
TensorFlow下構建高效能神經網路模型的最佳實踐
作者簡介:李嘉璇,《TensorFlow技術解析與實戰》作者,有處理影象、社交文字資料情感分析、資料探勘等實戰經驗。曾任職百度研發工程師,目前研究構建高效能的神經網路模型及TensorFlow下的壓縮工具鏈,包括模型量化、剪枝。
本文為《程式設計師》原創文章,未經允許不得轉載,更多精彩文章請訂閱《程式設計師》
隨著神經網路演算法在影象、語音等領域都大幅度超越傳統演算法,但在應用到實際專案中卻面臨兩個問題:計算量巨大及模型體積過大,不利於移動端和嵌入式的場景;模型記憶體佔用過大,導致功耗和電量消耗過高。因此,如何對神經網路模型進行優化,在儘可能不損失精度的情況下,減小模型的體積,並且計算量也降低,就是我們將深度學習在更廣泛的場景下應用時要解決的問題。
加速神經網路模型計算的方向
在移動端或者嵌入式裝置上應用深度學習,有兩種方式:一是將模型執行在雲端伺服器上,向伺服器傳送請求,接收伺服器響應;二是在本地執行模型。
一般來說,採用後者的方式,也就是在PC上訓練好一個模型,然後將其放在移動端上進行預測。使用本地執行模型原因在於,首先,向服務端請求資料的方式可行性差。移動端的資源(如網路、CPU、記憶體資源)是很稀缺的。例如,在網路連線不良或者丟失的情況下,向服務端傳送連續資料的代價就變得非常高昂。其次,執行在本地的實時性更好。但問題是,一個模型大小動輒幾百兆,且不說把它安裝到移動端需要多少網路資源,就是每次預測時需要的記憶體資源也是很多的。
那麼,要在效能相對較弱的移動/嵌入式裝置(如沒有加速器的ARM CPU)上高效執行一個CNN,應該怎麼做呢?這就衍生出了很多加速計算的方向,其中重要的兩個方向是對記憶體空間和速度的優化。採用的方式一是精簡模型,既可以節省記憶體空間,也可以加快計算速度;二是加快框架的執行速度,影響框架執行速度主要有兩方面的因素,即模型的複雜度和每一步的計算速度。
精簡模型主要是使用更低的權重精度,如量化(quantization)或權重剪枝(weight pruning)。剪枝是指剪小權重的連線,把所有權值連線低於一個閾值的連線從網路裡移除。
