
王權富貴:強化學習Q-learning
參考文章:(感謝辛勤翻譯的小哥哥小姐姐誒)
作者: peghoty
出處: http://blog.csdn.net/peghoty/article/details/9361915
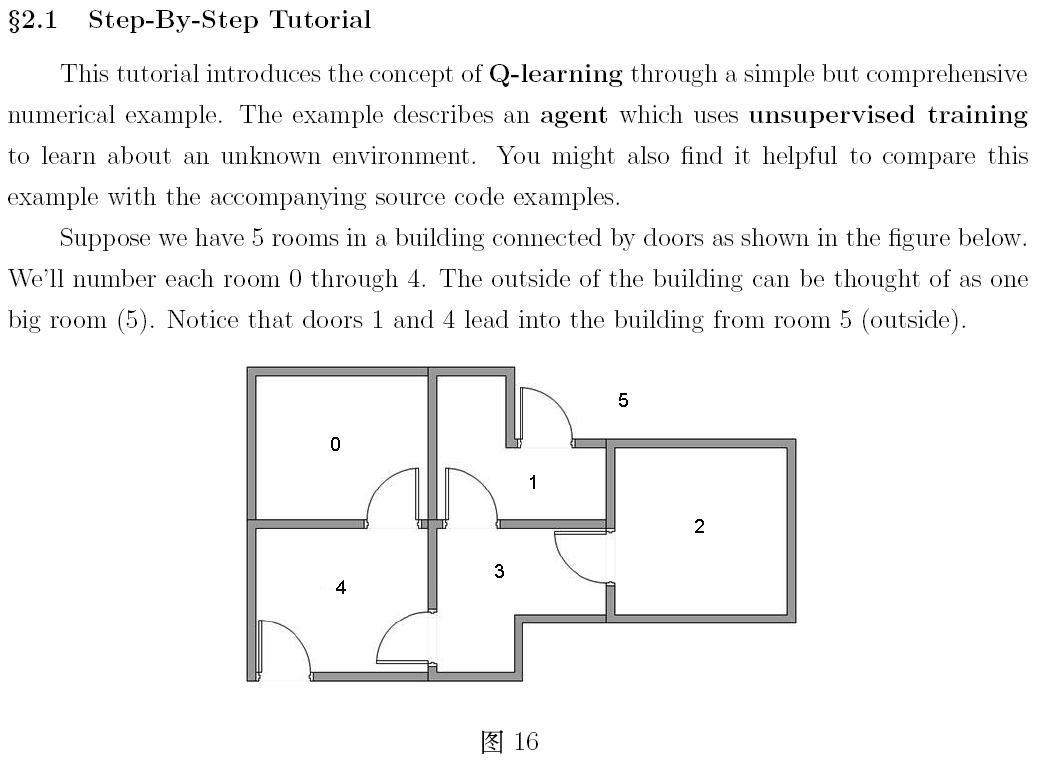
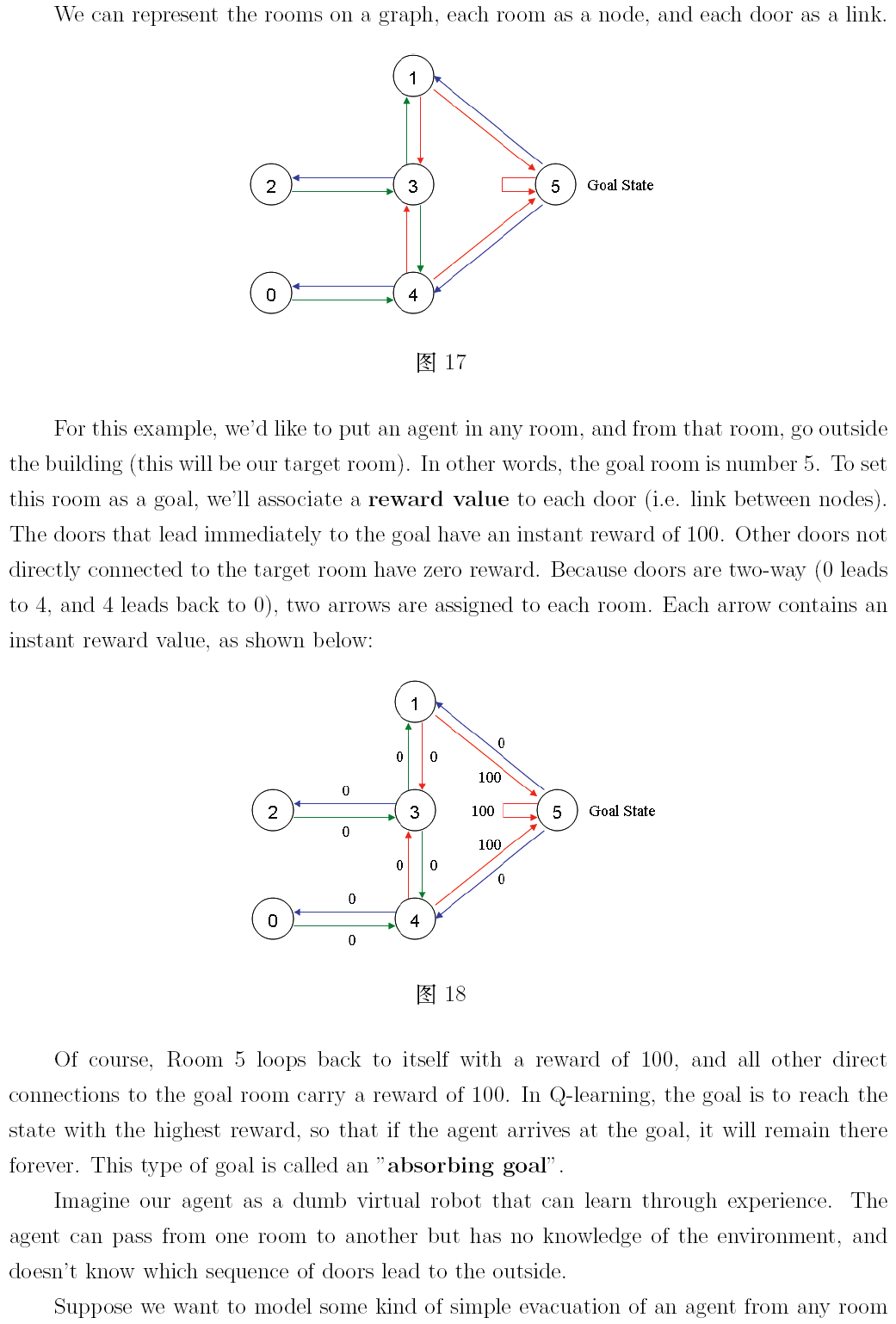
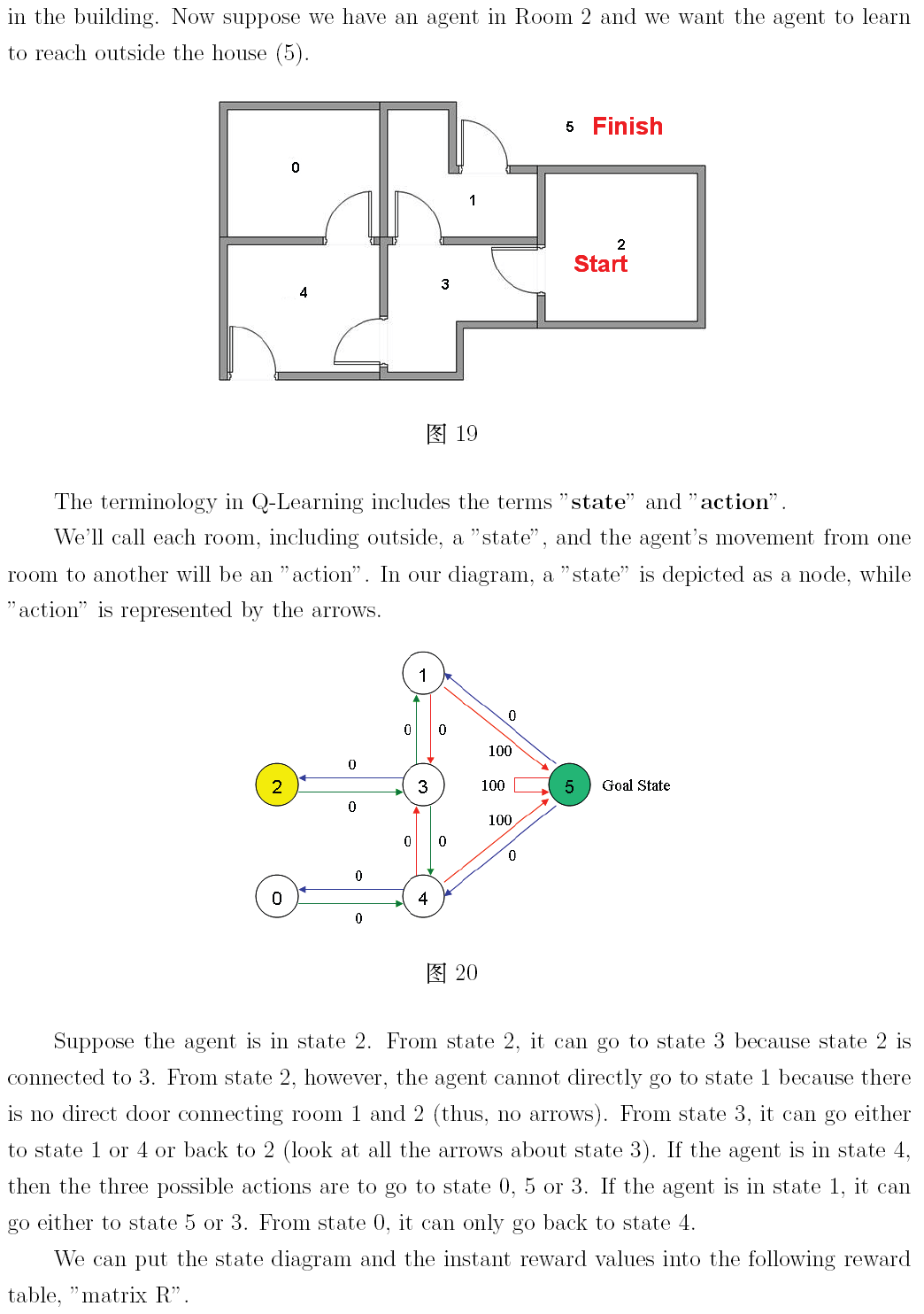
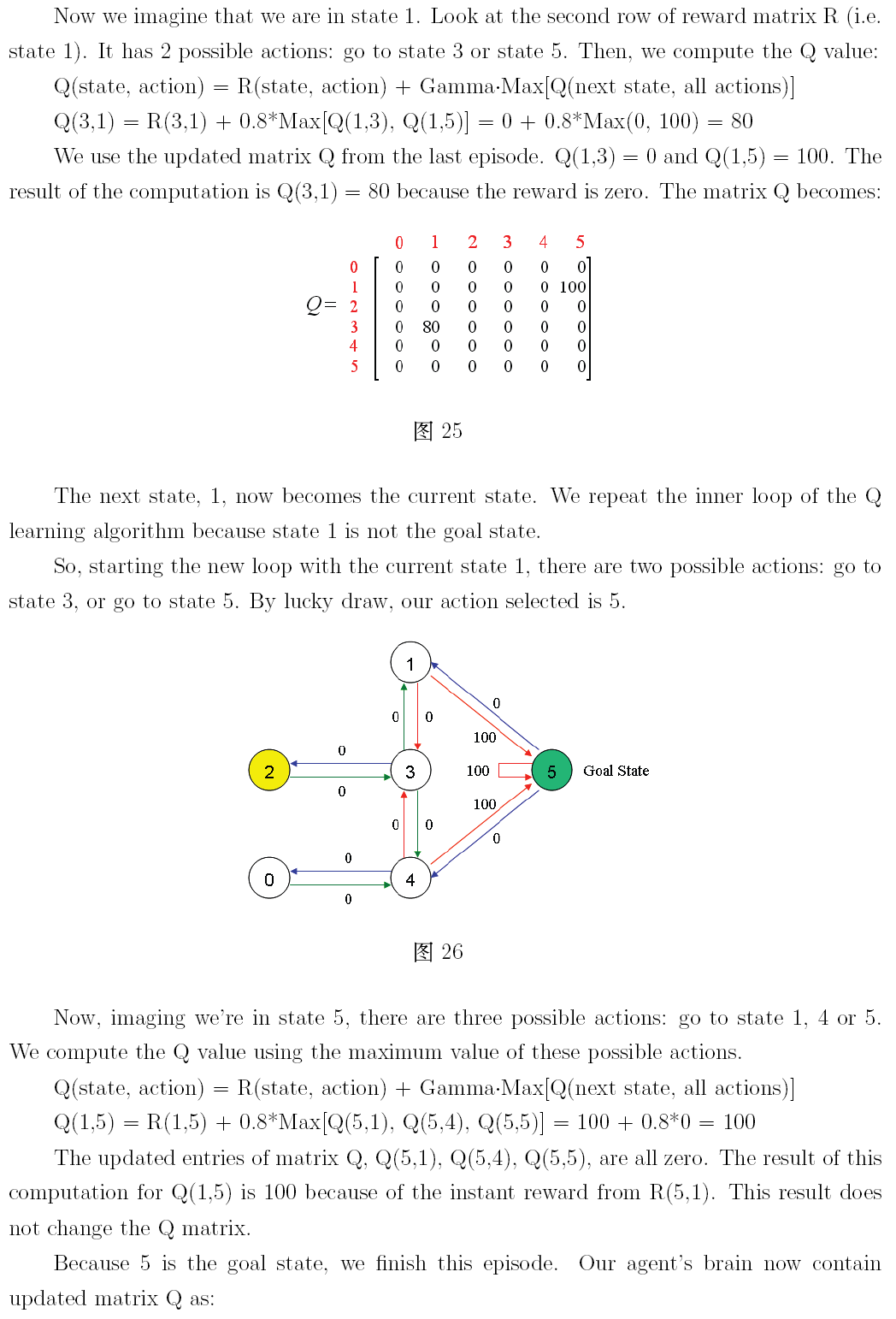
本文是對 http://mnemstudio.org/path-finding-q-learning-tutorial.htm 的翻譯,共分兩部分,第一部分為中文翻譯,第二部分為英文原文。翻譯時為方便讀者理解,有些地方採用了意譯的方式,此外,原文中有幾處筆誤,在翻譯時已進行了更正。這篇教程通俗易懂,是一份很不錯的學習理解 Q-learning 演算法工作原理的材料。
第一部分:中文翻譯
