
hadoop叢集搭建HDFS、HA、 YARN
hadoop2.0已經發布了很多穩定版本,增加了很多特性,比如HDFS HA、YARN等。最新的hadoop-2.7.2又增加了YARN HA
1、環境準備
修改主機名、IP地址。這些在之前部落格有提過就不再寫了。
配置IP地址和主機名對映關係。
sudo vi /etc/hosts

叢集規劃:
主機名 IP 安裝的軟體 執行的程序
spark01 192.168.2.201 jdk、hadoop NameNode、 DFSZKFailoverController(zkfc)
spark02 192.168.2.202 jdk、hadoop NameNode、DFSZKFailoverController(zkfc)
spark03 192.168.2.203 jdk、hadoop ResourceManager
spark04 192.168.2.204 jdk、hadoop ResourceManager
spark05 192.168.2.205 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
spark06 192.168.2.206 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
spark07 192.168.2.207 jdk、hadoop、zookeeper DataNode、NodeManager、JournalNode、QuorumPeerMain
2、安裝zookeeper叢集在spark05-07上
3、安裝配置hadoop叢集(在spark01上操作)
3.1 解壓
tar -zxvf hadoop-2.7.2.tar.gz -C /app/

3.2 配置HDFS(hadoop2.0所有的配置檔案都在HADOOP_HOME/etc/hadoop目錄下)
#將hadoop新增到環境變數中
sudo vi /etc/profile
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_91
export HADOOP_HOME=/home/hadoop/app/hadoop-2.7.2
export PATH=
export CLASSPATH=.:
#hadoop2.0的配置檔案全部在$HADOOP_HOME/etc/hadoop下
cd /home/hadoop/app/hadoop-2.7.2/etc/hadoop
a、修改hadoo-env.sh
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_91

b、修改core-site.xml