而加速框架的執行速度一般不會影響模型的引數,是試圖優化矩陣之間的通用乘法(GEMM)運算,因此會同時影響卷積層(卷積層的計算是先對資料進行im2col運算,再進行GEMM運算)和全連線層。
模型壓縮
模型壓縮是指在不丟失有用資訊的前提下,縮減引數量以減少儲存空間,提高其計算和儲存效率,或按照一定的演算法對資料進行重新組織,減少資料的冗餘和儲存的空間的一種技術方法。
目前的壓縮方法主要有如下4類:
- 設計淺層網路。通過設計一個更淺的網路結構來實現和複雜模型相當的效果。但是因為淺層網路的表達能力往往很難和深層網路匹敵,因此一般用在解決簡單問題上。
- 壓縮訓練好的複雜模型。採用的主要方法有引數稀疏化(剪枝)、引數量化表示(量化),從而達到引數量減少、計算量減少、儲存減少的目的。這是目前採用的主流方法,也是本文主要講述的方法。
- 多值網路。最為典型就是二值網路、XNOR網路。其主要原理就是採用0和1兩個值對網路的輸入和權重進行編碼,原始網路的卷積操作可以被位運算代替。在減少模型大小的同時,極大提升了模型的計算速度。但是由於二值網路會很大程度降低模型的表達能力。因此也在研究n-bit編碼方式。
- 知識蒸餾(Knowledge Distilling)。採用遷移學習,將複雜模型的輸出做為soft target來訓練一個簡單網路。
下面我們來著重介紹目前應用較多的壓縮訓練好的複雜模型的方法。
剪枝(Prunes the network)
剪枝就是將網路轉化為稀疏網路,即大部分權值都為0,只保留一些重要的連線。如圖1所示。
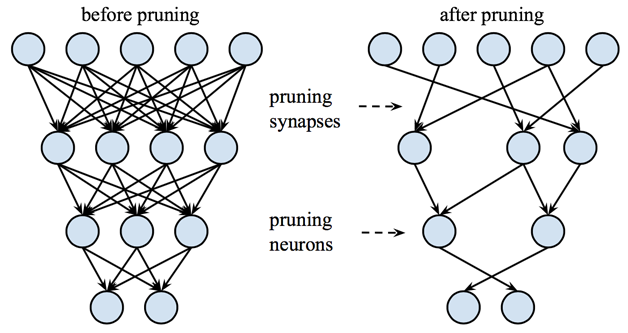
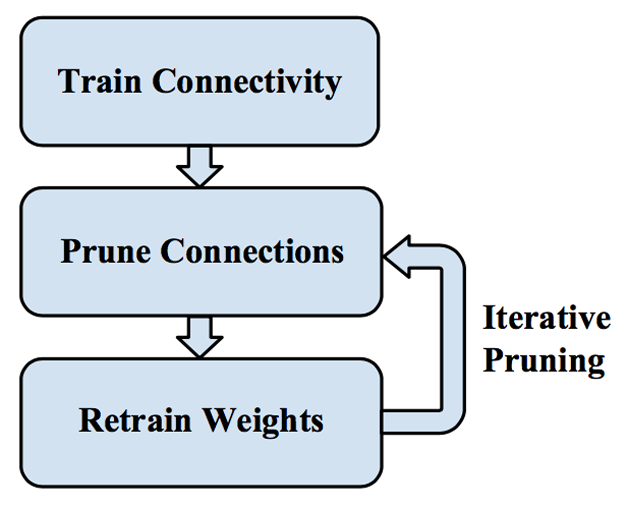
事實上,我們一般是逐層對神經網路進行敏感度分析(sensitive analysis),看哪一部分權重置為0後,對精度的影響較小。然後將權重排序,設定一個置零閾值,將閾值以下的權重置零,保持這些權重不變,繼續訓練至模型精度恢復;反覆進行上述過程,通過增大置零的閾值提高模型中被置零的比例。具體過程如圖2所示。
剪枝的特點:
- 通用於各種網路結構與各種任務,且實現簡單,效能穩定;
