
EM演算法_斯坦福CS229_學習筆記
Part VII EM演算法(Expectation-Maximization Algorithm)
翻過學習理論的篇章,這一講關注於非監督演算法。首先由經典的K-means演算法引出EM演算法,最後利用混合高斯模型對於EM演算法進行簡單闡述。
目錄
Part VII EM演算法(Expectation-Maximization Algorithm)
2 EM演算法(Expectation-Maximization Algorithm)
2.1 Jensen不等式(Jensen's Inequality)
1 K-means演算法
非監督學習與之前監督學習的不同在於其輸入的資料並沒有資料標籤。因此非監督學習的演算法常常解決的是聚類問題,而其中比較經典且被熟知的便是K-means演算法。現對K-means演算法做一個介紹。K-means演算法事先假設存在著k個聚類中心(這也是該演算法的缺陷所在),通過迭代到收斂將每個樣本歸到相應的類別。
假設m個輸入資料集合為 ,K-means演算法步驟如下:
(1)在取值空間內,隨機選取k個初始聚類中心,假設為 。
(2)重複以下兩個步驟,直到收斂:
(i) 代表每個樣本歸屬的類別,即對於每個樣本
,固定樣本中心不變,計算

按照歐式距離,尋找該樣本點距離最近的聚類中心,將樣本重新進行歸類。若樣本點 距離第n箇中心最近,那麼
。(對應於EM演算法中的E-step)
(ii)對於每個聚類中心 ,固定樣本的類別不變,計算

調整新的樣本中心的位置,即將屬於該類的所有樣本的均值作為新的聚類中心。(對應於EM演算法中的M-step)
下圖為K-means演算法的流程。觀察下圖便很清晰了。其中(a)為原始資料分佈,(b)為初始選擇的兩個聚類中心(k=2)。(c)-(f)為迭代收斂過程。

流程明白了,那麼怎麼保證上述流程收斂呢?
可以這麼理解。我們先定義如下失真函式(distortion function,為什麼這樣叫,我也不清楚)

觀察失真函式可發現,我們在迭代過程的兩步實際就是對於該函式利用座標下降法(還記得在SVM中裡使用的座標上升法嗎?)求最小值的過程。迭代過程中的第一步便是固定 不變,以x為引數進行求解使J最小;而第二步是固定 x 不變,以
為引數求解使J最小。既然每一步都在使J最小,那麼迭代過程顯然是收斂的。
實際應用K-means時會發現,其結果容易受初始聚類中心的影響,因為注意到失真函式J(c,)是一個非凸函式,也就是說會存在著一些區域性最小值,使迭代很容易陷入區域性最小值而不能得到全域性最小值。常常通過選取多次不同的初始聚類中心進行多次試驗來解決該問題。
2 EM演算法(Expectation-Maximization Algorithm)
K-means演算法與EM演算法思想如出一轍,或者說是K-means演算法是EM演算法一種形式。K-means演算法用來解決聚類問題,那麼EM演算法的提出是為了解決什麼呢?個人理解,EM演算法更像是一個工具性的演算法,其目的在於提供了一種求解最大似然方程的思路。當遇到似然方程很難求解時,可利用EM演算法的思路進行求解,EM演算法的核心思想在於引入一個隱變數作為條件,在此條件下將似然方程的引數求解拆分為E-step與M-step,通過不斷迭代直到收斂,從而得到相應的引數。
2.1 Jensen不等式(Jensen's Inequality)
EM演算法的推導需要利用Jensen不等式。
首先回顧一下凸函式的定義。設 的取值域為實數。若
,都有
(若x為向量,即相應的Hessian矩陣H半正定,即
),那麼稱
為凸函式。嚴格一點,若
(
),那麼此時稱
為嚴格凸函式。在此基礎之上,引出Jensen不等式。
若為凸函式,且有隨機變數X,那麼以下不等式稱為Jensen不等式。
![]()
更進一步,不等式取等號的條件為: 為嚴格凸函式;且
(即隨機變數為常數)。
結合圖來看看,就會明白該不等式了。假設 為凸函式,繪製以下圖。

其中 為橫軸中點。
為縱軸中點。是不是就會覺得
就很直觀了。
注意,在Jensen不等式中,若 為凹函式,那麼原不等式方向相反,且不等式取等號條件相應更改。這在接下來推導EM演算法中將會使用。
2.2 EM演算法思想
EM演算法為難以求解的似然方程提供了一個求解思路。以下為了推導方便,針對離散型隨機變數而言,連續型隨機變數將求和變為積分即可。
假設有輸入資料集,原始方法對於x進行建模,引數為
,得到
,由此寫出似然方程

此時如果發現很難通過常規的求偏導的方式解此方程,為了解決此問題,EM演算法提供了另一種求解思路。即假設在模型中還存在著一個潛在的隨機變數z(我的理解是這相當於引入了一個條件進行限制),那麼此時不再對於x建模,而對於(x,z)建模,則可將方程改寫為

