
Raft對比ZAB協議
系列文章
0 一致性問題
本篇文章想總結下Raft和ZAB在處理一些一致性問題上的做法,詳見之前對這2個演算法的描述
上述分別是針對如下演算法實現的討論:
- Raft的實現copycat,由於Raft演算法本身已經介紹的相當清晰,copycat基本上和Raft演算法保持一致
- ZAB的實現ZooKeeper,由於ZooKeeper裡面的很多實現細節並沒有在ZAB裡體現(ZAB裡面只是一個大概,沒有像Raft那麼具體),所以這裡討論的都是ZooKeeper的實現
一致性演算法在實現狀態機這種應用時,有哪些常見的問題:
-
1 leader選舉
-
1.1 一般的leader選舉過程
選舉的輪次 選舉出來的leader要包含更多的日誌 -
1.2 leader選舉的效率
會不會出現split vote?以及各自的特點是? -
1.3 加入一個已經完成選舉的叢集
怎麼發現已完成選舉的leader? 加入過程是否對leader處理請求的過程造成阻塞? -
1.4 leader選舉的觸發
誰在負責檢測需要進入leader選舉?
-
-
2 上一輪次的leader
- 2.1 上一輪次的leader的殘留的資料怎麼處理?
- 2.2 怎麼阻止之前的leader假死的問題
-
3 請求處理流程
- 3.1 請求處理的一般流程
- 3.2 日誌的連續性問題
-
3.3 如何保證順序
- 3.3.1 正常同步過程的順序
-
3.3.2 異常過程的順序
follower掛掉又連線 leader更換
- 3.4 請求處理流程的異常
- 4 分割槽的處理
下面分別來看看Raft和ZooKeeper怎麼來解決的
1 leader選舉
為什麼要進行leader選舉?
在實現一致性的方案,可以像base-paxos那樣不需要leader選舉,這種方案達成一件事情的一致性還好,面對多件事情的一致性就比較複雜了,所以通過選舉出一個leader來簡化實現的複雜性。
1.1 一般的leader選舉過程
更多的有2個要素:
- 1.1.1 選舉輪次
- 1.1.2 leader包含更多的日誌
1.1.1 選舉投票可能會多次輪番上演,為了區分,所以需要定義你的投票是屬於哪個輪次的。
- Raft定義了term來表示選舉輪次
- ZooKeeper定義了electionEpoch來表示
他們都需要在某個輪次內達成過半投票來結束選舉過程
1.1.2 投票PK的過程,更多的是日誌越新越多者獲勝
在選舉leader的時候,通常都希望
選舉出來的leader至少包含之前全部已提交的日誌
自然想到包含的日誌越新越大那就越好。
通常都是比較最後一個日誌記錄,如何來定義最後一個日誌記錄?
有2種選擇,一種就是所有日誌中的最後一個日誌,另一種就是所有已提交中的最後一個日誌。目前Raft和ZooKeeper都是採用前一種方式。日誌的越新越大表示:輪次新的優先,然後才是同一輪次下日誌記錄大的優先
- Raft:term大的優先,然後entry的index大的優先
-
ZooKeeper:peerEpoch大的優先,然後zxid大的優先
ZooKeeper有2個輪次,一個是選舉輪次electionEpoch,另一個是日誌的輪次peerEpoch(即表示這個日誌是哪個輪次產生的)。而Raft則是隻有一個輪次,相當於日誌輪次和選舉輪次共用了。至於ZooKeeper為什麼要把這2個輪次分開,這個稍後再細究,有興趣的可以一起研究。
但是有一個問題就是:通過上述的日誌越新越大的比較方式能達到我們的上述希望嗎?
特殊情況下是不能的,這個特殊情況詳細見上述給出Raft演算法賞析的這一部分
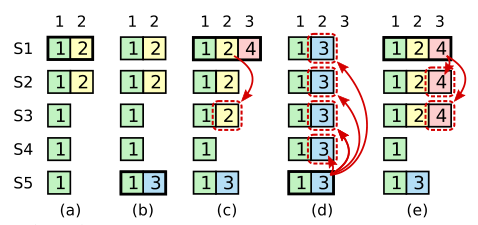
這個案例就是這種比較方式會選舉出來的leader可能並不包含已經提交的日誌,而Raft的做法則是對於日誌的提交多加一個限制條件,即不能直接提交之前term的已過半的entry,即把這一部分的日誌限制成未提交的日誌,從而來實現上述的希望。
ZooKeeper呢?會不會出現這種情況?又是如何處理的?
