
Hadoop 叢集之HDFS HA、Yarn HA
部署叢集的原因
如果我們採用單點的偽分散式部署,那麼NN節點掛了,就不能對外提供服務。叢集的話,存在兩個NN節點,一個掛了,另外一個從standby模式直接切換到active狀態,實時對外提供服務(讀寫)。在生產上,避免出現對外服務中斷的情況,所以會考慮採用叢集部署。
HDFS HA (High availability)
單點式偽分佈:
NN
SNN secondary 1小時checkpoint
DN
HDFS HA:
NN active
NN standby 實時備份
DN
JN : JounalNode 日誌
ZKFC : zookeeperFailoverController(控制NN為active還是standby)
圖解如下:

- 過程分析
客戶端上輸入一個命令,然後NNactive節點把這個命令操作記錄寫到自己的editlog,同時JN叢集也會寫一份,NNstandby節點實時接收JN叢集的日誌,先是讀取執行log操作(重演),使得自己的元資料和activeNN節點保持一致,同時兩個NN節點都接受DN的心跳和blockreport。ZKFC監控NN的健康狀態,向ZK定期傳送心跳,使自己可以被選舉;當自己被ZK選舉為主的時候,zkfc程序通過RPC呼叫使NN的狀態變為active,對外提供實時服務。 - zookeeper 軟體
學習中:使用三臺
生產上:50臺規模以下 :7臺
50~100 9/11臺 >100 11臺
zk的部署是2n+1的方式。是選舉式投票原理,所以要配置奇數臺(zk並不是越多越好,因為考慮到zk越多,選舉誰做active的時間就會越長,會影響效率) - ZKFC zookeeperFailoverController:
在hdfs HA 中,它屬於單獨的程序,負責監控NN的健康狀態,向ZK定期傳送心跳,使自己可以被選舉;當自己被ZK選舉為主的時候,zkfc程序通過RPC呼叫使NN的狀態變為active,對外提供實時服務,這是無感知的。 - hdfs dfs -ls /命令
hdfs dfs -ls / 的 ‘/’相當於hdfs://ip:9000/的簡寫。所以在叢集環境中用這個命令就應該考慮ip具體是哪個機器的,所以用簡寫就代表是所在的那臺機器。舉例如下
NN1 active–>掛了 IP地址為192.168.1.100
NN2 standby 192.168.1.101
假如我們在192.168.1.100機器上用hdfs dfs -ls / 那麼就相當於hdfs dfs -ls hdfs://192.168.1.100:9000/ ,但是假如這臺機器掛了,我們再通過hdfs dfs -ls / 或者hdfs dfs -ls hdfs://192.168.1.100:9000/ 來執行命令已經不行了。如果說把其輸入命令改為hdfs dfs -ls hdfs://192.168.1.101:9000/ 去訪問雖然可以,但是生產上並不太可能,因為很多程式都已經打包好,不可能再去改這個命令列的對應的機器的IP地址。那麼,就有了一個對應的名稱空間 :nameservice來解決這個問題。 - 名稱空間
生產上HA命令是通過命令空間訪問的
名稱空間 :nameservice 在HA中其實並不關心哪臺機器是standby 哪臺是active。一般都是如下訪問:
名稱空間 :nameservice: ruozeclusterg5
hdfs dfs -ls hdfs://ruozeclusterg5/ 其實就相當於上圖中把兩個NN節點包起來,而對外提供的就為ruozeclusterg5,內部進行active的選舉,所以外部呼叫的時候並不關心哪個是active,只會用ruozeclusterg5去訪問,至於誰是active,內部會解決。 - ActiveNN:
操作記錄寫到自己的editlog,同時JN叢集也會寫一份;接收 DN的心跳和blockreport - StandbyNN:
接收JN叢集的日誌,先是讀取執行log操作(重演),使得自己的元資料和activenn節點保持一致,接收 DN的心跳和blockreport。 - JounalNode:
用於 active standby nn節點的同步資料,部署是2n+1個(3個/5個–>7個)JounalNode節點出問題比較少。最容易出問題的就是NNactive狀態,比如出現網路抖動導致延遲,這樣就可能會出現誤認為active 節點掛掉,把standby節點提升為active,這時候就可能出現兩個active節點。但是這種概率非常低,因為生產上一般採用區域網,不太會網路波動出現這種問題,但也有可能出現。還有一種情況就是兩個NN都是standby狀態,然後切不起來active,那麼這兩種情況下就會出現問題。所以並不能說在生產上HA就是萬無一失的。
總結:
HA是為了解決單點問題,兩個NN通過JN叢集共享狀態,通過ZKFC 選舉active,ZKFC監控狀態,自動備援,DN會同時向active standby nn傳送心跳和塊報告.HDFS HA的部署方法有:NameNode HA With QJM (相當於共享日誌,生產上推薦的就是QJM這種)和 NameNode HA With NFS (相當於共享儲存目錄)
學習中的叢集部署
hadoop001
NN
ZKFC(與NN部署在同一臺機器上)
DN
JN
ZK
hadoop002
NN
ZKFC(與NN部署在同一臺機器上)
DN
JN
ZK
hadoop003
DN
JN
ZK
生產上的叢集:
假如還有幾臺空機器hadoop004-010 那麼就可以把001 002 上部署的DN拿下來,部署在hadoop004-010 機器上,這個是要看具體機器的配置及數量,按需分配
Yarn HA
圖解如下:
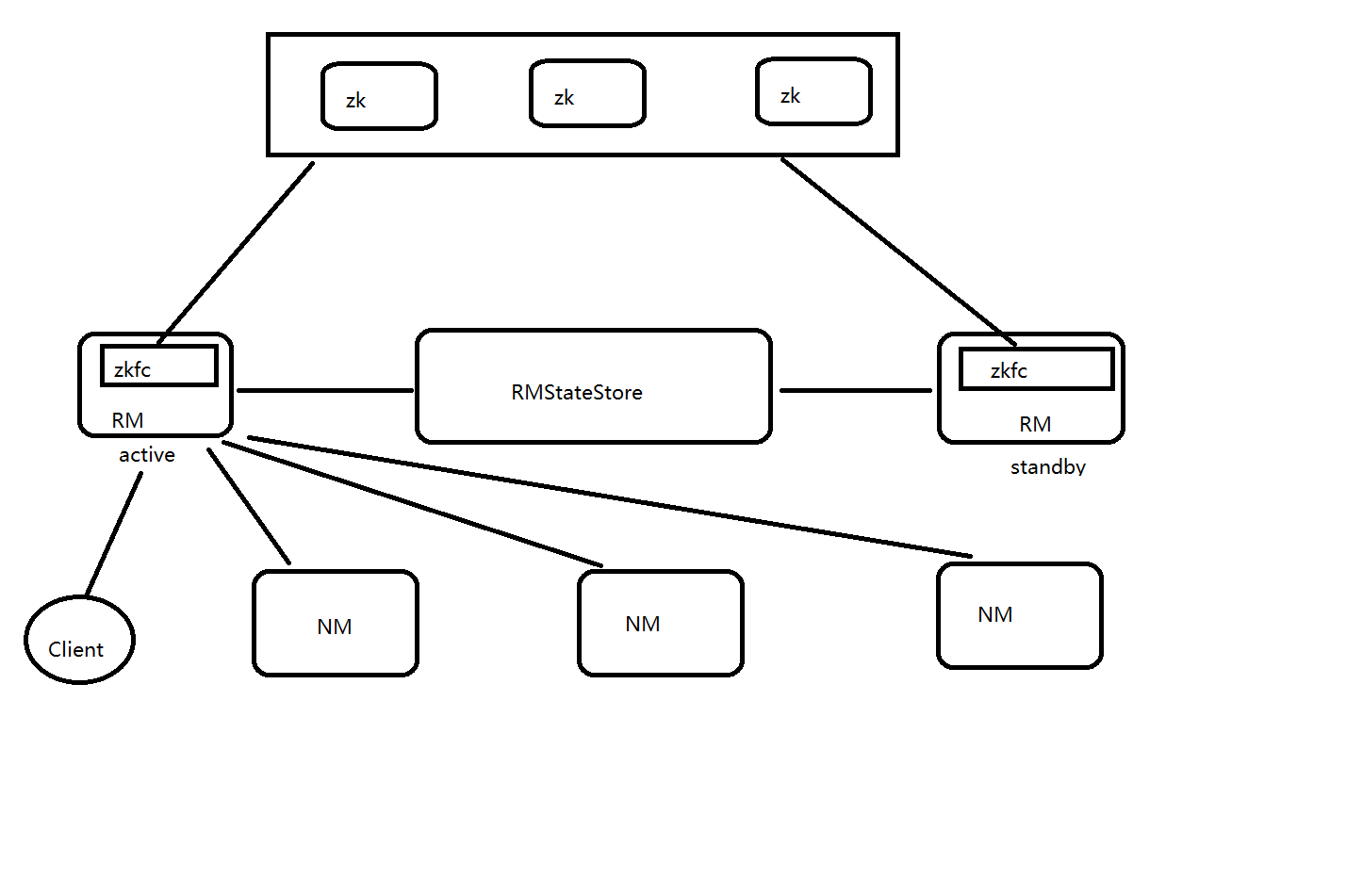
-
zkfc是在RM裡面的,只作為RM程序的一個執行緒而非獨立的守護程序來獨立存在。這個涉及到一個概念,執行緒
在yarn HA中,zkfc是執行緒,也就是RM程序的一個執行緒。所謂程序就是jps 、 ps-ef | grep xxx 能夠檢視到的,而執行緒 屬於一個程序的裡面的 除非特殊命令和工具才能看到。 包含至少一個執行緒。 -
RMStateStore:
a.RM把job資訊存在在ZK的/rmstore下(類似hdfs的根目錄,zk也有自己的根目錄),activeRM會向這個目錄寫app資訊
b.當active RM掛了,另外一個standby RM通過zkfc選舉成功為active,會從/rmstore讀取相應的作業資訊。 重新構建作業的記憶體資訊,啟動內部服務(apps manager 和資源排程),開始接收NM的心跳,構建叢集的資源資訊,並且接收客戶端的作業提交請求。 -
RM:
a.啟動時候的會向ZK的目錄?寫個lock檔案,寫成功的話,就為active,否則為standby。然後standby rm節點會一直監控這個lock檔案是否存在,假如不存在,就試圖建立,假如成功就為active。
b.接收client的請求。接收和監控NM的資源狀況彙報,負載資源的分配和排程。
c.啟動和監控ApplicationMaster(AM) on NM的container(執行在NM上面的容器裡面)
注:ApplicationsManager RM
ApplicationMaster 是JOB的老大 執行在NM的container (相當於spark的driver) -
NM:
節點的資源管理,啟動container執行task計算,上報資源,彙報task進度給AM (ApplicationMaster)