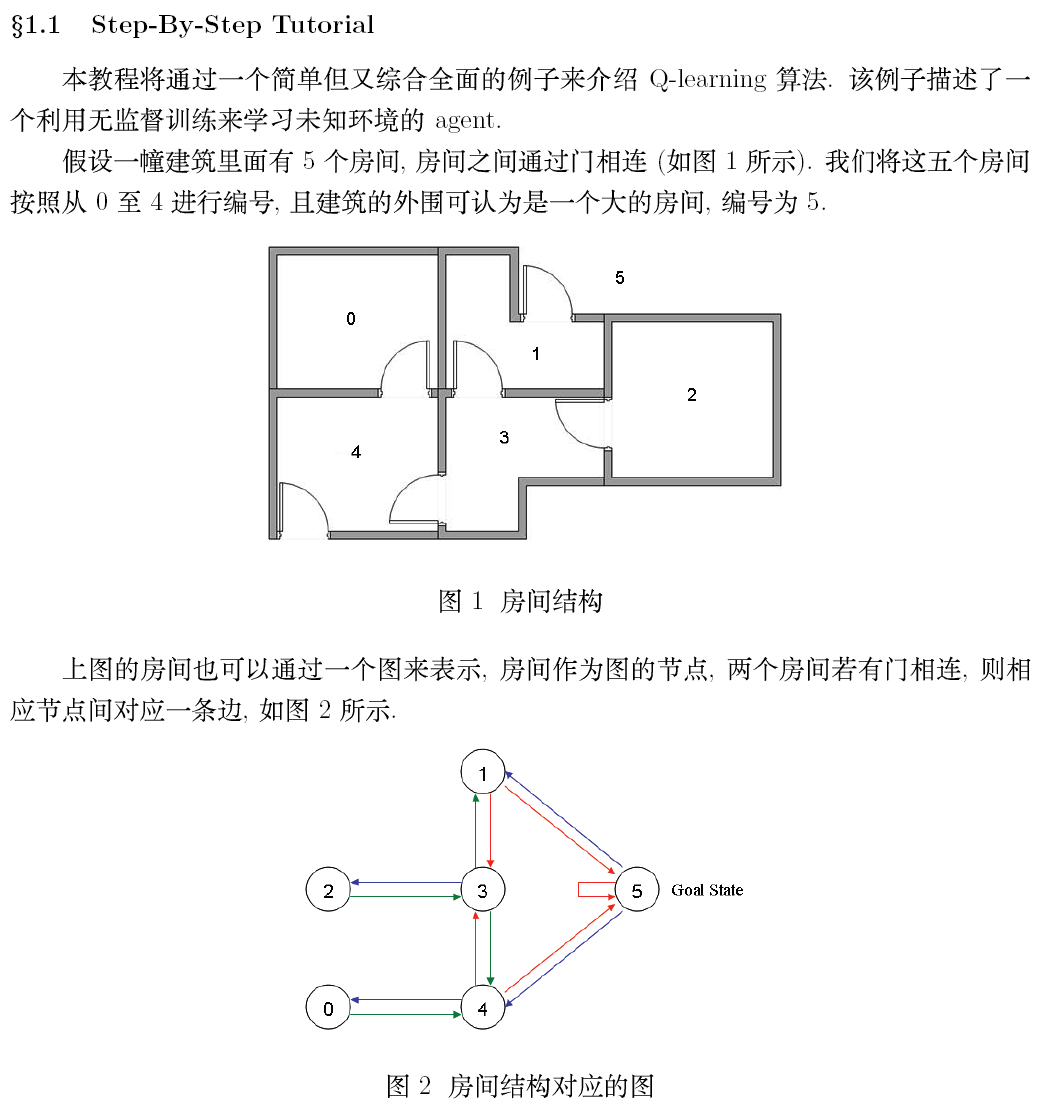
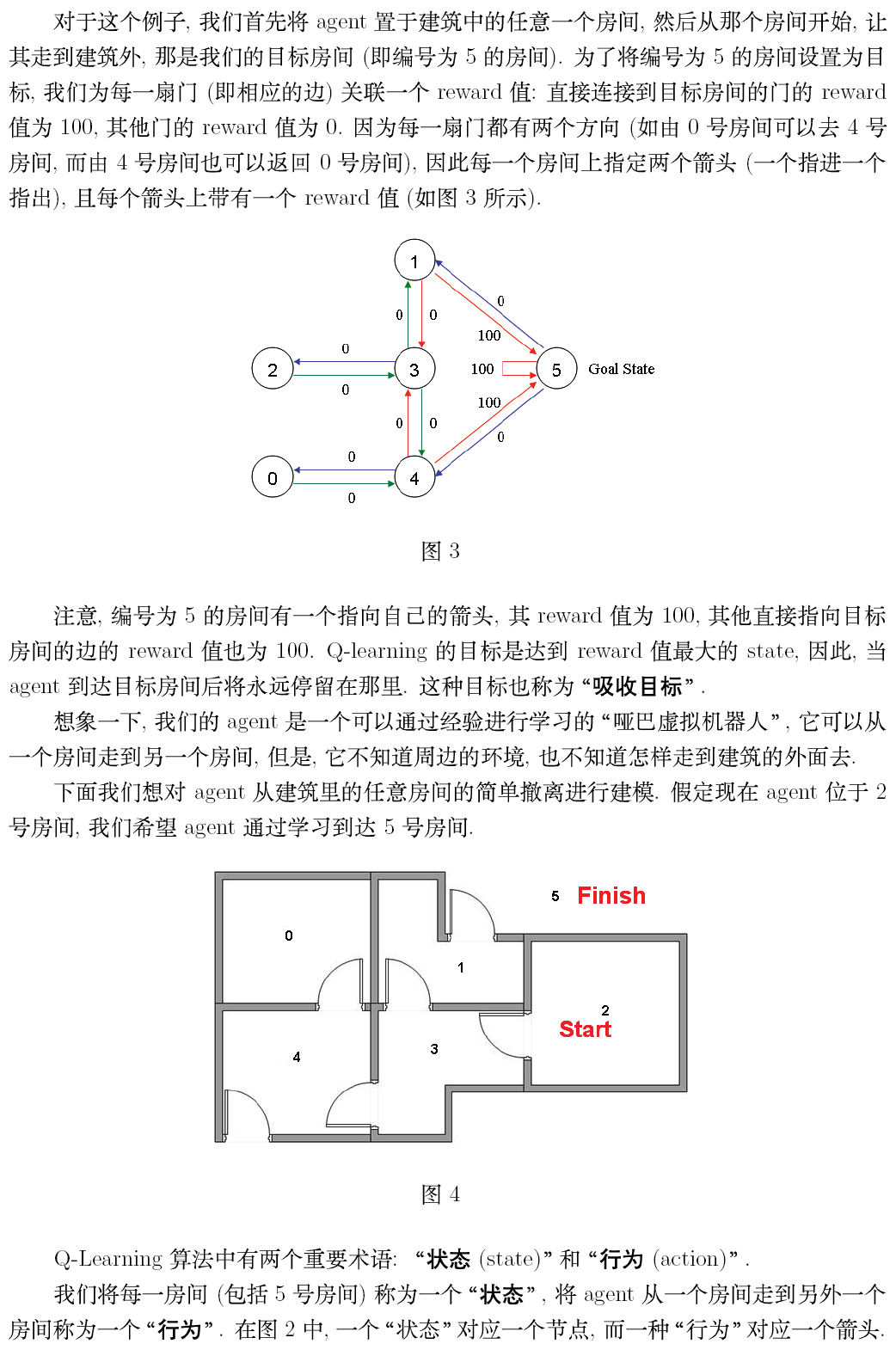



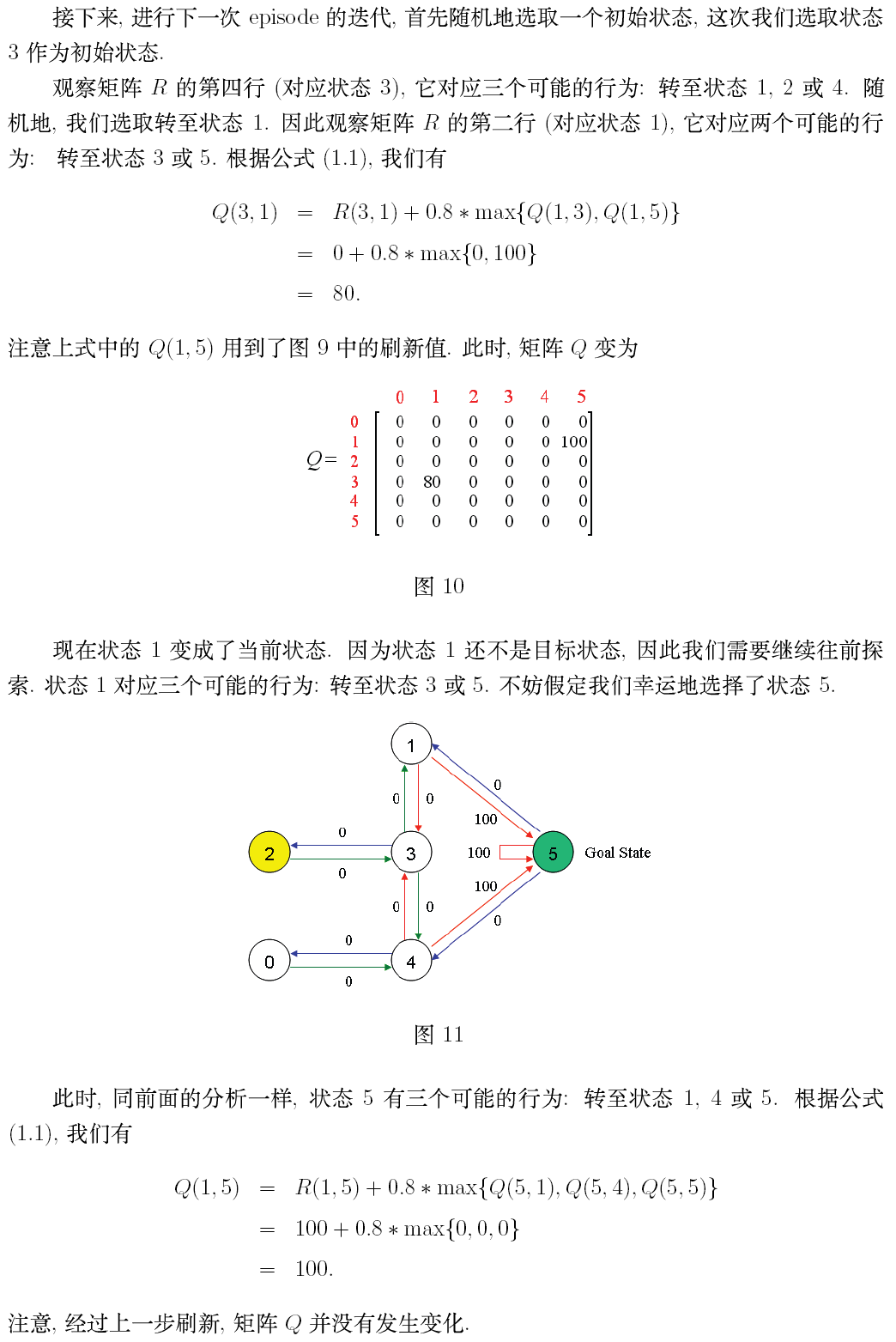

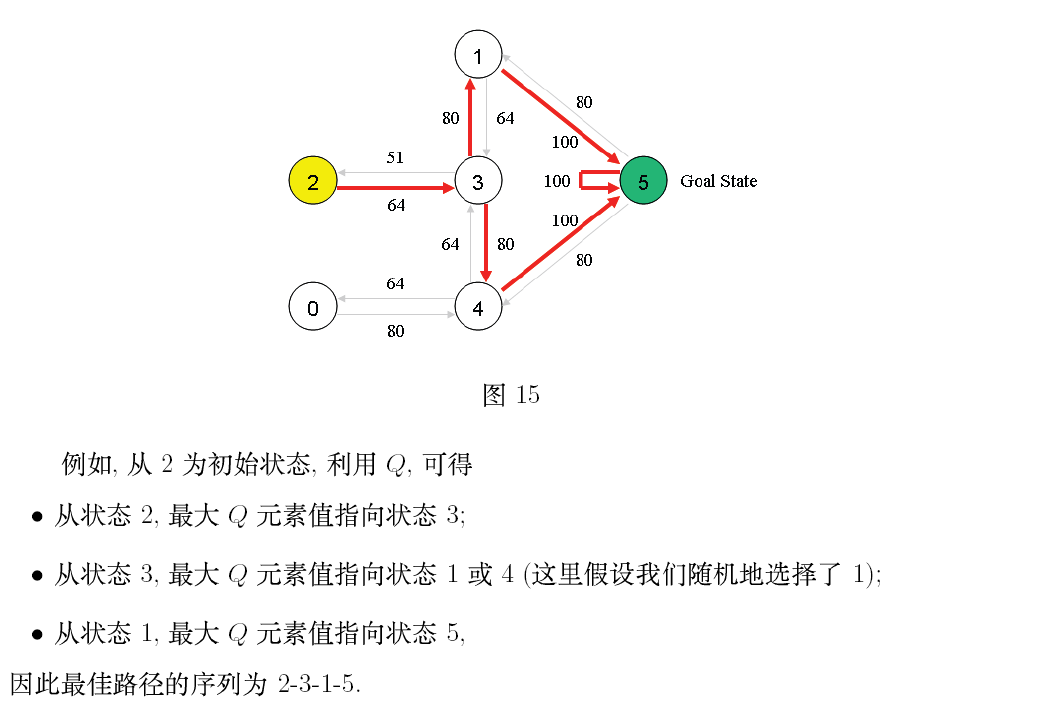
第二部分:英文原文




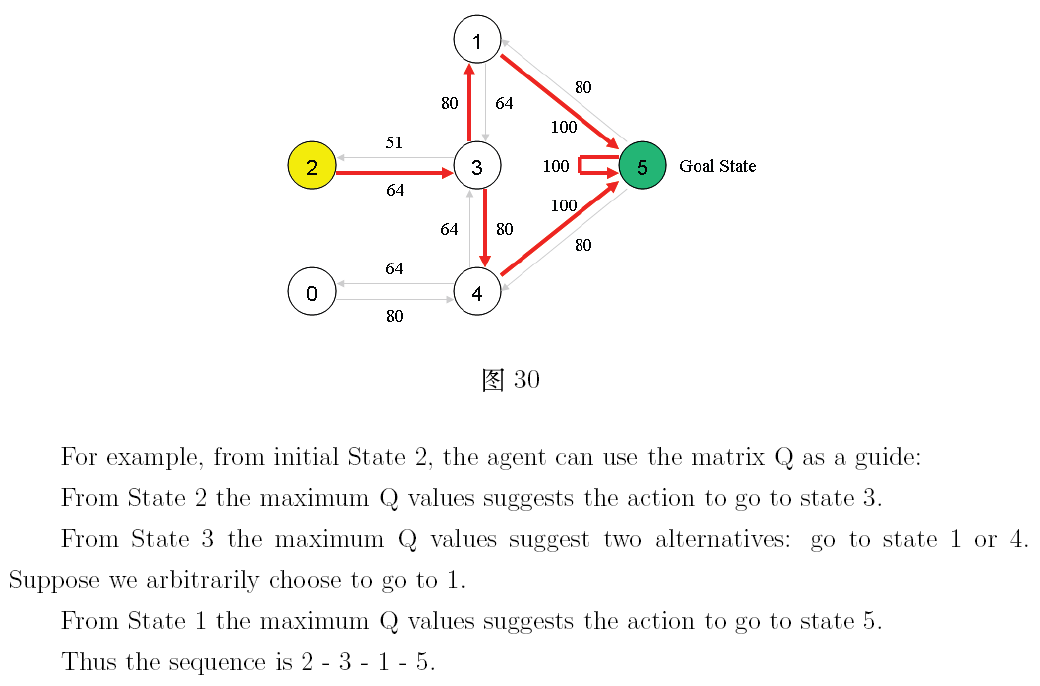
作者: peghoty
出處: http://blog.csdn.net/peghoty/article/details/9361915
歡迎轉載/分享, 但請務必宣告文章出處
最後附一張演算法的虛擬碼:

相關推薦
王權富貴:強化學習Q-learning
參考文章:(感謝辛勤翻譯的小哥哥小姐姐誒) 作者: peghoty 出處: http://blog.csdn.net/peghoty/article/details/9361915 本文是對 http://mnemstudio.org/path-fin
強化學習-Q-learning