ZooKeeper是不會出現這種情況的,因為ZooKeeper在每次leader選舉完成之後,都會進行資料之間的同步糾正,所以每一個輪次,大家都日誌內容都是統一的
而Raft在leader選舉完成之後沒有這個同步過程,而是靠之後的AppendEntries RPC請求的一致性檢查來實現糾正過程,則就會出現上述案例中隔了幾個輪次還不統一的現象
1.2 leader選舉的效率
Raft中的每個server在某個term輪次內只能投一次票,哪個candidate先請求投票誰就可能先獲得投票,這樣就可能造成split vote,即各個candidate都沒有收到過半的投票,Raft通過candidate設定不同的超時時間,來快速解決這個問題,使得先超時的candidate(在其他人還未超時時)優先請求來獲得過半投票
ZooKeeper中的每個server,在某個electionEpoch輪次內,可以投多次票,只要遇到更大的票就更新,然後分發新的投票給所有人。這種情況下不存在split vote現象,同時有利於選出含有更新更多的日誌的server,但是選舉時間理論上相對Raft要花費的多。
1.3 加入一個已經完成選舉的叢集
- 1.3.1 怎麼發現已完成選舉的leader?
- 1.3.2 加入過程是否阻塞整個請求?
1.3.1 怎麼發現已完成選舉的leader?
一個server啟動後(該server本來就屬於該叢集的成員配置之一,所以這裡不是新加機器),如何加入一個已經選舉完成的叢集
- Raft:比較簡單,該server啟動後,會收到leader的AppendEntries RPC,這時就會從RPC中獲取leader資訊,識別到leader,即使該leader是一個老的leader,之後新leader仍然會發送AppendEntries RPC,這時就會接收到新的leader了(因為新leader的term比老leader的term大,所以會更新leader)
- ZooKeeper:該server啟動後,會向所有的server傳送投票通知,這時候就會收到處於LOOKING、FOLLOWING狀態的server的投票(這種狀態下的投票指向的leader),則該server放棄自己的投票,判斷上述投票是否過半,過半則可以確認該投票的內容就是新的leader。
1.3.2 加入過程是否阻塞整個請求?
這個其實還要看對日誌的設計是否是連續的
-
如果是連續的,則leader中只需要儲存每個follower上一次的同步位置,這樣在同步的時候就會自動將之前欠缺的資料補上,不會阻塞整個請求過程
目前Raft的日誌是依靠index來實現連續的 -
如果不是連續的,則在確認follower和leader當前資料的差異的時候,是需要獲取leader當前資料的讀鎖,禁止這個期間對資料的修改。差異確定完成之後,釋放讀鎖,允許leader資料被修改,每一個修改記錄都要被儲存起來,最後一一應用到新加入的follower中。
目前ZooKeeper的日誌zxid並不是嚴格連續的,允許有空洞
1.4 leader選舉的觸發
觸發一般有如下2個時機
- server剛開始啟動的時候,觸發leader選舉
-
leader選舉完成之後,檢測到超時觸發,誰來檢測?
- Raft:目前只是follower在檢測。follower有一個選舉時間,在該時間內如果未收到leader的心跳資訊,則follower轉變成candidate,自增term發起新一輪的投票,leader遇到新的term則自動轉變成follower的狀態
- ZooKeeper:leader和follower都有各自的檢測超時方式,leader是檢測是否過半follower心跳回復了,follower檢測leader是否傳送心跳了。一旦leader檢測失敗,則leader進入LOOKING狀態,其他follower過一段時間因收不到leader心跳也會進入LOOKING狀態,從而出發新的leader選舉。一旦follower檢測失敗了,則該follower進入LOOKING狀態,此時leader和其他follower仍然保持良好,則該follower仍然是去學習上述leader的投票,而不是觸發新一輪的leader選舉
2 上一輪次的leader
2.1 上一輪次的leader的殘留的資料怎麼處理?
