利用二叉樹設計一款簡單的huffman編碼器
阿新 • • 發佈:2018-11-27
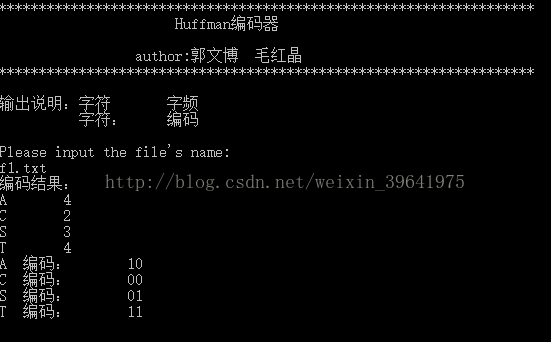
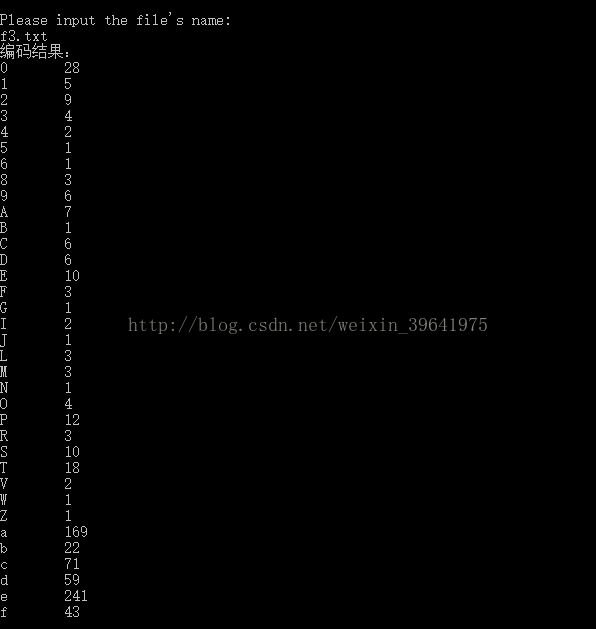
從磁碟讀入一個僅包括英文字母及標點符號的文字檔案(如f1.txt),統計各字元的頻度,據此構建huffman樹,對各字元進行編碼,並將字符集,頻度集及相應編碼碼字集輸出在顯示器或儲存在另一個文字檔案(如 f1_code.txt)中.
思路:
Void HuffmanCode(HuffNode<char>* ht1, char * Code, int length)
{ ……
若 ht1為空 return
若 ht1 為葉子結點 列印(輸出) ht1 的val, weight, Code
否則 如果 ht1 的左孩子不為空
copy Code到一個臨時字串 temp_c,
令 len=length; len++;temp_c[len]= ‘0’ ;
遞迴呼叫 huffmanCode( ht1->left(), temp_c, len)
否則 如果 ht1 的右孩子不為空
copy Code到一個臨時字串temp_c,
令 len=length; len++;temp_c[len]= ‘1’ ;
遞迴呼叫 huffmanCode( ht1->right(), temp_c, len)
#include<iostream>
#include<fstream>#define SIZELEAF 100
#define SIZENODE 2*SIZELEAF-1
#define MAXWEIGHT 10000
using namespace std;
typedef struct //結構體
{
int weight;
int lchild;
int rchild;
int parent;
}Node,*HuffmanTree;
typedef struct
{
char ch;
int codes[SIZELEAF];
int num;
} Code;
void huftreenode (int weight[SIZELEAF],Node node[SIZENODE], int n)
{
int w1,w2,n1,n2,i,k;
for (i=0; i<2*n-1; i++) //全部節點初始化
{
node[i].weight=0;
node[i].lchild=0;
node[i].rchild=0;
node[i].parent=0;
}
for (i=0; i<n; i++)
{
node[i].weight=weight[i];
}
for (i=0; i<n-1; i++)
{
w1=w2=MAXWEIGHT;
n1=n2=0;
for (k=0; k<n+i; k++)
{
if (node[k].weight < w1 && node[k].parent==0)
{
w2=w1;
n2=n1;
w1=node[k].weight;
n1=k;
}
else if (node[k].weight < w2 && node[k].parent==0)
{
w2=node[k].weight;
n2=k;
}
}
node[n1].parent = n+i;
node[n2].parent = n+i;
node[n+i].weight = node[n1].weight + node[n2].weight;
node[n+i].lchild = n1;
node[n+i].rchild = n2;
}
}
void huftreecode (Code code[SIZENODE], Node node[SIZENODE], int n, char s[SIZELEAF])
{
int i,p,x,c;
for(i=0; i<n; i++)
{
code[i].ch=s[i]; //回溯發,從葉子往上找,直到根
p=node[i].parent;
x=i;
c=0;
while( p != 0)
{
if(node[p].lchild == x)
{
code[i].codes[c]=0;
}
else
{
code[i].codes[c]=1;
}
c++;
x=p;
p=node[x].parent;
}
code[i].num=c-1;
}
}
void input(char sen[SIZELEAF], int number[SIZELEAF], int *num)
{
int Num[SIZELEAF];
char sensus[SIZELEAF];
FILE *fp;
char ch;
int sort;
char filename[100];
int i,j,k,n,m;
for(i=0;i<SIZELEAF;i++)
{
Num[i]=0;
sensus[i]='0';
}
cout<<"Please input the file's name:\n";
gets(filename);
if((fp=fopen(filename,"r")) == NULL)
{
cout<<"\ncan not open the file!";
getchar();
exit(0);
}
*num=0;
while(ch!=EOF) //統計字頻,使用ASCII來統計
{
ch=fgetc(fp); //sensus0-9來存數字0-9;接下來存a-z,,...,,,,,
if(ch >='0' && ch <= '9')
{
sort=ch-'0';
Num[sort]++;
sensus[sort]=ch;
}
else if(ch >= 'A' && ch <='Z')
{
sort=ch-'A'+10;
Num[sort]++;
sensus[sort]=ch;
}
else if(ch >= 'a' && ch <='z')
{
sort=ch-'a'+36;
Num[sort]++;
sensus[sort]=ch;
}
else if(ch == ',')
{
Num[62]++;
sensus[62]=ch;
}
else if(ch == '.')