- 稀疏網路具有更低的功耗,在CPU上使用特定工具時具有更快的計算速度;
- 剪枝後的稀疏矩陣通常採取特殊的儲存方式,例如,常用MKL中的CSR格式。
剪枝的結果:
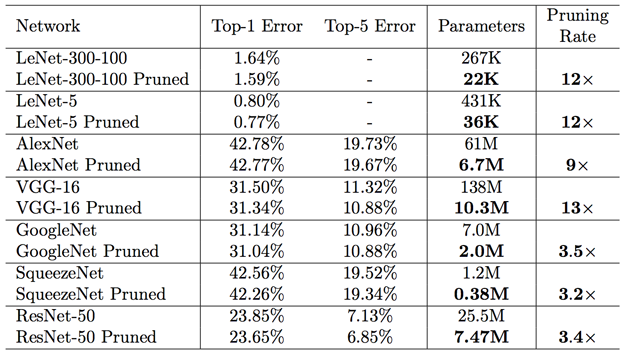
- 通過在現有的經典神經網路上做實驗,發現壓縮倍數在9-12倍之間。如圖3所示;
- 壓縮的多是全連線層,CNN層引數少,因此能壓縮的倍數也較少;
- 根據經驗,壓縮到60%以上模型儲存大小,模型大小才會下降比較多。
量化(Quantize the weights)
量化(Quantization)又稱定點,用更少的資料位寬進行神經網路儲存和計算。它的優勢在於節省儲存,並進行更快地訪存和計算。
量化是一個總括術語,用比32位浮點數更少的空間來儲存和執行模型,並且TensorFlow量化的實現遮蔽了儲存和執行細節。
神經網路訓練時要求速度和準確率,訓練通常在GPU上進行,所以使用浮點數影響不大。但是在預測階段,使用浮點數會影響速度。量化可以在加快速度的同時,保持較高的精度。
量化網路的動機主要有兩個。最初的動機是減小模型檔案的大小。模型檔案往往佔據很大的磁碟空間,例如,上一節介紹的網路模型,很多模型都接近200MB,模型中儲存的是分佈在大量層中的權值。在儲存模型的時候用8位整數,模型大小可以縮小為原來32位的25%左右。在載入模型後運算時轉換回32位浮點數,這樣已有的浮點計算程式碼無需改動即可正常執行。
量化的另一個動機是降低預測過程需要的計算資源。這在嵌入式和移動端非常有意義,能夠更快地執行模型,功耗更低。從體系架構的角度來說,8位的訪問次數要比32位多,在讀取8位整數時只需要32位浮點數的1/4的記憶體頻寬,例如,在32位記憶體頻寬的情況下,8位整數可以一次訪問4個,32位浮點數只能1次訪問1個。而且使用SIMD指令,可以在一個時鐘週期裡實現更多的計算。另一方面,8位對嵌入式裝置的利用更充分,因為很多嵌入式晶片都是8位、16位的,如微控制器、數字訊號處理器(DSP晶片),8位可以充分利用這些。
此外,神經網路對於噪聲的健壯性很強,因為量化會帶來精度損失(這種損失可以認為是一種噪聲),並不會危害到整體結果的準確度。
