
Spark介紹(五)Spark MLlib
一、Spark MLlib簡介
MLlib(Machine Learnig lib) 是Spark對常用的機器學習演算法的實現庫,同時包括相關的測試和資料生成器
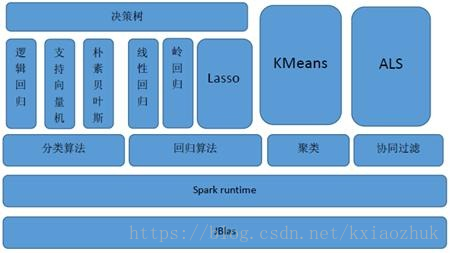
MLlib支援本地的密集向量和稀疏向量,並且支援標量向量(LabledPoint )。
MLlib同時支援本地矩陣和分散式矩陣,支援的分散式矩陣分為RowMatrix、IndexedRowMatrix、CoordinateMatrix等。
相關推薦
Spark介紹(五)Spark MLlib
一、Spark MLlib簡介 MLlib(Machine Learnig lib) 是Spark對常用的機器學習演算法的實現庫,同時包括相關的測試和資料生成器 MLlib支援本地的密集向量和稀疏向量,並且支援標量向量(LabledPoint )。 MLlib同時支援本地
Spark 系列(五)—— Spark 執行模式與作業提交
一、作業提交 1.1 spark-submit Spark 所有模式均使用 spark-submit 命令提交作業,其格式如下: ./bin/spark-submit \ --class <main-class> \ # 應用程式主入口類 --master <maste
大資料之Spark(五)--- Spark的SQL模組,Spark的JDBC實現,SparkSQL整合MySQL,SparkSQL整合Hive和Beeline
一、Spqrk的SQL模組 ---------------------------------------------------------- 1.該模組能在Spack上執行Sql語句 2.可以處理廣泛的資料來源 3.DataFrame --- RDD --- tabl
Spark介紹(六)SparkR
一、SparkR簡介 SparkR是一個R語言包,它提供了輕量級的方式使得可以在R語言中使用Apache Spark。在Spark 1.4中,SparkR實現了分散式的data frame,支援類似查詢、過濾以及聚合的操作(類似於R中的data frames:dplyr),但
Spark介紹(四)SparkSQL
一、SparkSQL發展歷程 SparkSQL的前身是Shark, Shark是伯克利實驗室Spark生態環境的元件之一,它修改了下圖Hive所示的右下角的記憶體管理、物理計劃、執行三個模組,並使之能執行在Spark引擎上,從而使得SQL查詢的速度得到10-100倍的提升 2014年6
Spark介紹(三)SparkStreaming
一、SparkStreaming簡介 SparkStreaming是一個對實時資料流進行高通量、容錯處理的流式處理系統,可以對多種資料來源(如Kdfka、Flume、Twitter、Zero和TCP 套接字)進行類似Map、Reduce和Join等複雜操作,並將結果儲存到外部檔案系統、
Spark介紹(二)RDD
一、RDD介紹 彈性分散式資料集,RDD是Spark最核心的東西,它表示已被分割槽,不可變的並能夠被並行操作的資料集合,不同的資料集格式對應不同的RDD實現。 RDD的特點: 1.來源:一種是從持久儲存獲取資料(並行化集合或Hadoop資料集),另一種是從其他RDD生成 2.只讀:狀
Spark介紹(一)簡介
一、Spark簡介 Spark是加州大學伯克利分校AMP實驗室(Algorithms, Machines, and People Lab)開發的通用記憶體平行計算框架 Spark使用Scala語言進行實現,它是一種面向物件、函數語言程式設計語言,能夠像操作本地集合物件一樣輕鬆地操作分散式資料
Spark學習(一)--Spark入門介紹和安裝
本次主要介紹spark的入門概念和安裝 Spark概念 Spark安裝 Spark HA 高可用部署 1. Spark概念 1.1 什麼是Spark Spark 是一種快速、 通用、 可擴充套件的大資料分析引擎, 2009 年誕生於加州大學伯克利分校 AM
Spark學習(五)---RDD原理解析和spark執行架構
這次我們介紹RDD的原理和spark執行機制 RDD依賴關係 RDD快取 RDD容錯機制 spark執行架構 spark任務排程 1. RDD原理 首先我們對之前的單詞統計的程式碼做一個畫圖展示 1.1 RDD依賴關係 RDD和它依賴的父RDD的關係有兩
Spark學習(一)Spark介紹
一、什麼是spark spark是基於記憶體計算的大資料平行計算框架,也是hadoop中的mapreduce的替代方案,但和mapreduce又有許多不同。 Spark包含了大資料領域常見的各種計算框架:比如Spark Core用於離線計算,Spark SQL
Spark (Python版) 零基礎學習筆記(五)—— Spark RDDs程式設計
RDD基礎概念 建立RDD 建立RDD的方法: 1.載入外部資料集 2.分佈一個物件的集合 前邊幾次的筆記已經提到過多次了,因此,這裡只列出幾個注意事項: 1.利用sc.parallelize建立RDD一般只適用於在測試的時候使用,因為這需要我們將整
Appium python自動化測試系列之Capability介紹(五)
語言 路徑 pla apk 過程 5.1 基礎 針對 driver ?5.1 Capability介紹 5.1.1 什麽是Capability 在講capability之前大家是否還記得在講log時給大家看過的啟動時的日誌?在我們的整個啟動日誌中會出現一些配置信息,其實那些
【PP生產訂單】入門介紹(五)
生產訂單的下達: 只有訂單下達之後才可以做如下操作: 1、系統標準的列印功能; 2、物料發料; 3、處理; 4、確認; 5、收貨; 6、結算。 其中有效性檢查不需要訂單下達就可以做。 下面著重介紹一下生產訂單的狀態: 演變過程展示:
Spark學習(拾)- Spark Streaming進階與案例實戰
實戰之updateStateByKey運算元的使用 updateStateByKey操作允許您在使用新資訊不斷更新狀態的同時維護任意狀態。要使用它,您需要執行兩個步驟。 1、定義狀態——狀態可以是任意資料型別。 2、定義狀態更新函式——用函式指定如何使用以前的狀態和輸入流中的新值更新
Spark學習(玖)- Spark Streaming核心概念與程式設計
文章目錄 核心概念之StreamingContext 核心概念之DStream 核心概念之Input DStreams和Receivers 基本資源 高階資源 核心概念之Transformat
Spark學習(捌)- Spark Streaming入門
文章目錄 spark概念 Spark Streaming應用場景 Spark Streaming整合Spark生態系統的使用 Spark Streaming發展史 從詞頻統計功能著手入門Spark Streaming
Spark學習(柒)- Spark SQL擴充套件和總結
文章目錄 Spark SQL使用場景 Spark SQL載入資料 1) RDD DataFrame/Dataset 2) Local Cloud(HDFS/S3) DataFrame與SQL的對比
Spark學習(陸)- Spark操作外部資料來源
文章目錄 產生背景 概念 目標 操作Parquet檔案資料 操作Hive表資料 操作MySQL表資料 操作MySQL的資料方法一: 操作MySQL的資料方法二: 操作MySQL
Spark Streaming(01)——Spark Streaming概述
1、Spark Streaming是什麼? Spark Streaming類似於Apache Storm,用於流式資料的處理。 Spark Streaming有高吞吐量和容錯能力強等特點。且支援的資料來源有很多,例如:Kafka、Flume、Twitter、Z