{
Num[63]++;
sensus[63]=ch;
}
else if(ch == '(')
{
Num[64]++;
sensus[64]=ch;
}
else if(ch == ')')
{
Num[65]++;
sensus[65]=ch;
}
else if(ch == '-')
{
Num[66]++;
sensus[66]=ch;
}
}
for(n=0;n<67;n++)
{
if(Num[n]!=0) //清空 字元頻度為
(*num)++;
}
for(m=0;m<67;m++)
{
number[m]=0;
sen[m]='0';
}
for(j=0,k=0;k<67;j++,k++)
{
while(Num[k] == 0)
k++;
number[j]=Num[k];
sen[j]=sensus[k];
}
cout<<"編碼結果:"<<endl;
for(i=0;i<*num;i++)
{
cout<<sen[i]<<"\t";
cout<<number[i]<<"\t"<<endl;
}
fclose(fp);
}
int main()
{
int n;
int i,j,x;
char sensus[SIZELEAF];
int Num[SIZELEAF];
Node hufnode[SIZENODE];
Code hufcode[SIZELEAF];
char choice;
cout<<"*******************************************************************\n";
cout<<" Huffman編碼器\n";
cout<<endl;
cout<<" author:** **"<<endl;
cout<<"*******************************************************************\n\n";
cout<<"輸出說明:字元 字頻\n";
cout<<" 字元: 編碼" <<endl;
cout<<endl;
do
{
input(sensus,Num,&n);
huftreenode (Num,hufnode,n);
huftreecode (hufcode,hufnode,n,sensus);
for(i=0; i<n; i++)
{
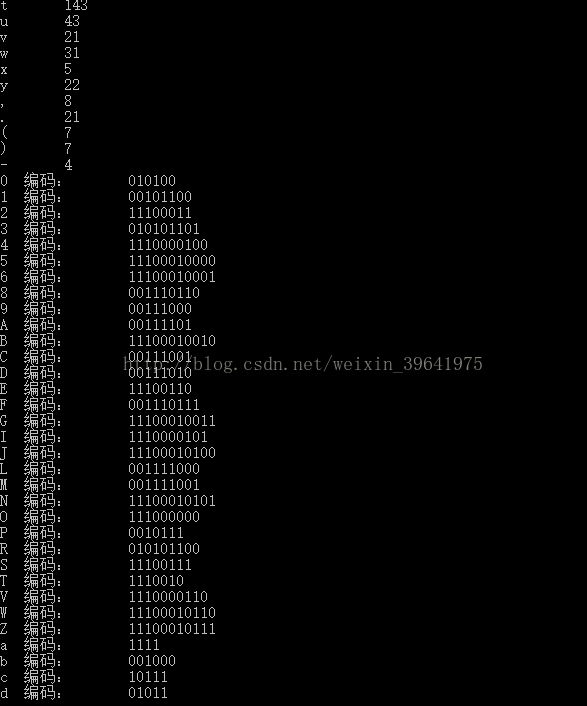
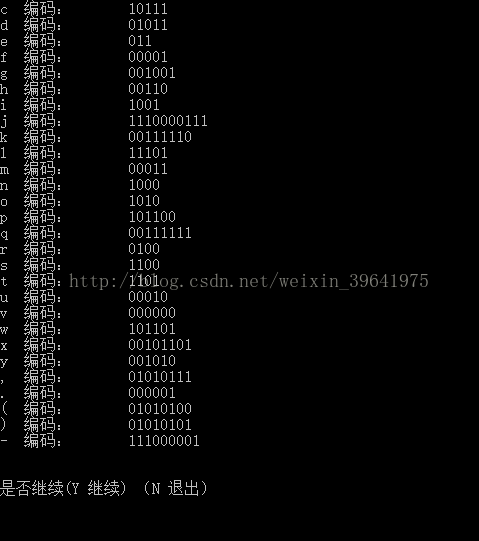
cout<<hufcode[i].ch<<" 編碼:"<<"\t";
x=hufcode[i].num;
for(j=x; j>=0; j--)
{
cout<<hufcode[i].codes[j];
}
cout<<endl;
}
cout<<endl;
cout<<endl;
cout<<"是否繼續(Y 繼續) (N 退出)\n";
cin>>choice;
}
while(choice == 'Y');
}