那能否用低精度格式來直接訓練呢?答案是,大多數情況下是不能的。因為在訓練時,儘管前向傳播能夠順利進行,但往往反向傳播中需要計算梯度。例如,梯度是0.2,使用浮點數可以很好地表示,而整數就不能很好地表示,這會導致梯度消失。因此需要使用高於8位的值來計算梯度。因此,正如在本文一開始介紹的那樣,在移動端訓練模型的思路往往是,在PC上正常訓練好浮點數模型,然後直接將模型轉換成8位,移動端是使用8位的模型來執行預測的過程。
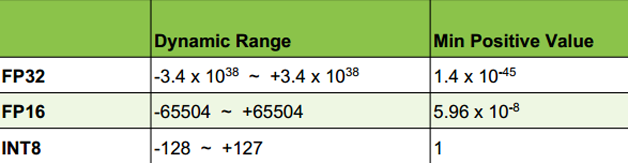
圖4展示了不同精度(FP32、FP16、INT8)表示的資料範圍。
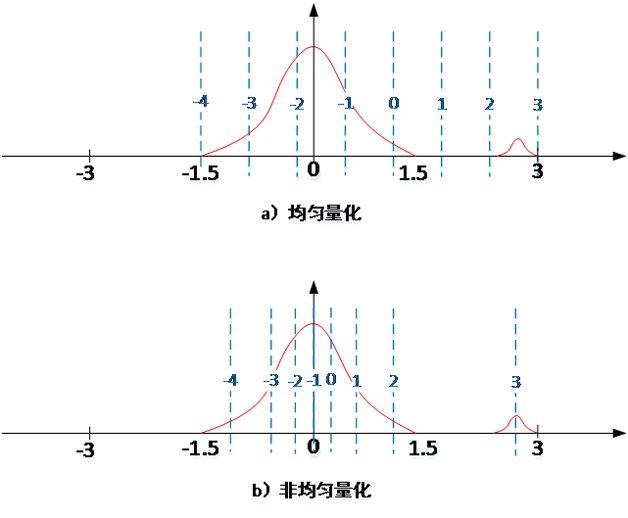
量化有2種類型,均為量化和非均勻量化。我們以將32bit浮點表示成3bit定點值為例。如圖5,用INT3來近似表示浮點值,取值範圍是8種離散取值(-4,-3,…,3)。如果不論權值的疏密,直接對應,我們稱之為“均勻量化”;如果權值密的量化後的範圍也較密,權值稀疏的量化後的範圍也較稀疏,稱之為“非均勻量化”。
TensorFlow下的模型壓縮工具
我們以TensorFlow下8位精度的儲存和計算來說明。
量化示例
舉個將GoogleNet模型轉換成8位模型的例子,看看模型的大小減小多少,以及用它預測的結果怎麼樣。
從官方網站上下載訓練好的GoogleNet模型,解壓後,放在/tmp目錄下,然後執行:
bazel build tensorflow/tools/quantization:quantize_graph
bazel-bin/tensorflow/tools/quantization/quantize_graph \
--input=/tmp/classify_image_graph_def.pb \
--output_node_names="softmax" --output=/tmp/quantized_graph.pb \
--mode=eightbit
