存系統,它可以將一個大的檔案切塊,將這些塊儲存在不同的伺服器上。
1、客戶把一個檔案存入hdfs,其實hdfs會把這個檔案切塊後,分散儲存在N臺linux機器系統中(負責儲存檔案塊的角色:datanode)<準確來說:切塊的行為是由客戶端決定的>,切塊的大小,切塊的副本數這些都可以由
客戶端進行指定,若沒有進行指定,則HDFS會自動載入配置檔案中配置的資訊,進行切塊大小,副本數量資訊。
2、一旦檔案被切塊儲存,那麼,hdfs中就必須有一個機制,來記錄使用者的每一個檔案的切塊資訊,及每一塊的具體儲存機器(負責記錄塊資訊的角色是:name node),這樣可以方便客戶端在訪問hdfs檔案系統時準確的
找到每一塊檔案儲存在哪些節點上,將切塊的資料進行歸整,同時他又可以合理的控制磁碟IO問題。
3、為了保證資料的安全性,hdfs可以將每一個檔案塊在叢集中存放多個副本,保證當其中一臺機器宕機後,namenode可以通過記錄的副本資訊找到切塊的檔案。(到底存幾個副本,是由當時存入該檔案的客戶端指定的)
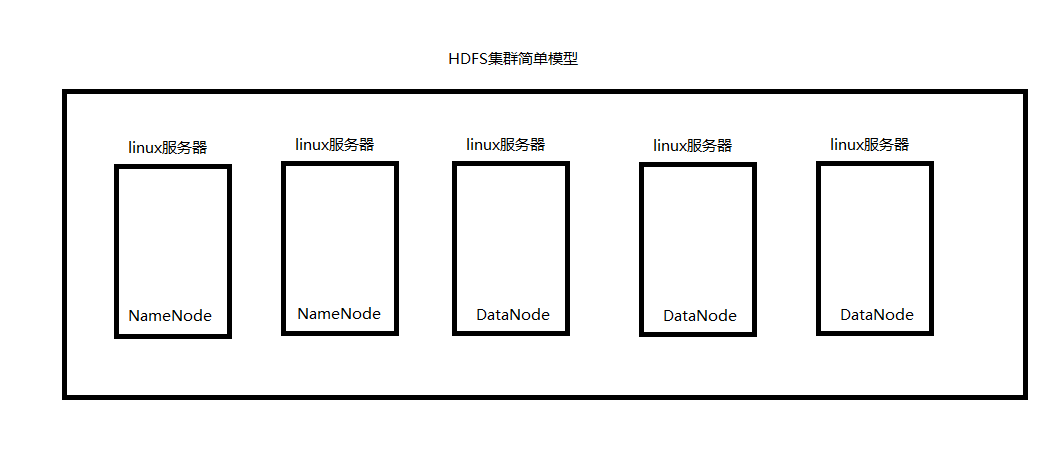
綜述:一個hdfs系統,由一臺運行了namenode的伺服器,和N臺運行了datanode的伺服器組成!
如下圖所示,就是一個簡單的HDFS分散式檔案系統的模型:
儲存檔案的詳情:請看下圖