首先看下上一輪次的leader在掛或者失去leader位置之前,會有哪些資料?
- 已過半複製的日誌
- 未過半複製的日誌
一個日誌是否被過半複製,是否被提交,這些資訊是由leader才能知曉的,那麼下一個leader該如何來判定這些日誌呢?
下面分別來看看Raft和ZooKeeper的處理策略:
- Raft:對於之前term的過半或未過半複製的日誌採取的是保守的策略,全部判定為未提交,只有噹噹前term的日誌過半了,才會順便將之前term的日誌進行提交
- ZooKeeper:採取激進的策略,對於所有過半還是未過半的日誌都判定為提交,都將其應用到狀態機中
Raft的保守策略更多是因為Raft在leader選舉完成之後,沒有同步更新過程來保持和leader一致(在可以對外處理請求之前的這一同步過程)。而ZooKeeper是有該過程的
2.2 怎麼阻止上一輪次的leader假死的問題
這其實就和實現有密切的關係了。
- Raft的copycat實現為:每個follower開通一個複製資料的RPC介面,誰都可以連線並呼叫該介面,所以Raft需要來阻止上一輪次的leader的呼叫。每一輪次都會有對應的輪次號,用來進行區分,Raft的輪次號就是term,一旦舊leader對follower傳送請求,follower會發現當前請求term小於自己的term,則直接忽略掉該請求,自然就解決了舊leader的干擾問題
- ZooKeeper:一旦server進入leader選舉狀態則該follower會關閉與leader之間的連線,所以舊leader就無法傳送複製資料的請求到新的follower了,也就無法造成干擾了
3 請求處理流程
3.1 請求處理的一般流程
這個過程對比Raft和ZooKeeper基本上是一致的,大致過程都是過半複製
先來看下Raft:
- client連線follower或者leader,如果連線的是follower則,follower會把client的請求(寫請求,讀請求則自身就可以直接處理)轉發到leader
- leader接收到client的請求,將該請求轉換成entry,寫入到自己的日誌中,得到在日誌中的index,會將該entry傳送給所有的follower(實際上是批量的entries)
- follower接收到leader的AppendEntries RPC請求之後,會將leader傳過來的批量entries寫入到檔案中(通常並沒有立即重新整理到磁碟),然後向leader回覆OK
- leader收到過半的OK回覆之後,就認為可以提交了,然後應用到leader自己的狀態機中,leader更新commitIndex,應用完畢後回覆客戶端
- 在下一次leader發給follower的心跳中,會將leader的commitIndex傳遞給follower,follower發現commitIndex更新了則也將commitIndex之前的日誌都進行提交和應用到狀態機中
再來看看ZooKeeper:
- client連線follower或者leader,如果連線的是follower則,follower會把client的請求(寫請求,讀請求則自身就可以直接處理)轉發到leader
- leader接收到client的請求,將該請求轉換成一個議案,寫入到自己的日誌中,會將該議案發送給所有的follower(這裡只是單個傳送)
- follower接收到leader的議案請求之後,會將該議案寫入到檔案中(通常並沒有立即重新整理到磁碟),然後向leader回覆OK
- leader收到過半的OK回覆之後,就認為可以提交了,leader會向所有的follower傳送一個提交上述議案的請求,同時leader自己也會提交該議案,應用到自己的狀態機中,完畢後回覆客戶端
- follower在接收到leader傳過來的提交議案請求之後,對該議案進行提交,應用到狀態機中
3.2 日誌的連續性問題
在需要保證順序性的前提下,在利用一致性演算法實現狀態機的時候,到底是實現連續性日誌好呢還是實現非連續性日誌好呢?