生成量化後的模型quantized_graph.pb大小隻有23MB,是原來模型classify_image_graph_ def.pb(91MB)的1/4。它的預測效果怎麼樣呢?執行:
bazel build tensorflow/examples/label_image:label_image
bazel-bin/tensorflow/examples/label_image/label_image \
--image=/tmp/cropped_panda.jpg \
--graph=/tmp/quantized_graph.pb \
--labels=/tmp/imagenet_synset_to_human_label_map.txt \
--input_width=299 \
--input_height=299 \
--input_mean=128 \
--input_std=128 \
--input_layer="Mul:0" \
--output_layer="softmax:0"
執行結果如圖6所示,可以看出8位模型預測的結果也很好。

量化過程的實現
TensorFlow的量化是通過將預測的操作轉換成等價的8位版本的操作來實現。量化操作過程如圖7所示。
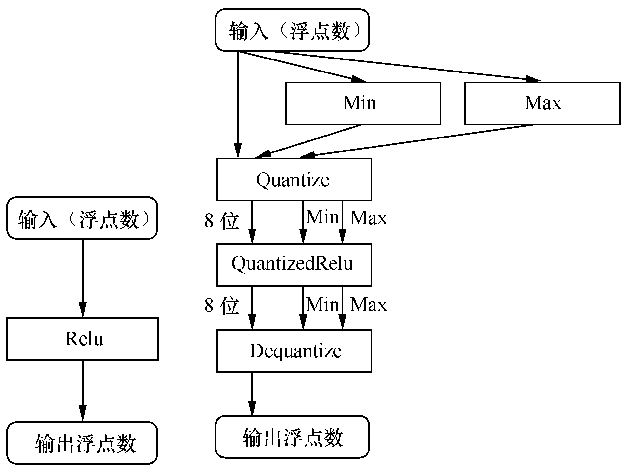
圖7中左側是原始的Relu操作,輸入和輸出均是浮點數。右側是量化後的Relu操作,先根據輸入的浮點數計算最大值和最小值,然後進入量化(Quantize)操作將輸入資料轉換成8位。一般來講,在進入量化的Relu(QuantizedRelu)處理後,為了保證輸出層的輸入資料的準確性,還需要進行反量化(Dequantize)的操作,將權重再轉回32位精度,來保證預測的準確性。也就是整個模型的前向傳播採用8位段數執行,在最後一層之前加上一個反量化層,把8位轉回32位作為輸出層的輸入。
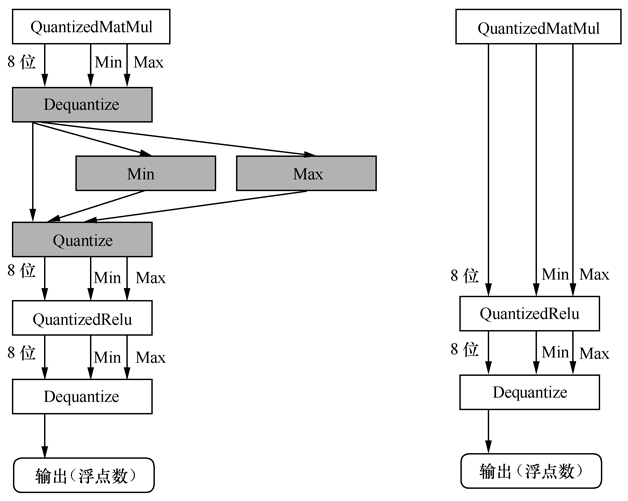
實際上,我們會在每個量化操作(如QuantizedMatMul、QuantizedRelu等)的後面執行反量化操作(Dequantize),如圖8左側所示在QuantizedMatMul後執行反量化和量化操作可以相互抵消。因此,在輸出層之前做一次反量化操作就可以了。