<configuration>
<!-- 指定hdfs的nameservice為ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1/</value>
</property>
<!-- 指定hadoop臨時目錄 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop-2.7.2/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>spark05:2181,spark06:2181,spark07:2181</value>
</property>
</configuration>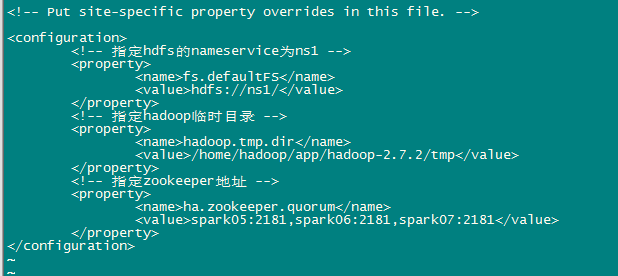
c、修改hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice為ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有兩個NameNode,分別是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通訊地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>spark01:9000</value>
</property>
<!-- nn1的http通訊地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>spark01:50070</value>
</property>
<!-- nn2的RPC通訊地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>spark02:9000</value>
</property>
<!-- nn2的http通訊地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>spark02:50070</value>
</property>
<!-- 指定NameNode的元資料在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://spark05:8485;spark06:8485;spark07:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁碟存放資料的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/app/hadoop-2.7.2/journaldata</value>
