
四、spark叢集架構
spark叢集架構官方文件:http://spark.apache.org/docs/latest/cluster-overview.html
叢集架構
我們先看這張圖
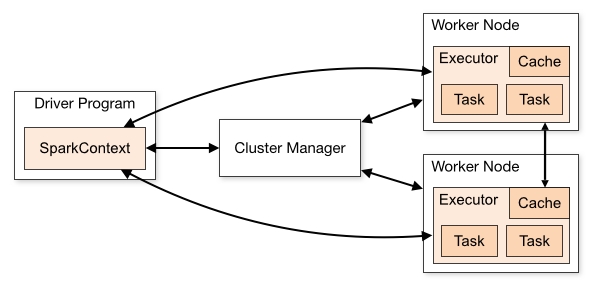
這張圖把spark架構拆分成了兩塊內容:
1)spark應用程式:即左邊的DriverProgram這塊;
2)spark 叢集:即右邊的ClusterManager和另外兩個Worker Node;
這樣的結構,我們大概可以猜測一下spark是怎麼工作的。首先我們會編寫一個spark程式,然後啟動spark叢集,這個spark程式需要和spark叢集互動並讓spark叢集執行計算並最終產生結果。
下面,分別看看什麼是spark程式,什麼是spark叢集
什麼是spark應用程式?
spark應用程式指的就是我們編寫程式程式碼,我們的程式程式碼會包含一個驅動程式Driver,有了這個Driver它會呼叫程式的main方法去啟動我們的程式,並建立一個SparkContext。
當我們的sparkContext建立完成之後,我們的程式就可以通過sparkContext和Spark叢集進行互動了。
如:Driver -> 呼叫main() -> 建立sparkContext -> 與spark叢集互動
什麼是spark叢集?
spark叢集分為三種執行模式:standalone、yarn、mesos
為了排除干擾因素,我們這裡只以standalone來理解spark叢集
我們先看上圖右側部分,spark叢集分為兩部分:Cluster Manager和兩個WorkNode。這個結構就是一個很明顯的master-slaver(主從)的結構,由master來負責資源管理,而slaver來負責執行相應的任務。
sparkContext在與Cluster Manager建立連線以後就會向Cluster Manager申請資源,之後sparkContext把程式程式碼解析成一些task,並把這些task分發給WorkNode讓WorkNode去執行task。直到所有的task執行完畢以後,sparkContext會登出,並釋放資源。
如:sparkContext -> 連線ClusterManager -> 申請資源 -> 解析成多個task -> 分發給workNode -> 執行task -> 執行完畢釋放資源
總結
當前Driver啟動以後,會去執行應用程式的main方法,並構建sparkConext物件。sparkContext與ClusterManager連線互動,並且sparkContext將程式程式碼解析成多個task,將task傳送給workNode,workNode又會把task丟給任務執行器executor去執行,executor會啟動執行緒池開始執行task。當所有的task執行完畢,spark向ClusterManager登出,並釋放資源。
下面是spark叢集架構的一些概念:
| Application | 使用者程式設計的spark程式. 包含一個Driver驅動程式和executor要執行的程式碼 |
| Application jar | 一個包含spark應用程式的jar包 |
| Driver program | 驅動程式,包含在application當中,用於執行main方法和建立sparkContext。注意:Driver可以執行在Client中,也可以執行在master中。例如,當使用spark-shell提交spark job的時候Driver執行在master上,當使用spark-submit提交或者IDEA開發的時候Driver執行在Client上 |
| Cluster manager | spark叢集,可以執行在standalone、yarn、mesos |
| Deploy mode | 部署模式,分為單機部署、偽分散式、完全分散式 |
| Worker node | spark的叢集的從節點,用於執行任務 |
| Executor | 任務的執行器 |
| Task | application的程式碼被解析成許多task,併發送給executor去執行 |
| Job | 當碰到action操作的時候就會催生job,job中包含著多個task平行計算 |
| Stage | task的組 |
| Client | 客戶端程式,用於提交spark job |