量化資料的表示
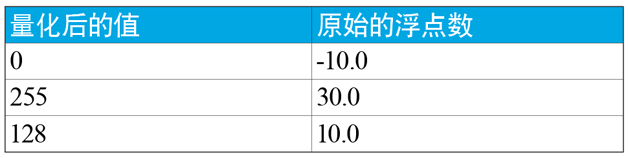
將浮點數轉換為8位的表示實際上是一個壓縮問題。權重和經過啟用函式處理過的上一層的輸出(也就是下一層的輸入)實際上是分佈在一個範圍內的值。量化的過程一般是找出最大值和最小值後,將分佈在其中的浮點數認為是線性分佈,做線性擴充套件。因此,假設最小值是-10.0f,最大值是30.0f,那量化後的結果如表1所示。
經典神經網路ResNet50上的模型壓縮實驗
筆者在ResNet50-v1上,採用官方GitHub上提供的模型作為Baseline,在ImageNet測試集5萬張圖片上進行測試。結果如圖9。

在均勻量化的過程中,首先是僅僅對權重進行量化,得到精度為72.8%。隨後,分別用模型對測試集的10張、1000張圖片的範圍進行提前計算最值(Max和Min),並進行儲存,得到的精度分別為72.9%和73.1%。
從量化前後的視覺化模型對比,也可以看成量化對模型做了哪些操作。圖10是未經量化的原始模型。
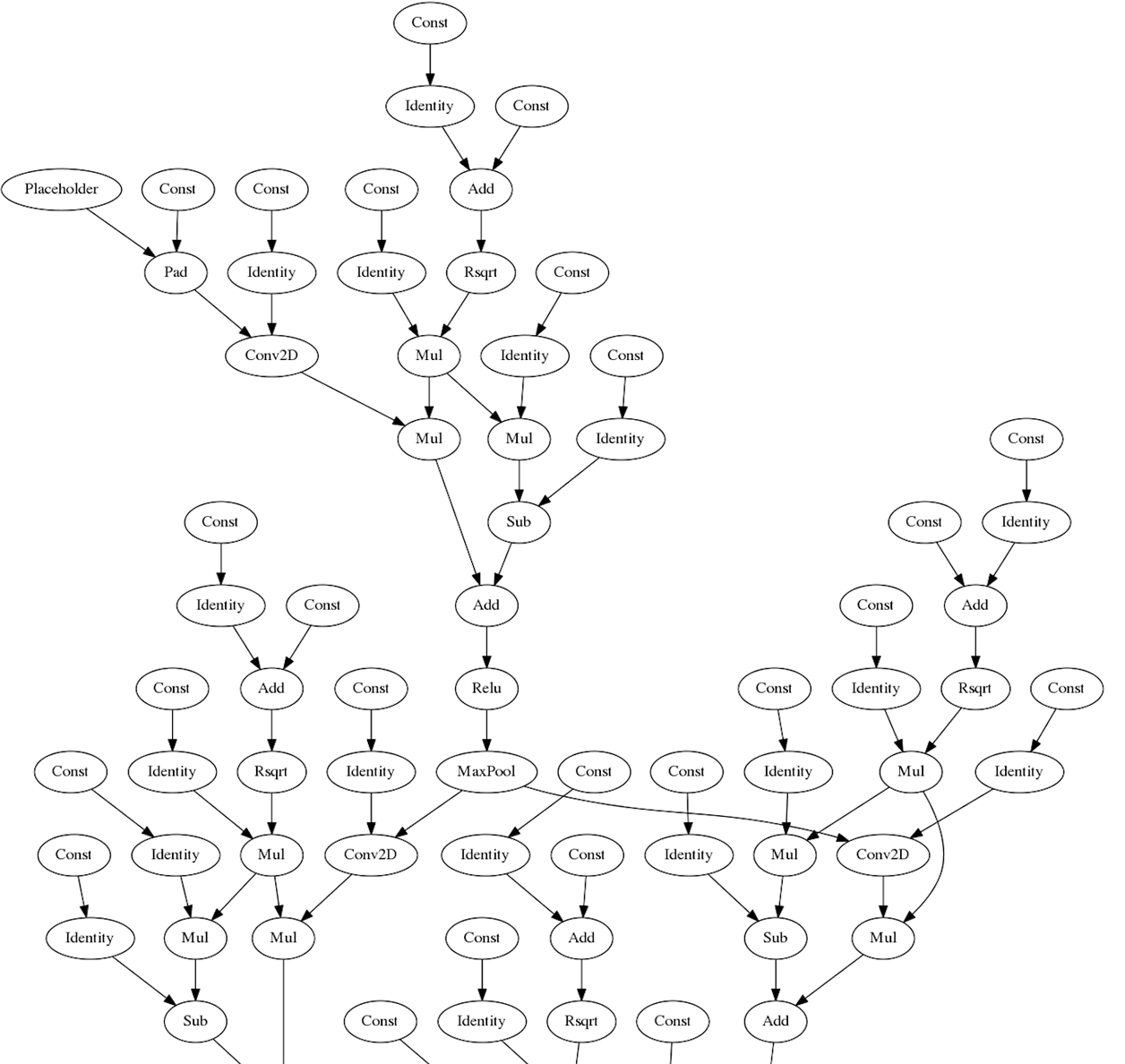
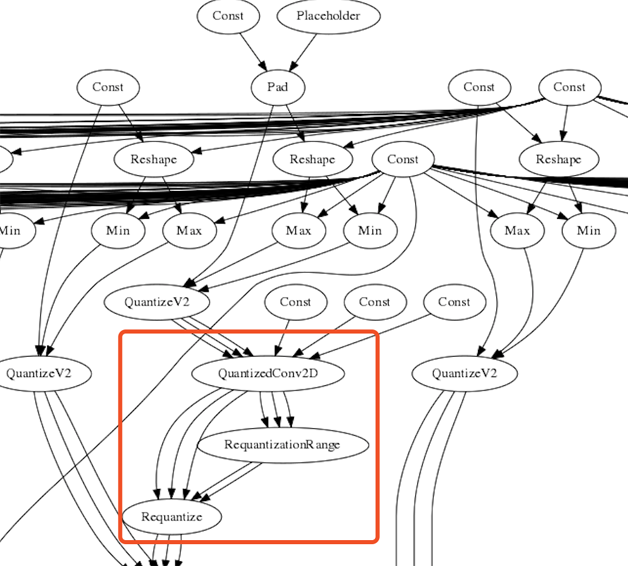
圖11僅僅對權重進行量化,沒有計算輸入圖片的最值範圍的視覺化模型。可以看出原本的Conv2D等節點都轉換為QuantizedConv2D的對應節點。並且在進行QuantizedConv2D操作後,得到INT32型別的記過,需要對操作的結果轉換為8位(ReQuantize操作),而轉換的過程需要知道INT32結果的最值範圍,因此也加入了ReQuantizationRange節點。
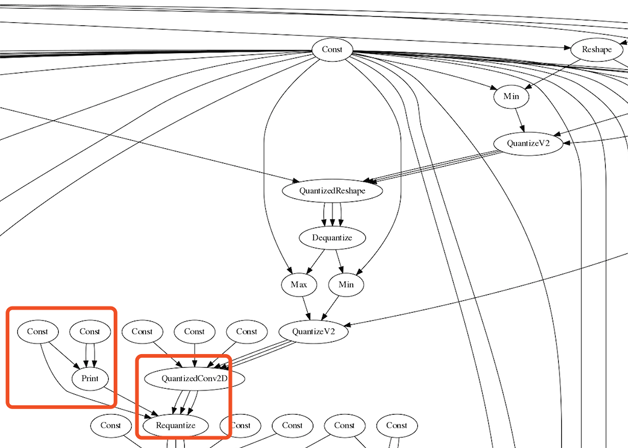
如果已經預先使用10張或者1000張圖片計算了每一個Conv2D等操作之後需要計算的範圍,則ReQuantizationRange的計算過程就可以省去,直接從儲存的計算好最值檔案中讀取。如圖12所示。
其他建議
在效能受限環境下,對開發者還有沒有技術和工程實現方面的其他建議呢?