</property>
<!-- 開啟NameNode失敗自動切換 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失敗自動切換實現方式 -->
<property> <name>dfs.client.failover.proxy.provider.ns1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔離機制方法,多個機制用換行分割,即每個機制暫用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔離機制時需要ssh免登陸 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔離機制超時時間 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>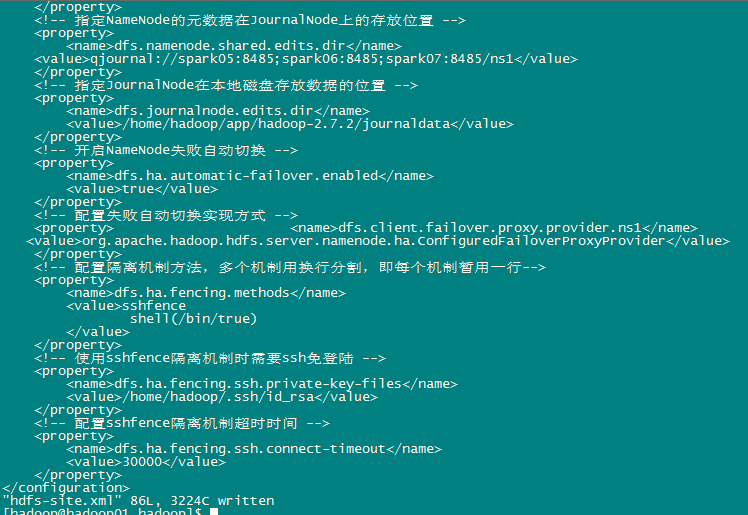
d、修改mapred-site.xml
先執行:[[email protected] hadoop]$ mv mapred-site.xml.template mapred-site.xml
<configuration>
<!-- 指定mr框架為yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>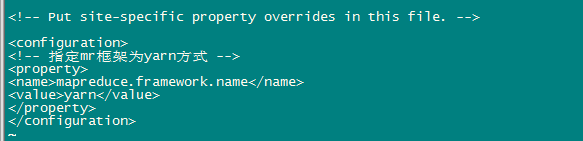
e、修改yarn-site.xml
<configuration>
<!-- 開啟RM高可用 -->
<property> <name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分別指定RM的地址 -->
<property> <name>yarn.resourcemanager.hostname.rm1</name>
<value>spark03</value>
</property>
<property> <name>yarn.resourcemanager.hostname.rm2</name>
<value>spark04</value>
</property>
<!-- 指定zk叢集地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name> <value>spark05:2181,spark06:2181,spark07:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>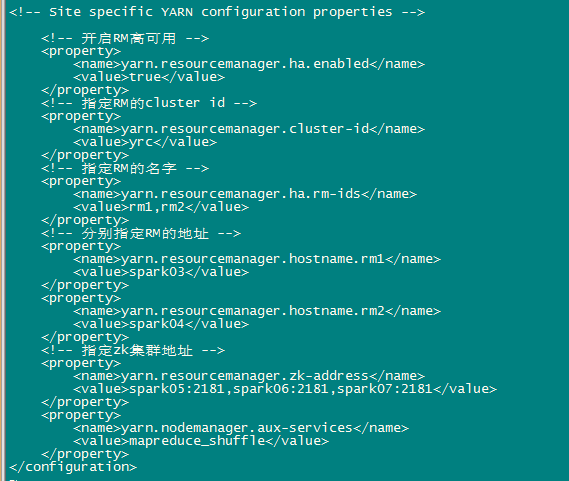