原文:https://www.jianshu.com/p/29db50000e3f?utm_medium=hao.caibaojian.com&utm_source=hao.caibaojian.com 1、Q-learning例子 假設有這樣的房間 如果將房間表示成點,然
強化學習Q-learning 和 Sarsa
Q-learning Q表示的是,在狀態s下采取動作a能夠獲得的期望最大收益,R是立即獲得的收益,而未來一期的收益則取決於下一階段的動作。 更新公式 Q(S,A) ← (1-α)*Q(S,A) + α*[R + γ*maxQ(S',a)], alpha 是學習率,
強化學習導論(Reinforcement Learning: An Introduction)讀書筆記(一):強化學習介紹
因為課題轉到深度強化學習方面,因此開始研究強化學習的內容,同時在讀這方面的書,並將Reinforcement Learning: An Introduction(Richard S. Sutton and Andrew G.Barto)第二版作為主要的學習資料,
強化學習_Q-learning 算法的簡明教程
化學 learning 9.png nbsp AR mage ear bubuko learn 強化學習_Q-learning 算法的簡明教程
強化學習Q-leaning演算法之走迷宮
來自於莫凡大神的強化學習教程,今天學習了走迷宮的小例子。網站網址是:https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/2-2-A-q-learning/ 程式碼如下,一些地方我做了註釋
王權富貴:SyntaxError: Non-ASCII character '\xe4' in file C:/.....on line 5, but no encoding declared; se
原因: 在編寫Python時,當使用中文輸出或註釋時,執行指令碼會提示錯誤資訊: SyntaxError: Non-ASCII character '\xe5' in file ******* 解決方法: python的預設編碼檔案是用的ASCII碼,你將檔案存成了UTF-8,
