
【論文閱讀】Aggregated Residual Transformations for Deep Neural Networks Saining(ResNext)
這篇文章是kaiming大神的組的工作,在resnet上繼續改進。一作謝賽寧,2013年從上海交大本科畢業後去UCSD讀博士,現在他引1400+了(不知道我畢業時能不能有這個的一半QAQ),導師是Zhuowen Tu。
Introduction
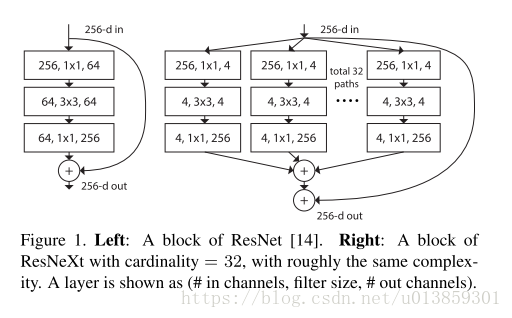
現代的網路設計中通常會次堆疊類似結構,如VGG,Inception,Resnet等,從而減少網路中超引數的數量,簡化網路設計。
Inception使用了split-transform-merge策略,即先將輸入分成幾部分,然後分別做不同的運算,最後再合併到一起。這樣可以在保持模型表達能力的情況下降低運算代價。
但是Inception的結構還是過於複雜了。作者想,我直接暴力均分輸入,卷積層結構都是一樣的,然後再merge。這樣的話我只需要告訴網路分成幾組就可以了,不就不需要再設計那麼精巧的Inception了嗎?
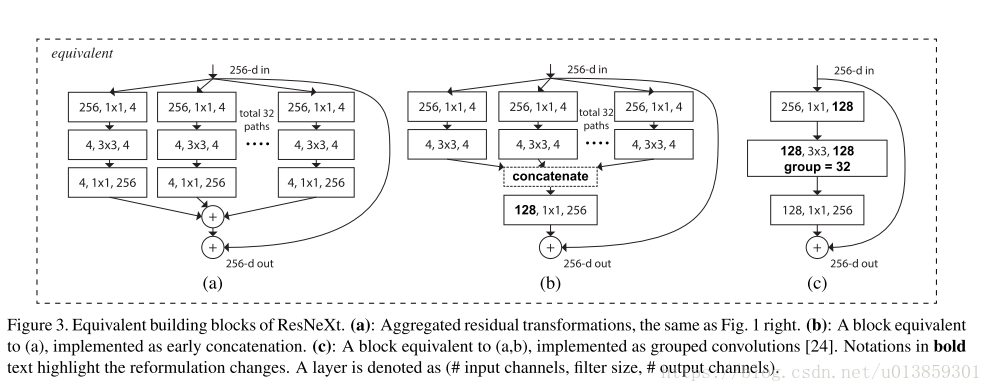
圖3中的三種結構實際上是等價的。但是這種結構早在2012年AlexNet被髮明出來的時候實際上已經被使用了。當初是因為一張顯示卡不夠用,必須要將卷積放到兩張顯示卡上算。因此現在幾乎所有的神經網路框架的conv層都有group這個引數,但在作者之前就是沒人把這個group作為超引數調一下(這是個很有意思的問題,明明框架裡有,為啥大家不試試呢)。作者後來提到之前做網路壓縮的人提出過group的方法,但是卻極少有人研究其精度,這篇文章是從模型表達和精度的方向上寫的。
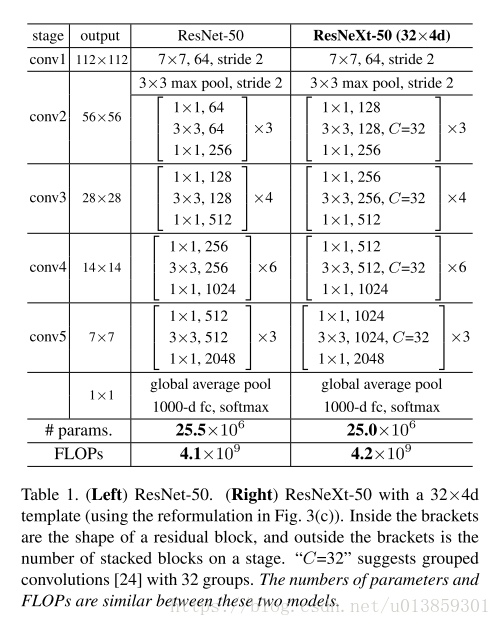
這種結構可以在保持網路的計算量和引數尺寸的情況下,提高分類精度。(論文裡沒有提到的是,雖然引數不變,但是視訊記憶體增加了)。如表一中顯示的,兩邊的網路具有相同的引數和計算量,但是右側會有更好的精度。
就是這樣一個看似簡單的點子,卻有很驚人的效果。作者把他的網路起名ResNeXt,意為ResNet的下一個版本。幾乎在各方面表現吊打了ResNet,Inception等一系列網路。101層的ResNeXt吊打了計算量是他兩倍的ResNet-200。在ImageNet上取得了第二名。
方法
這篇論文的方法其實用一句話就能說清了——卷積里加個group引數,或者是inception把不同的分支調到相同的結構。但是作者既然要發文章,就一定得強行解釋一波他這個結構和conv group以及inception的區別。
模板
網路設計時遵循了兩個原則:
- 如果相同尺寸的層共享相同的超引數。
- 如果影象經過了降取樣層使尺寸除了2,那麼要在通道數上乘2,以保證每個塊的計算量大致相同。
有了上面兩個約束,設計網路的自由度就小了很多。只需要定義出一個模板單元,就可以依次決定後面的單元。表1就是個栗子。
回顧簡單神經元
簡單神經元的形式滿足
因此可以看作是一個整合轉換的過程,即分割——轉換——整合的過程。對於普通神經元來講,分割就是把輸入分成一個個的 ,變換就是乘權重,整合就是相加。
整合轉換
其實在卷積內加分組的方法也可以看作是一個整合轉換的過程。可以寫成下面的形式:
這裡面, 代表任意一種變換,而 則代表要給group。結合圖3A圖食用更佳。
那麼問題來了,說這麼多你這種方法和inception的區別是啥?
inception設計網路太複雜了,我們這個給個引數就行了呀XD
那你這種方法和直接對卷積層分組有什麼區別?
直接對卷積層分組的話每個 對應的 都是一樣的,我們這個可以讓每個都不一樣哦
可是你這個不是一樣的嗎?
都說了是可以不一樣嘛。。我們取一樣的是因為這種形式最簡單。嗯。我們這個方法最牛逼。
模型能力
眾所周知的是模型的表達能力和引數基本上是成正比的。但是採用這種結構後,刻意調整通道數,以保證每層的引數數量和計算量和普通的ResNet相同,結果表達能力居然提高了。
實現細節
這部分沒什麼好說的,用了BN,ReLU,sgd,等等。用了圖3(c)的實現。
實驗
在imagenet1000上做了ablation實驗。把分組數量cardinility從1調到32,錯誤率持續走低。關鍵是在訓練集上的誤差也降低了。也就是說分組不是通過正則化的方法來提高精度的,而是的的確確增加了模型的表達能力。
在image-net5k上訓練出來的模型,在1k上的錯誤率可以和直接在1k上訓練出來的模型一戰。作者認為這是個了不起的成就,畢竟5k的任務要更復雜一些。
之後又在CIFAR-10,100和COCO上測試了,都取得了不錯的效果。
當然這些實驗基本上都是直接和同算力的ResNet對比的。