yarn HA 和hdfs HA之間的區別
- hdfs中zkfc是屬於程序。yarn中zkfc是屬於RM程序中的一個執行緒
- dn和nm的區別:DN會同時給NN active和standby都發送心跳包和塊報告。NM只會向NN active傳送心跳包
- hdfs HA叢集啟動的程序順序:
- 架構:
相關推薦
Hadoop 叢集之HDFS HA、Yarn HA
部署叢集的原因 如果我們採用單點的偽分散式部署,那麼NN節點掛了,就不能對外提供服務。叢集的話,存在兩個NN節點,一個掛了,另外一個從standby模式直接切換到active狀態,實時對外提供服務(讀寫)。在生產上,避免出現對外服務中斷的情況,所以會考慮採用叢集部署。 HDFS HA
Hadoop 叢集之HDFS HA、Yarn HA
部署叢集的原因 如果我們採用單點的偽分散式部署,那麼NN節點掛了,就不能對外提供服務。叢集的話,存在兩個NN節點,一個掛了,另外一個從standby模式直接切換到active狀態,實時對外提供服務(讀寫)。在生產上,避免出現對外服務中斷的情況,所以會考慮採用叢集
hadoop叢集搭建HDFS、HA、 YARN
hadoop2.0已經發布了很多穩定版本,增加了很多特性,比如HDFS HA、YARN等。最新的hadoop-2.7.2又增加了YARN HA 1、環境準備 修改主機名、IP地址。這些在之前部落格有提過就不再寫了。 配置IP地址和主機名對映關係。 sud
Hadoop(25)-高可用叢集配置,HDFS-HA和YARN-HA
一. HA概述 1. 所謂HA(High Available),即高可用(7*24小時不中斷服務)。 2. 實現高可用最關鍵的策略是消除單點故障。HA嚴格來說應該分成各個元件的HA機制:HDFS的HA和YARN的HA。 3. Hadoop2.0之前,在HDFS叢集中NameNode存在單點故障(SPOF
一鍵配置高可用Hadoop叢集(hdfs HA+zookeeper HA)
準備環境 3臺節點,主節點 建議 2G 記憶體,兩個從節點 1.5G記憶體, 橋接網路 關閉防火牆 配置ssh,讓節點之間能夠相互 ping 通 準備 軟體放到 autoInstall 目錄下,已存放 hadoop-2.9.0.tar.g
Hadoop叢集之Hive HA 安裝配置
Hive是基於Hadoop構建的一套資料倉庫分析系統,它提供了豐富的SQL查詢方式來分析儲存在Hadoop 分散式檔案系統中的資料。其在Hadoop的架構體系中承擔了一個SQL解析的過程,它提供了對外
Hadoop生態叢集之HDFS
、HDFS是什麼 二、HDFS的搭建 三、HDFS的組成 四、HDFS的儲存流程和原理 五、HDFS的shell命令 一、HDFS是什麼 HDFS是hadoop叢集中的一個分散式的我檔案儲存系統。他將多臺叢集組建成一個叢集,進行海量資料的儲存。為超大資料集的應用處理帶來了很多便
HDFS HA和Yarn HA的區別
文章目錄 1. ZKFC 2.從節點 1. ZKFC HDFS中ZKFC作為單獨的程序 Yarn中ZKFC是RM中的執行緒 2.從節點 HDFS中的DataNod
Hadoop叢集搭建(HDFS和Yarn叢集)
hadoop叢集搭建(HDFS和Yarn叢集) 1.安裝hadoop2.7.4 上傳hadoop的安裝包到伺服器 hadoop-2.7.4-with-centos-6.7.tar.gz 解壓安裝包 tar zxvf hadoop-2.7.4-wit
hadoop學習之HDFS(2.5):windows下eclipse遠端連線linux下的hadoop叢集並測試wordcount例子