- 如果是連續性日誌,則leader在分發給各個follower的時候,只需要記錄每個follower目前已經同步的index即可,如Raft
- 如果是非連續性日誌,如ZooKeeper,則leader需要為每個follower單獨儲存一個佇列,用於存放所有的改動,如ZooKeeper,一旦是佇列就引入了一個問題即順序性問題,即follower在和leader進行同步的時候,需要阻塞leader處理寫請求,先將follower和leader之間的差異資料先放入佇列,完成之後,解除阻塞,允許leader處理寫請求,即允許往該佇列中放入新的寫請求,從而來保證順序性
還有在複製和提交的時候:
- 連續性日誌可以批量進行
- 非連續性日誌則只能一個一個來複制和提交
其他有待後續補充
3.3 如何保證順序
具體順序是什麼?
這個就是先到達leader的請求,先被應用到狀態機。這就需要看正常執行過程、異常出現過程都是怎麼來保證順序的
3.3.1 正常同步過程的順序
- Raft對請求先轉換成entry,複製時,也是按照leader中log的順序複製給follower的,對entry的提交是按index進行順序提交的,是可以保證順序的
- ZooKeeper在提交議案的時候也是按順序寫入各個follower對應在leader中的佇列,然後follower必然是按照順序來接收到議案的,對於議案的過半提交也都是一個個來進行的
3.3.2 異常過程的順序保證
如follower掛掉又重啟的過程:
- Raft:重啟之後,由於leader的AppendEntries RPC呼叫,識別到leader,leader仍然會按照leader的log進行順序複製,也不用關心在複製期間新的新增的日誌,在下一次同步中自動會同步
-
ZooKeeper:重啟之後,需要和當前leader資料之間進行差異的確定,同時期間又有新的請求到來,所以需要暫時獲取leader資料的讀鎖,禁止此期間的資料更改,先將差異的資料先放入佇列,差異確定完畢之後,還需要將leader中已提交的議案和未提交的議案也全部放入佇列,即ZooKeeper的如下2個集合資料
-
ConcurrentMap outstandingProposals
Leader擁有的屬性,每當提出一個議案,都會將該議案存放至outstandingProposals,一旦議案被過半認同了,就要提交該議案,則從outstandingProposals中刪除該議案 -
ConcurrentLinkedQueue toBeApplied
Leader擁有的屬性,每當準備提交一個議案,就會將該議案存放至該列表中,一旦議案應用到ZooKeeper的記憶體樹中了,然後就可以將該議案從toBeApplied中刪除
然後再釋放讀鎖,允許leader進行處理寫資料的請求,該請求自然就新增在了上述佇列的後面,從而保證了佇列中的資料是有序的,從而保證發給follower的資料是有序的,follower也是一個個進行確認的,所以對於leader的回覆也是有序的
-
如果是leader掛了之後,重新選舉出leader,會不會有亂序的問題?
- Raft:Raft對於之前term的entry被過半複製暫不提交,只有當本term的資料提交了才能將之前term的資料一起提交,也是能保證順序的
- ZooKeeper:ZooKeeper每次leader選舉之後都會進行資料同步,不會有亂序問題
3.4 請求處理流程的異常
一旦leader發給follower的資料出現超時等異常
- Raft:會不斷重試,並且介面是冪等的
- ZooKeeper:follower會斷開與leader之間的連線,重新加入該叢集,加入邏輯前面已經說了
4 分割槽的應對
目前ZooKeeper和Raft都是過半即可,所以對於分割槽是容忍的。如5臺機器,分割槽發生後分成2部分,一部分3臺,另一部分2臺,這2部分之間無法相互通訊
其中,含有3臺的那部分,仍然可以湊成一個過半,仍然可以對外提供服務,但是它不允許有server再掛了,一旦再掛一臺則就全部不可用了。
含有2臺的那部分,則無法提供服務,即只要連線的是這2臺機器,都無法執行相關請求。
所以ZooKeeper和Raft在一旦分割槽發生的情況下是是犧牲了高可用來保證一致性,即CAP理論中的CP。但是在沒有分割槽發生的情況下既能保證高可用又能保證一致性,所以更想說的是所謂的CAP二者取其一,並不是說該系統一直保持CA或者CP或者AP,而是一個會變化的過程。在沒有分割槽出現的情況下,既可以保證C又可以保證A,在分割槽出現的情況下,那就需要從C和A中選擇一樣。ZooKeeper和Raft則都是選擇了C。