
Spark介紹(四)SparkSQL
一、SparkSQL發展歷程
SparkSQL的前身是Shark, Shark是伯克利實驗室Spark生態環境的元件之一,它修改了下圖Hive所示的右下角的記憶體管理、物理計劃、執行三個模組,並使之能執行在Spark引擎上,從而使得SQL查詢的速度得到10-100倍的提升
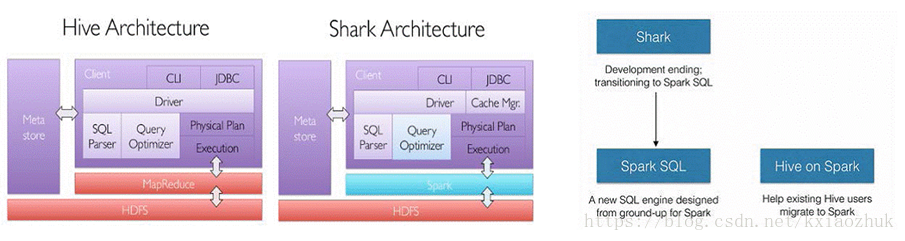
2014年6月1日Shark專案和SparkSQL專案的主持人Reynold Xin宣佈:停止對Shark的開發,團隊將所有資源放SparkSQL專案上,至此,Shark的發展畫上了句話,但也因此發展出兩個直線:SparkSQL和Hive on Spark
二、SparkSQL執行架構
類似於關係型資料庫,SparkSQL
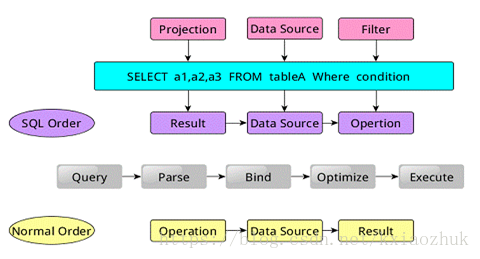
SparkSQL對SQL語句的處理和關係型資料庫對SQL語句的處理採用了類似的方法,首先會將SQL語句進行解析(Parse),然後形成一個Tree,在後續的如繫結、優化等處理過程都是對Tree的操作,而操作的方法是採用Rule,通過模式匹配,對不同型別的節點採用不同的操作。在整個sql語句的處理過程中,Tree和Rule相互配合,完成了解析、繫結(在SparkSQL中稱為Analysis)、優化、物理計劃等過程,最終生成可以執行的物理計劃。
三、SparkSQL
Spark1.2前, schemaRDDs由行物件組成,行物件擁有一個模式來描述行中每一列的資料型別
Spark1.3
通過registerTempTable註冊成臨時表,然後通過SQL語句進行操作
SparkSQL有兩個分支,sqlContext和hiveContext,sqlContext現在只支援SQL語法解析器(SQL-92語法);hiveContext現在支援SQL語法解析器和hivesql語法解析器,預設為hiveSQL語法解析器,使用者可以通過配置切換成SQL語法解析器,來執行hiveSQL不支援的語法