windows下eclipse遠端連線linux下的hadoop叢集不像在linux下直接配置eclipse一樣方便,會出現各種各樣的問題,處處是坑,連線hadoop和執行例子時都會出現問題,而網上的
Hadoop框架之HDFS的shell操作
技術分享 登錄 自動 訪問hdfs tro 分布式文件系 屬組 3-9 統計文件 既然HDFS是存取數據的分布式文件系統,那麽對HDFS的操作,就是文件系統的基本操作,比如文件的創建、修改、刪除、修改權限等,文件夾的創建、刪除、重命名等。對HDFS的操作命令類似於Linux
centos7搭建hadoop叢集之xcall指令碼
在一些特定場景下,需要所有節點同時執行相同的命令,比如主機hadoop1執行ls命令,其他節點主機也同時執行ls命令,實現這種效果快捷方式一般有兩種: 1.使用工具,同一傳送執行命令,如SecureCRT,同時連線所有節點,在視窗下面可以直接輸入需要同時執行的命令。 優
centos7搭建hadoop叢集之rsync和xsync
文章記錄於各個伺服器(或者虛擬機器等)已經配置了ssh免密登入,可執行下面操作,未配置ssh免密登入,可參考:https://blog.csdn.net/yhblog/article/details/84029535 此文章是基於centos7minimal版本的,純淨系統,所以還
Hadoop學習之HDFS的相關操作
以下是使用Hadoop2.4.1的JAVA API進行HDFS的相關操作 import java.io.BufferedInputStream; import java.io.FileInputStream; import java.io.FileNotFoundException; impor
偽分散式執行Hadoop例項之HDFS執行MapReduce程式
一、前期準備 準備一臺客戶機 安裝jdk 配置環境變數 安裝Hadoop 配置環境變數 二、配置叢集 配置hadoop-env.sh檔案 cd /opt/module/hadoop-2.7.2/etc/hadoop vim hadoo
Hadoop叢集之shell -----指令碼xcall,和同步指令碼xsync(一)
xcall指令碼 #!/bin/bash [email protected] i=1 for (( i=1 ; i <= 3 ; i = $i + 1 )) ; do echo ============= hadoop0$i $param
Hadoop系列之-HDFS
HDFS HDFS是Hadoop整體架構的底層儲存系統,從資料結構上來說,它適合儲存半結構化、非結構化、多維的資料,如果實時性要求不高,那麼它也可儲存關係性很強資料的資料。從資料量來說,它的分散式體系和容錯機制可容納
Hadoop --- 入門之HDFS的JAVA API操作
JAR準備: 將hadoop-2.8.0中share目錄下的jar包新增到工程中: common下的hadoop-common-2.8.0.jar common/lib下的所有jar hdfs下的hadoop-hdfs-2.8.0.jar hdfs/lib下的所有j
hadoop系列之HDFS 原理與實戰
HDFS檔案系統 HDFS簡介 HDFS 是 Hadoop Distributed File System 的簡稱,即 Hadoop 分散式檔案系統。它起源於谷歌發表的 GFS 論文, 是該論文的開源實現,也是整個大資料的基礎。 HDFS 專門為解決大資料的儲存問題而產生
Ambari搭建Hadoop叢集之配置SSH免密登入
Ambari搭建Hadoop叢集時為了實現叢集之間的主機進行快速的聯機,我們需要對叢集的虛擬機器進行免密登入配置。下面來說說具體步驟。 前提:3臺虛擬機器。 1.修改主機名 a)首先root許可權下分別對3臺虛擬機器進行修改。修改的命令如下: sudo hostnam