這種思想在接下來的因子分析中也會遇到。加入了一個潛在的隨機變數其實有點像加入了一個限制條件,因為通常來說,一個方程給的條件越多,那麼相對而言求解也會更輕鬆。並且還有一個好處在於,如果我們對於這個潛在的隨機變數z“已知”的話(EM演算法採用不斷迭代的方式去逼近,從而達到了z已知的效果),那麼求解該方程也會更為簡單。
在此基礎上,假設對於每個樣本i, 為z所服從的分佈(
),那麼可將似然方程進行如下推導:
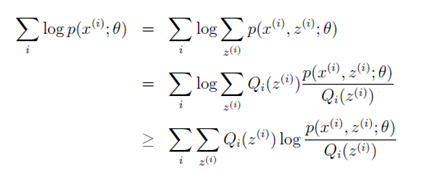
第一行為前文的結論。
第二行在第一行的基礎之上,同時乘以一個,除以一個
。經過這麼變換後,可發現其實
回頭再結合Jensen不等式,對比之下得
,且
此時由於,因為 ,即
為嚴格凹函式,根據凹函式情況下的Jensen不等式
,那麼就可由第二行推出第三行(確保明白這裡)。
明白我們的目的是使似然方程最大化,那麼什麼時候會最大呢?顯然,兩邊取等號時,得到最大值。結合Jensen不等式的取等號條件:為嚴格凹函式,且X為常數時,不等式兩端取等號。那麼可設X為常數c,得下式:

那麼,結合定義
,
得 ,從而
。
將c帶入原式可得,即
。由此可得下列推導。

原來固定引數不變的情況下,要使似然性最大,即
最大,隱變數z的分佈選取後驗分佈即可。那麼後驗分佈
由此,給出EM演算法的迭代步驟:
(1)初始化引數 。
(2)重複以下步驟直到收斂。
(i)E-step:對於每一個樣本i,更新後驗分佈。
![]()
(ii) M-step:在z分佈已知的情況下,最大似然法求解引數並進行更新。

E-step:固定當前引數不變,以後驗分佈
作為z的分佈進行統計計算。這一步驟也被理解為給當前的似然函式
設定了一個下界。
M-step:由Jensen不等式推導而來,相當於z的分佈已知,固定當前z分佈不變,利用最大似然法計算得到引數。這相當於在上一步的
下界的基礎上,利用最大似然法尋找該下界的最大值。
不明白沒關係,又到了看圖說話的時候了。結合下圖進行分析。如圖中大圓弧所示。假設當前迭代的次數為t,輸入引數為
。那麼E-step便是根據此時引數
,得到一個隱變數z後驗分佈,如圖中左下的藍色圓弧所示,這便相當於確定了一個下界;M-step便是在此z後驗分佈基礎上,通過最大似然法尋找引數
,最大值即圖中的紅色小三角形處,此時的最大值即為
,這便是使下界最大。之後進行判斷,若收斂結束迭代;不收斂將
傳入下次迭代(t+1)。

要判斷EM演算法收斂的思路也很清晰,即判斷在任意t和t+1時刻,是否都滿足。仔細縷清迭代的過程,不難得到以下不等式(來源於博主Njiahe),確保你明白,不明白的話再去縷縷迭代過程:
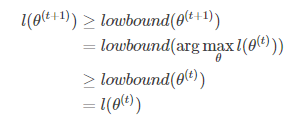
因此可以判斷EM演算法是收斂的。 同樣,也可以換個角度進行理解。可進行如下定義:

EM演算法可看作是對於函式 利用座標上升求極值的過程。E-step固定引數
,使Q最大;而M-step固定Q,使
最大。如此進行迭代,計算過程當然是收斂的。
可能仍然會感到抽象,接下來利用EM演算法,結合高斯混合模型進行推導,加深理解。
2.3 EM演算法在混合高斯模型(GMM)中應用
混合高斯模型(Mixtures of Gaussians Model,GMM)是常用的建模模型。現在將EM演算法應用其中。
同樣假設有一組訓練資料,假設存在著隱變數z,此時我們建模的目標為聯合概率分佈
。
聯合概率分佈可以寫成。由此我們進行GMM的建模。
對於每個樣本i,有,設z服從多項分佈,且取值範圍為1到k。
即
並且當給定z時,即 時,有
。
即假設隱變數z的取值有k個,當每選定一個z=j(j=1,2,k)後,x便可確定為一個引數為 的高斯分佈。這種模型我們稱為高斯混合模型。注意此時的混合高斯模型與之前在生成學習演算法中的高斯判別分析(GDA)建模的模型存在著兩個不同:
(1)GDA中z服從於伯努利分佈,而此時z服從於多項分佈。這相當於一個擴充套件。
(2)GDA中兩個高斯分佈的協方差陣假設一樣,而這裡每個高斯分佈的均值和協方差陣都不一樣。
接下來應用EM演算法進行引數求解。
在該模型中,引數為 。首先初始化各個引數的值。然後寫出最大似然方程:

在E-step中,計算後驗概率,即z屬於每一類的概率。
![]()
將E-step中得到的結果帶入M-step,進行最大似然方程求解,得到以下引數:

結果看上去也並不意外,在意料之中。這便是EM演算法實際的應用了。
同理,可以回頭再看一下K-means演算法。其實迭代中的兩個步驟就是EM演算法的E-step與M-step。只不過在K-means中,潛在變數z服從的是狄拉克分佈(Dirac Delta,即為高斯分佈的極限),即每個樣本只可能屬於一種類別且屬於其他類別的概率為0。因此K-means也被稱為hard EM(是不是和softmax、hardmax近似)。
3 小結
EM演算法作為一種求解最大似然方程的思路,在於增加了一個隱變數作為條件,通過迭代的方式使難以求解的最大似然方程得到求解。但是EM演算法的一個缺陷在於,其較大程度上受初值的影響,而且會因此陷入區域性最小值無法得到全域性最小值。因此,在應用EM演算法時,應多選取不同的初始條件進行初始化,綜合考慮迭代的結果,從而得到最終的結論。