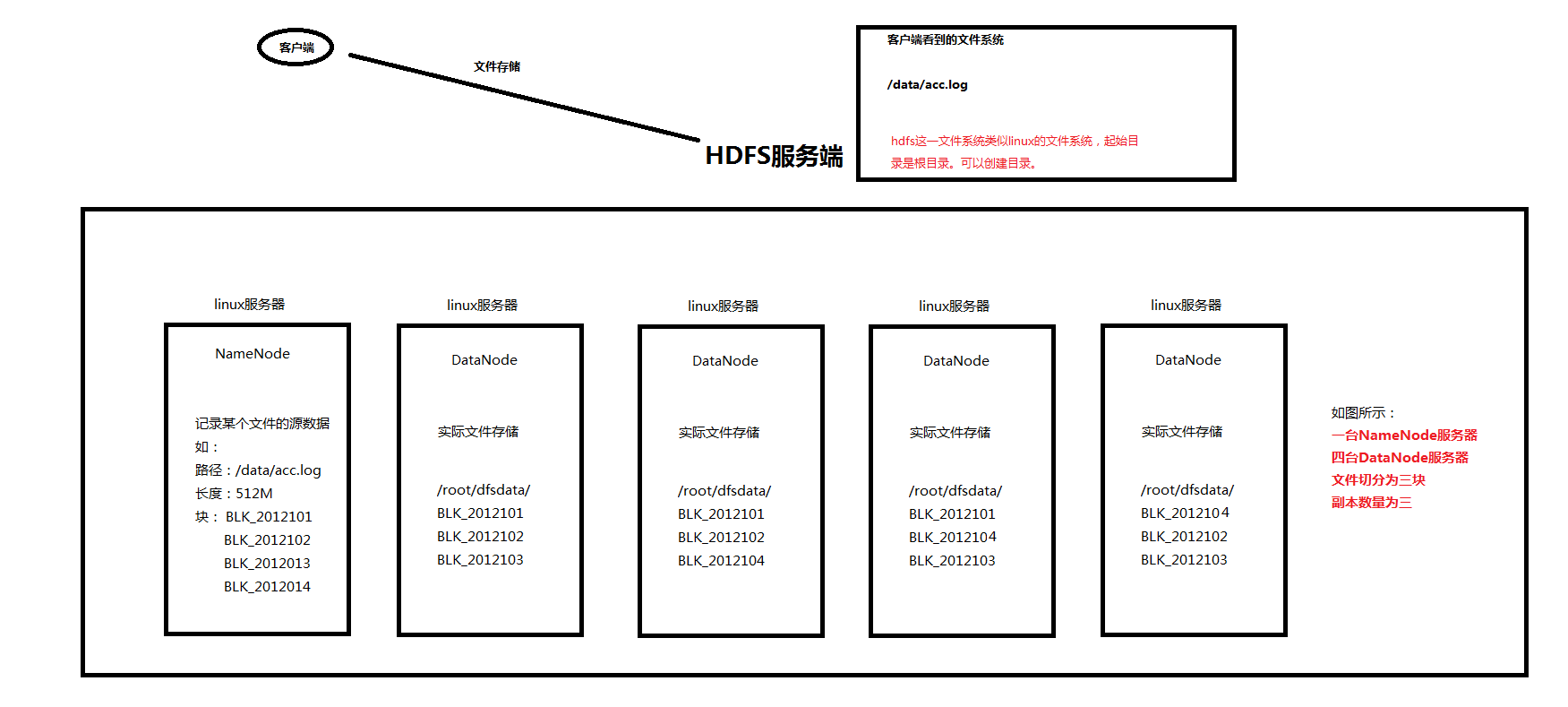
HDFS檔案儲存資訊:
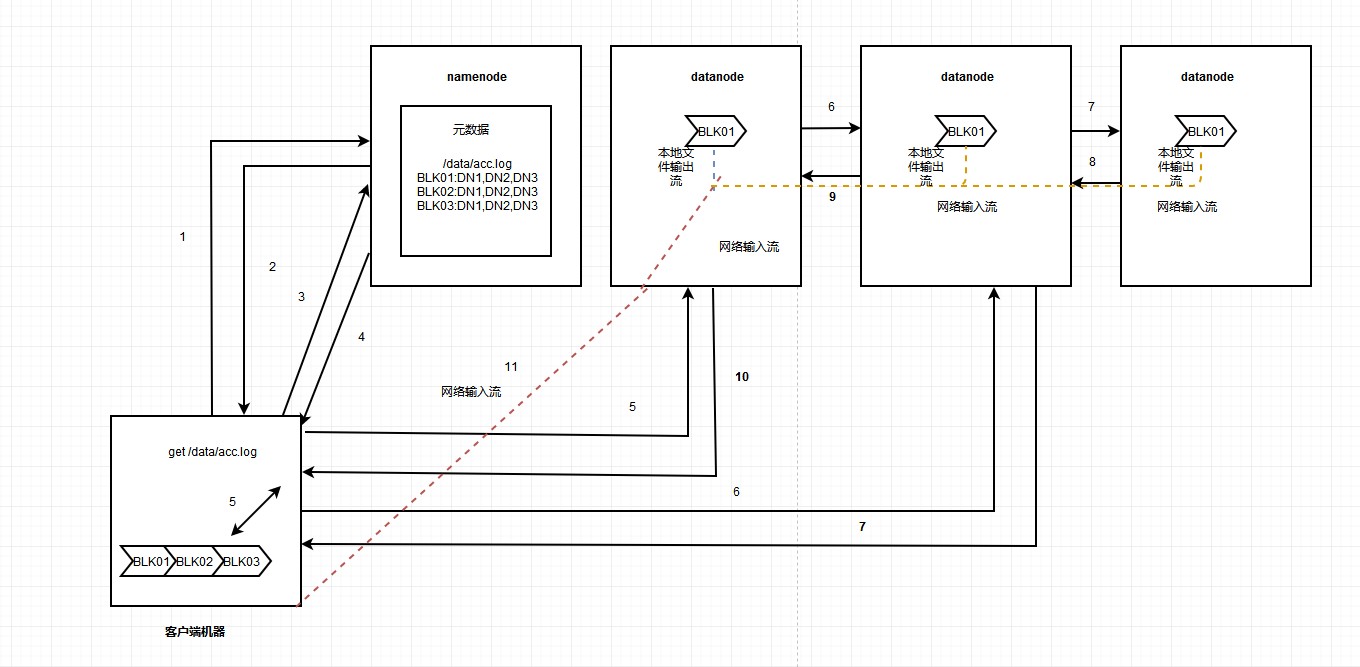
1、hdfs客戶端與服務端進行互動,將檔案儲存在hdfs叢集中。
2、hdfs服務端將客戶端傳來的檔案,根據引數進行切塊、複製,並將這些塊儲存在hdfs的datanode節點中。
3、hdfs的namenode節點記錄某個檔案的元資料(元資料包含檔案大小,檔案路徑,檔案塊儲存在哪個地方,副本資訊等)
HDFS讀取資料流程如下圖:
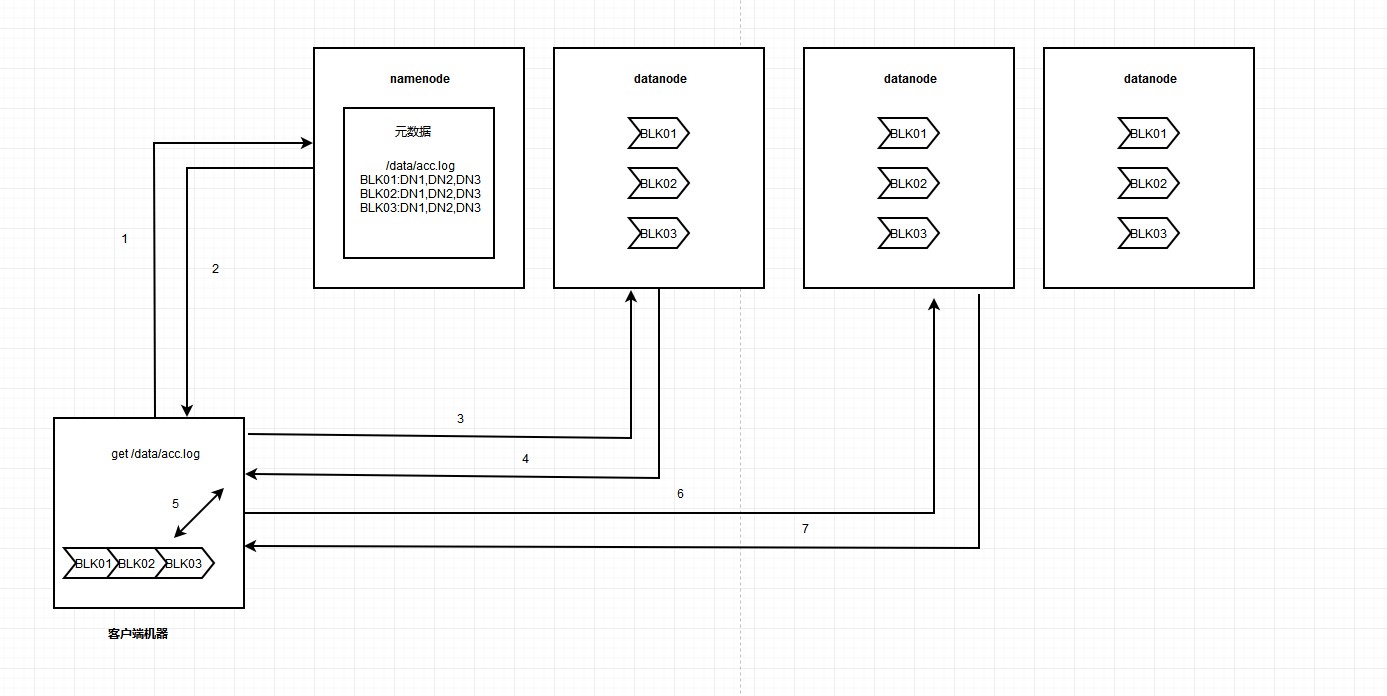
HDFS寫資料流程資料流程如下圖: