
computer vision一些術語-目標識別、目標檢測、目標分割、語義分割等
-
- What is the difference between object detection, semantic segmentation and localization?
object recognition(目標識別)
- 給定一幅影象
- 檢測到影象中所有的目標(類別受限於訓練集中的物體類別)
- 得到檢測到的目標的矩形框,並對所有檢測到的矩形框進行分類
Object Recognition: In a given image you have to detect all objects (a restricted class of objects depend on your dataset), Localized them with a bounding box and label that bounding box with a label.

object detection(目標檢測)
- 與object recognition目標類似
- 但只有兩個類別,只需要找到目標所在的矩形框和非目標矩形框
- 例如,人臉檢測(人臉為目標、背景為非目標)、汽車檢測(汽車為目標、背景為非目標)
Object Detection: it’s like Object recognition but in this task you have only two class of object classification which means object bounding boxes and non-object bounding boxes. For example Car detection: you have to Detect all cars in a given image with their bounding boxes.


Object Segmentation(目標分割)
- 與object recognition相似,檢測到影象中的所有目標
- 但是畫素級的,需要給出屬於每一類的所有畫素點,而不是矩形框

Object Segmentation: Like object recognition you will recognize all objects in an image but your output should show this object classifying pixels of the image.
- object recognition:(多類目標)矩形框+類別
- object detection:(兩類目標)矩形框+類別
- Object Segmentation:(多類目標)畫素集+類別
Image Segmentation(影象分割)
- 將給定的影象分割為多個區域
- 每個區域為一類,但不需要給出label
Image Segmentation: In image segmentation you will segment regions of the image. your output will not label segments and region of an image that consistent with each other should be in same segment. Extracting super pixels from an image is an example of this task or foreground-background segmentation.
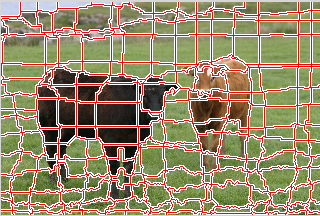
semantic segmentation(語義分割)
- 需要對影象的每一個畫素點進行分類
- 這裡的類別為:多個目標類別和多個非目標類別
Semantic Segmentation: In semantic segmentation you have to label each pixel with a class of objects (Car, Person, Dog, …) and non-objects (Water, Sky, Road, …). I other words in Semantic Segmentation you will label each region of image.

instance segmentation
- 這個還沒懂,待續…..
附一工具
reference:
[1]http://stackoverflow.com/questions/33947823/what-is-semantic-segmentation-compared-to-segmentation-and-scene-labeling
[2]http://computerblindness.blogspot.com/2010/06/object-detection-vs-semantic.html
[3]http://cs.stackexchange.com/questions/51387/what-is-the-difference-between-object-detection-semantic-segmentation-and-local
[4]cs231n.stanford.edu/slides/winter1516_lecture8.pdf
-
- What is the difference between object detection, semantic segmentation and localization?
object recognition(目標識別)
- 給定一幅影象
- 檢測到影象中所有的目標(類別受限於訓練集中的物體類別)
- 得到檢測到的目標的矩形框,並對所有檢測到的矩形框進行分類
Object Recognition: In a given image you have to detect all objects (a restricted class of objects depend on your dataset), Localized them with a bounding box and label that bounding box with a label.
object detection(目標檢測)
- 與object recognition目標類似
- 但只有兩個類別,只需要找到目標所在的矩形框和非目標矩形框
- 例如,人臉檢測(人臉為目標、背景為非目標)、汽車檢測(汽車為目標、背景為非目標)
Object Detection: it’s like Object recognition but in this task you have only two class of object classification which means object bounding boxes and non-object bounding boxes. For example Car detection: you have to Detect all cars in a given image with their bounding boxes.
Object Segmentation(目標分割)
- 與object recognition相似,檢測到影象中的所有目標
- 但是畫素級的,需要給出屬於每一類的所有畫素點,而不是矩形框
Object Segmentation: Like object recognition you will recognize all objects in an image but your output should show this object classifying pixels of the image.
- object recognition:(多類目標)矩形框+類別
- object detection:(兩類目標)矩形框+類別
- Object Segmentation:(多類目標)畫素集+類別
Image Segmentation(影象分割)
- 將給定的影象分割為多個區域
- 每個區域為一類,但不需要給出label
Image Segmentation: In image segmentation you will segment regions of the image. your output will not label segments and region of an image that consistent with each other should be in same segment. Extracting super pixels from an image is an example of this task or foreground-background segmentation.
semantic segmentation(語義分割)
- 需要對影象的每一個畫素點進行分類
- 這裡的類別為:多個目標類別和多個非目標類別
Semantic Segmentation: In semantic segmentation you have to label each pixel with a class of objects (Car, Person, Dog, …) and non-objects (Water, Sky, Road, …). I other words in Semantic Segmentation you will label each region of image.
instance segmentation
- 這個還沒懂,待續…..
附一工具
reference:
[1]http://stackoverflow.com/questions/33947823/what-is-semantic-segmentation-compared-to-segmentation-and-scene-labeling
[2]http://computerblindness.blogspot.com/2010/06/object-detection-vs-semantic.html
[3]http://cs.stackexchange.com/questions/51387/what-is-the-difference-between-object-detection-semantic-segmentation-and-local
[4]cs231n.stanford.edu/slides/winter1516_lecture8.pdf