f、修改slaves(slaves是指定子節點的位置,因為要在spark01上啟動HDFS、在spark03啟動yarn,所以spark01上的slaves檔案指定的是datanode的位置,spark03上的slaves檔案指定的是nodemanager的位置)
spark05
spark06
spark07
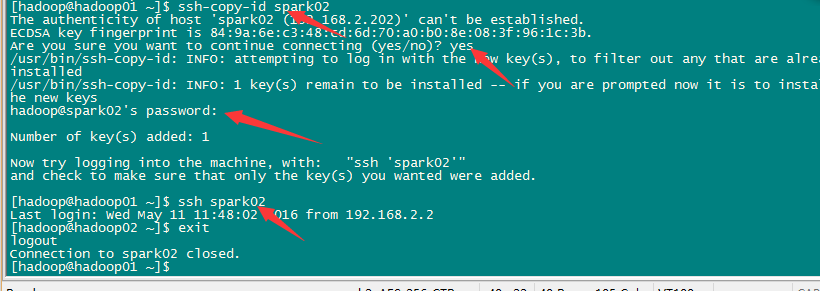
無金鑰登入:
首先要配置spark01到spark02、spark03、spark04、spark05、spark06、spark07的免密碼登陸
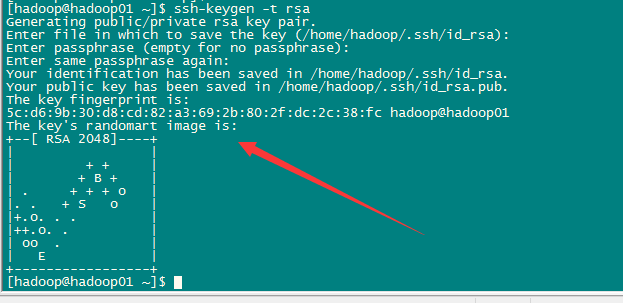
[[email protected] ~]
[[email protected] ~]
[[email protected] ~]
我在這裡就只截一張圖了
配置spark03——》spark5-7的無金鑰登入
同上述步驟在03中執行:ssh-keygen -t rsa
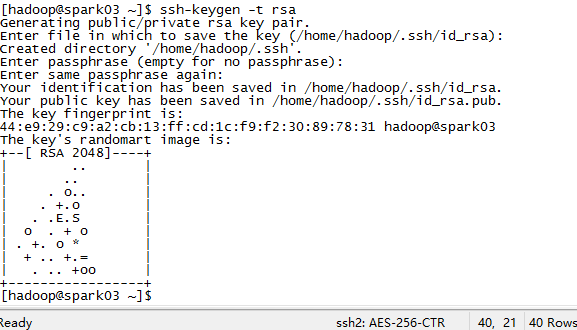
[[email protected] ~]
[[email protected] ~]$ ssh-copy-id spark07
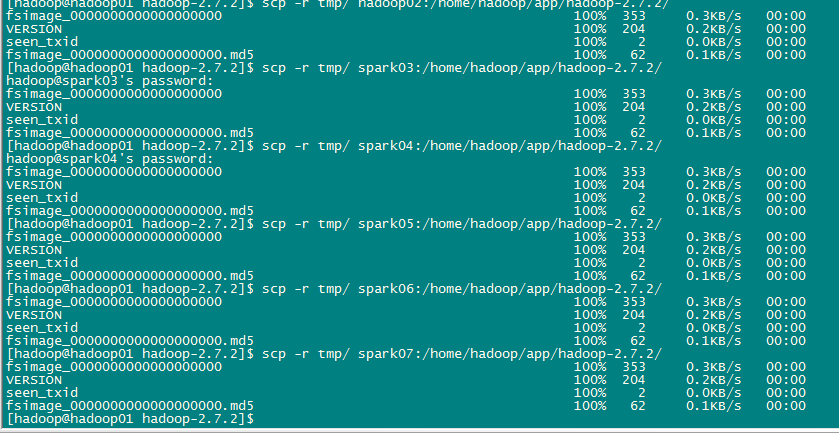
g、再將spark01中配置好的hadoop環境拷貝到其他機器上
scp -r hadoop-2.7.2/ spark02:/home/hadoop/app/
自己依次拷貝2-7都要拷貝過去,這樣整個hadoop叢集環境就部署完成了。接下來就是啟動與測試叢集。
4、啟動與測試
嚴格按照以下步驟完成啟動任務:
1、啟動zookeeper叢集(分別在spark05、spark06、spark07上啟動zk)
cd /weekend/zookeeper-3.4.8/bin/
./zkServer.sh start
#檢視狀態:一個leader,兩個follower
./zkServer.sh status
2、啟動journalnode(分別在在spark05、spark06、spark07上執行)
cd /weekend/hadoop-2.7.2/sbin
sbin/hadoop-daemon.sh start journalnode
#執行jps命令檢驗,weekend05、weekend06、weekend07上多了JournalNode程序
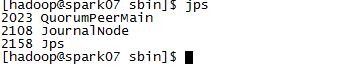
3、格式化HDFS
#在spark01上執行命令:
hdfs namenode -format