設計小模型
可以將模型大小做為約束,在模型結構設計和選擇時便加以考慮。例如,對於全連線,使用 bottleneck是一個有效的手段。
例如,我們使用TensorFlow官方網站提供的預訓練好的Inception V3模型在此花卉資料集上進行訓練。在專案根目錄下執行:
```py python tensorflow/examples/image_retraining/retrain.py \ --bottleneck_dir=/tmp/bottlenecks/ \ --how_many_training_steps 10 \ --model_dir=/tmp/inception \ --output_graph=/tmp/retrained_graph.pb \ --output_labels=/tmp/retrained_labels.txt \ --image_dir /tmp/flower_photos ```訓練完成後,可以在/tmp下看到生成的模型檔案retrained_graph.pb(大小為83M)和標籤檔案retrained_labels.txt。
我們看到,上述命令列中儲存和使用了“瓶頸”(bottlenecks)檔案。瓶頸是用於描述實際進行分類的最終輸出層之前的層(倒數第二層)的非正式術語。倒數第二層已經被訓練得很好,因此瓶頸值會是一個有意義且緊湊的影象摘要,並且包含足夠的資訊使分類器做出選擇。因此,在第一次訓練的過程中,retrain.py檔案的程式碼會先分析所有的圖片,計算每張圖片的瓶頸值並存儲下來。因為每張圖片在訓練的過程中會被使用多次,因此在下一次使用的過程中,可以不必重複計算。這裡用tulips/9976515506_d496c5e72c.jpg為例,生成的瓶頸檔案為tulips/9976515506_d496c5e72c.jpg.txt,內容如圖13所示。

再如,Highway、ResNet、DenseNet這些帶有skip connection結構的模型,也可以用來作為設計窄而深網路的參考,從而減少模型整體引數量和計算量。
還如,SqueezeNet網路結構中通過引入1x1的小卷積核、減少feature map數量等方法,最終將模型大小壓縮在1M以內,分類精度與AlexNet相當,而模型大小僅是AlexNet的1/50。
模型小型化
一般採用知識蒸餾。在利用深度神經網路解決問題時,人們常常傾向於設計更復雜的網路,來得到更優的效能。蒸餾模型是採用是遷移學習,通過採用預先訓練好的複雜模型(Teacher model)的輸出作為監督訊號去訓練另外一個簡單的網路,得到的簡單的網路稱之為Student model。實驗表明,蒸餾模型的方法在MNIST及聲學建模等任務上都有著很好的表現。
總結
隨著深度學習模型在嵌入式端的應用越來越豐富,例如安防、工業物聯網、智慧機器人等裝置,需要解決影象、語音場景下深度學習的加速問題,減小模型大小及計算量,構建高效能神經網路模型。
本文重點講解模型壓縮和剪枝方法帶來的模型大小和計算量的下降,並且能使精度維持在較高水平。除此之外,剪枝的敏感度分析和重新訓練(Retrain)也有很多不同的手段;量化也可以在更低精度(5bit、6bit、甚至二值網路)上嘗試,筆者也正在進行相關實驗,期待和讀者一起探討。
更多案例請關注“思享會Club”公眾號或者關注思享會部落格:http://gkhelp.cn/