王權富貴:安裝OpenCV匯入的時候出現DLL load failed:找不到指定模組 or %1不是有效的32位程式
問題: 網上找了好多方法 (1)版本不匹配(失敗) (2)安裝microsoft Visual C++ distributed 2015 X64(失敗) (3)升級window10(沒有嘗試) (3)複製什麼什麼檔案到什麼什麼目錄下(失敗) (4)ht
王權富貴:Faster-Rcnn詳解
背景 這一切始於 2014 年的一篇論文「Rich feature hierarchies for accurate object detection and semantic segmentation」(R-CNN),其使用了稱為 Selective Search 的演算法用來提取感興趣候選區
王權富貴:RCNN的成長曆程
暴力目標檢測 &n
王權富貴:VOC2007資料集格式詳解和下載
VOC2012和VOC2007的下載地址: https://pjreddie.com/projects/pascal-voc-dataset-mirror/ Annotations資料夾 該檔案下存放的是
王權富貴:GPU配套的計算能力
CUDA-Enabled Tesla Products Tesla Workstation Products GPU Compute Capability Tesla K80 3.7
王權富貴:讀取指定目錄下的所有檔名(不保持字尾)文字處理
import os import os.path as osp rootdir = "C:\YSRVOC\VOCdevkit\VOC2007\JPEGImages" file_object = open('C:\YSRVOC\VOCdevkit\VOC2007\ImageSets\Main/tr
王權富貴:faster_rcnn在Linux伺服器上(無介面)編譯
環境: CPU: I7 GPU: GTX1070 計算能力: 6.1 裝置ID: 0 參考: https://blog.csdn.net/hitzijiyingcai/article/det
【機器學習系列文章】第5部分:強化學習