#格式化後會在根據core-site.xml中的hadoop.tmp.dir配置生成個檔案,這裡我配置的是/hadoop/hadoop-2.7.2/tmp,然後將/weekend/hadoop-2.4.1/tmp拷貝到hadoop02的/weekend/hadoop-2.7.2/下。
scp -r tmp/ hadoop02:/home/hadoop/app/hadoop-2.7.2/
##也可以這樣,建議hdfs namenode -bootstrapStandby
4、格式化ZKFC(在hadoop【spark】01上執行即可)
hdfs zkfc -formatZK
5、啟動HDFS(在hadoop【spark】01上執行)
sbin/start-dfs.sh
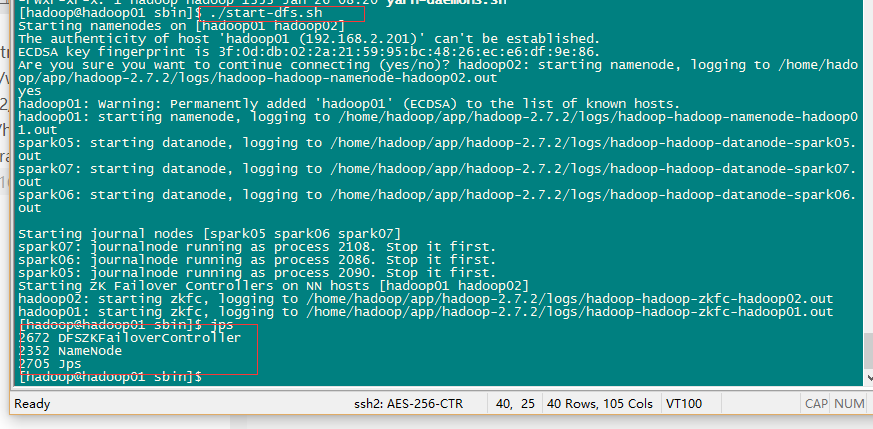
6、啟動YARN(#####注意#####:是在spark03上執行start-yarn.sh,把namenode和resourcemanager分開是因為效能問題,因為他們都要佔用大量資源,所以把他們分開了,他們分開了就要分別在不同的機器上啟動)
sbin/start-yarn.sh
7、在瀏覽器中檢視nanenode
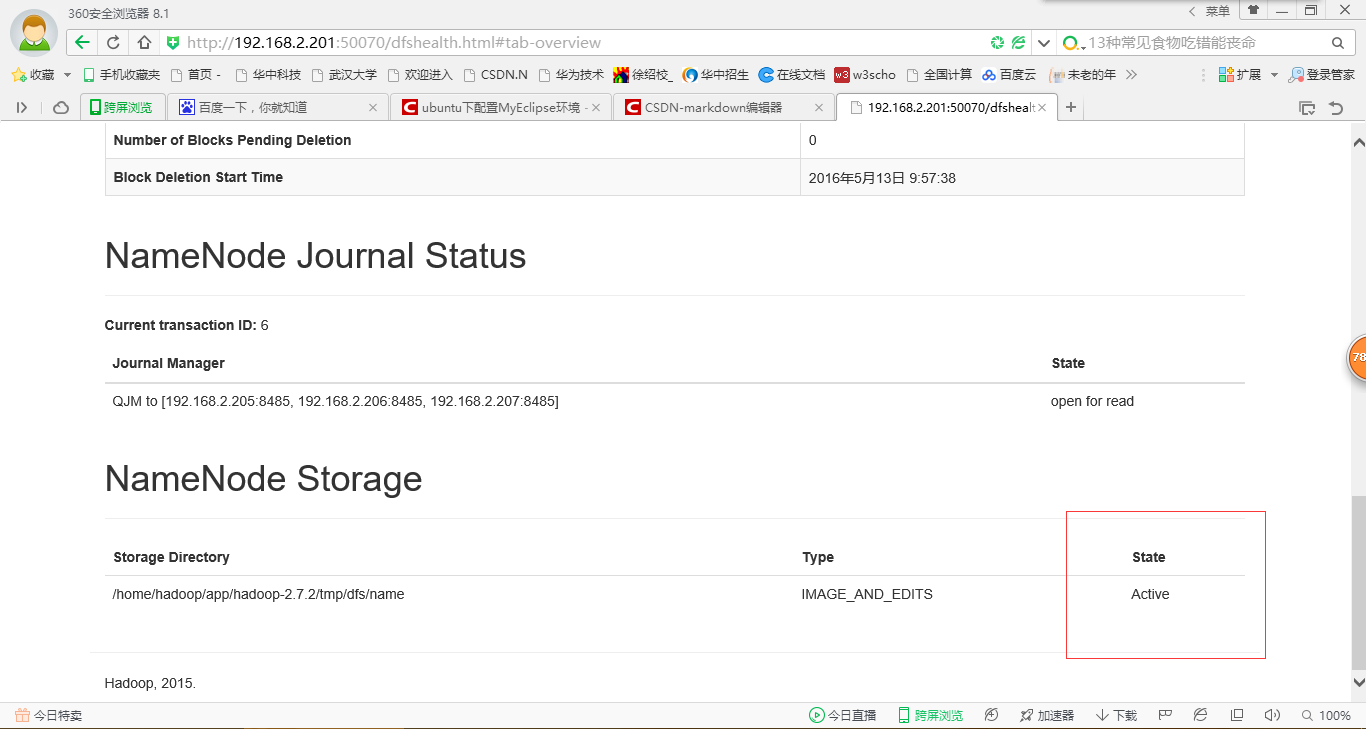
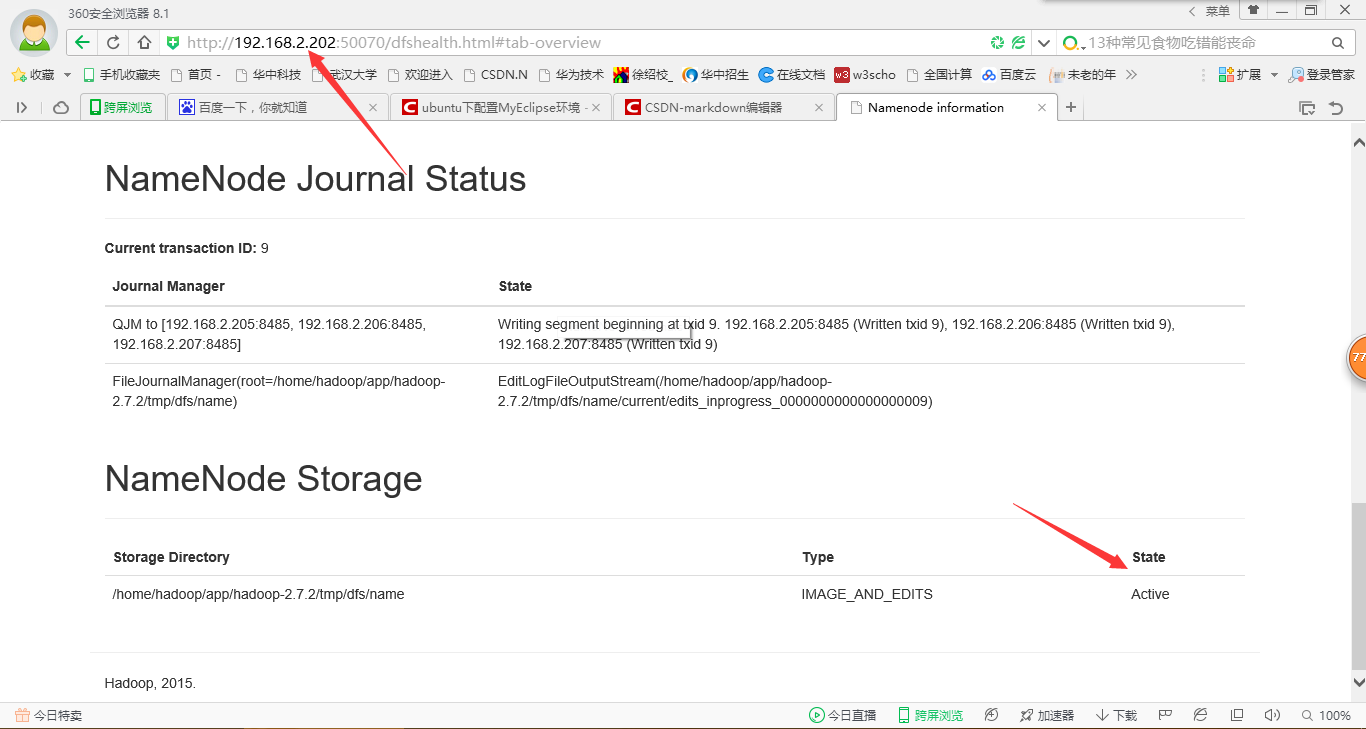
8、驗證HDFS HA
首先向hdfs上傳一個檔案
hadoop fs -put /etc/profile /profile
hadoop fs -ls /
然後再kill掉active的NameNode
kill -9
通過瀏覽器訪問:http://192.168.1.202:50070
NameNode ‘hadoop02:9000’ (active)
這個時候weekend02上的NameNode變成了active
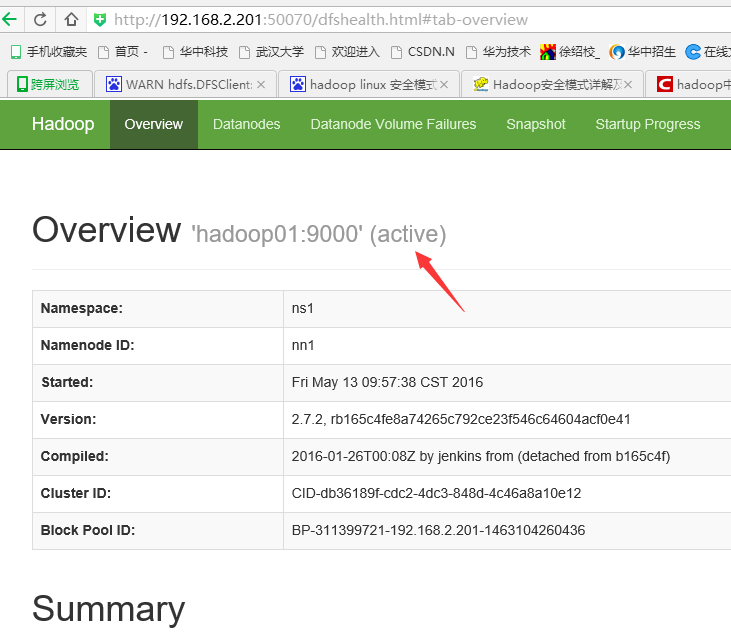
在執行命令:
hadoop fs -ls /
-rw-r–r– 3 root supergroup 1926 2014-02-06 15:36 /profile
剛才上傳的檔案依然存在!!!
手動啟動那個掛掉的NameNode
sbin/hadoop-daemon.sh start namenode
通過瀏覽器訪問:http://192.168.1.201:50070
NameNode ‘hadoop01:9000’ (standby)
驗證YARN:
執行一下hadoop提供的demo中的WordCount程式:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.1.jar wordcount /profile /out