
Spark介紹(三)SparkStreaming
一、SparkStreaming簡介
SparkStreaming是一個對實時資料流進行高通量、容錯處理的流式處理系統,可以對多種資料來源(如Kdfka、Flume、Twitter、Zero和TCP 套接字)進行類似Map、Reduce和Join等複雜操作,並將結果儲存到外部檔案系統、資料庫或應用到實時儀表盤。

Spark Streaming處理的資料流圖

Spark
二、DStream簡介
1.Dstream離散流由一系列連續的RDD組成,每個RDD都包含了確定時間間隔內的資料。

2.對DStream中資料的各種操作也是對映到內部的RDD上來進行的
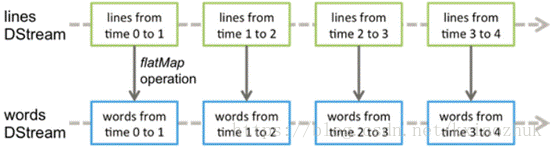
3.Dstream的輸入源包括基本源(檔案系統和Socket(套接字)連線)和高階源( Kafka、Flume、Kinesis、Twitter 等,額外增加類依賴)
三、DStream操作
1.1普通的轉換操作:map、flatMap、flter、union、count、join等
1.2transform(func)操作:允許DStream
1.3updateStateByKey操作:
1.4視窗轉換操作: 允許你通過滑動視窗對資料進行轉換,如countByWindow、 reduceByKeyAndWindow等,(批處理間隔、視窗間隔和滑動間隔)
2.輸出操作:允許DStream的資料被輸出到外部系統,如資料庫或檔案系統,有print()、foreachRDD(func)、saveAsTextFiles()、 saveAsHadoopFiles()等
3.持久化:通過persist()方法將資料流存放在記憶體中,有利於高效的迭代運算