目錄 你做到了! 結束思考 探索和開發。馬爾可夫決策過程。Q-learning,政策學習和深度強化學習。 “我只吃了一些巧克力來完成最後一節。” 在有監督的學習中,訓練資料帶有來自某些神聖的“主管”的答案。如果只有這樣的生活! 在強化學
Deeplearning4j 實戰 (9):強化學習 -- Cartpole任務的訓練和效果測試
在之前的部落格中,我用Deeplearning4j構建深度神經網路來解決監督、無監督的機器學習問題。但除了這兩類問題外,強化學習也是機器學習中一個重要的分支,並且Deeplearning4j的子專案--Rl4j提供了對部分強化學習演算法的支援。這裡,就以強化學習中的經典任務--Cartpole問題作
學習筆記:強化學習之A3C程式碼詳解
寫在前面:我是根據莫煩的視訊學習的Reinforce learning,具體程式碼實現包括Q-learning,SARSA,DQN,Policy-Gradient,Actor-Critic以及A3C。(莫凡老師的網站:https://morvanzhou.git
機器學習筆記(八):強化學習
前面我們介紹的機器學習演算法都屬於人工餵給機器資料,然後機器從這些資料中學得模型。而我們人類的學習過程並不是這樣,人類通過自身的感官感知環境,而後從環境中獲得經驗、知識,因此單純地依靠前面所介紹的方法並不能實現通用人工智慧。那麼有沒有辦法使得機器也能自動地不斷從周圍環境中獲得經驗或‘知識’呢?阿蘭。
強化學習 Q學習原理及例子(離散)附matlab程式
原文地址:http://mnemstudio.org/path-finding-q-learning-tutorial.htm 這篇教程通過簡單且易於理解的例項介紹了Q-學習的概念知識,例子描述了一個智慧體通過非監督學習的方法對未知的環境進行學習。 假設我們的樓層內共有5個房間,
[強化學習]OpenAI官方釋出:強化學習中的關鍵論文
【導讀】OpenAI 在教學資源合集 Spinning Up中釋出了強化學習中的關鍵論文,列舉了強化學習不同領域的代表性文章來指導研究者的學習。此外Spinning Up 包含清晰的 RL 程式碼示例、習題、文件和教程可供參考。 1. Model-Free RL 2. Explora