
Tensorflow的視覺化工具Tensorboard的使用——圖(graph)的使用
圖(graph)對於理解tensorflow程式的結構十分重要,是tensorboard的重要組成部分,今天主要記錄自己在學習圖的使用過程中的一些心得。
一、認識圖中的基本元素
要使用圖,我們首先要理解圖中的一些基本的元素。
1)名稱空間
這個叫tf.name_scope,是tensorflow中層次較高的節點(node)。
2)操作符節點
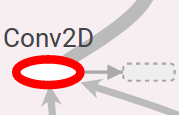
這個叫OpNode,他代表一個操作,或者說是運算,函式,輸入的張量是這個函式的自變數,通過函式運算後輸出。
3)常量

這個叫constant,他代表一個常量,也就是一個常數。
4)資料流邊
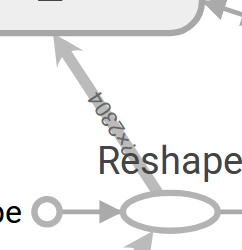
這裡面的帶箭頭的線叫dataflow edge,是資料流邊,表示張量資料流向箭頭所指的節點,線段的寬度代表了張量的維度,維度越多越寬。
如果線段變成了虛線,就變成了控制依賴邊,表示箭頭尾部對箭頭頭部的控制、依賴關係。
5)參考邊
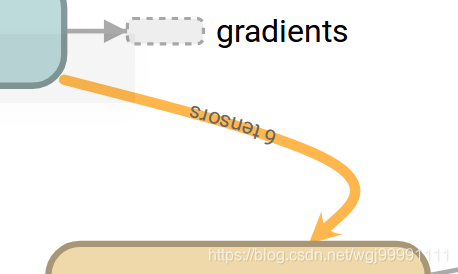
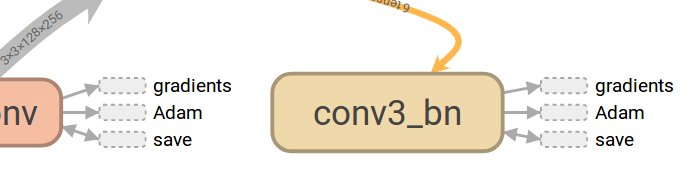
這個黃色的邊叫Reference edge ,表示箭頭所指的節點可以調整、優化輸入過來的張量。(這裡理解不是很清楚?每個節點不都是有這樣的能力嗎?mutate用在這裡到底是什麼含義?)
以上就是常用到的一些基本的圖形,當然還有其他的一些,用到的時候可以自己查。
- 二、如何構建圖
首先要明確,圖中所顯示的一切都是我們構建出來的。構建圖的過程,就是在程式中加入name_scope,以及給函式命名的過程。你的name_scope加的好,你的圖就看起來層次清晰,反之,圖就不好看。
經驗:
第一步,構建層類,把卷積層、池化層、全連線層等都變成類,這些層類可以通過讀取配置檔案來初始化。 這樣就可以通過寫配置檔案的方式來初始化多個層。
第二步,在讀取配置檔案初始化時,給每一個層命名,然後把該層配置過程中的重要操作放在一個name_scope下,把該層執行過程中的主體操作放在一個name_scope下。
這樣,形成的圖層次結構就比較清晰。
1)name_scope
在某個函式中加上name_scope,則在圖中就會是一個NameSpace節點
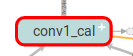
def get_output(self, inputs, is_training=True): with tf.name_scope('%s_cal' % (self.name)) as scope: self.hidden = self.conv(inputs=inputs) if self.batch_normal: self.hidden = self.bn(self.hidden, training=is_training) return self.output
這段程式碼給get_output函式的主要程式碼加上了name_scope,則在圖中就會顯示如下一個節點。
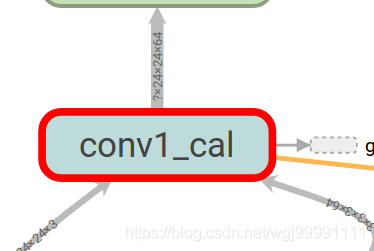
2)命名函式
命名函式,圖中就會顯示函式的節點。
self.bn = tf.layers.BatchNormalization(
axis=-1,
momentum=0.9,
epsilon=1e-5,
center=True,
scale=True,
beta_initializer=tf.constant_initializer(beta_init_value),
gamma_initializer=tf.constant_initializer(gamma_init_value),
moving_mean_initializer=tf.constant_initializer(moving_mean_init_value),
moving_variance_initializer=tf.constant_initializer(moving_variance_init_value),
trainable=True,
name='%s_bn' % (self.name))
這段程式碼對函式tf.layers.BatchNormalization進行了命名
name=’%s_bn’ % (self.name)),則在圖中就會顯示如下一個節點:
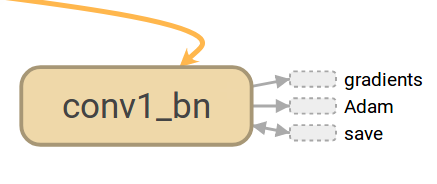
- 三、如何看圖
下面我們就事論事,具體對一個比較好的圖進行分析,看看能看到什麼東西。
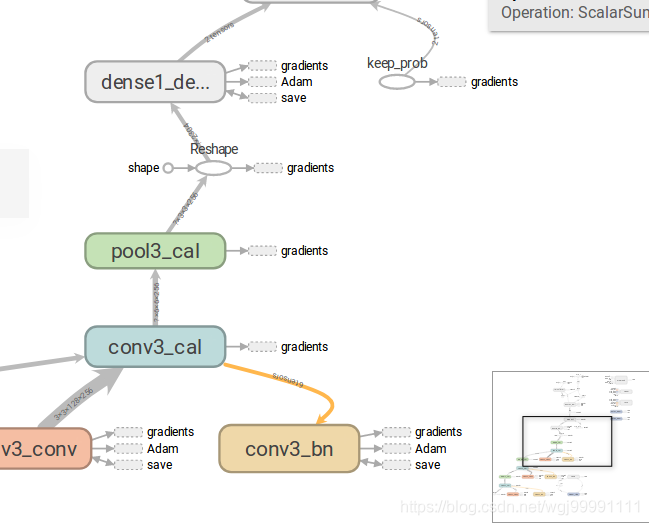
1) 一副圖從整體上來看是這樣的,分為兩個區,左邊是主圖區,右邊是從屬區。
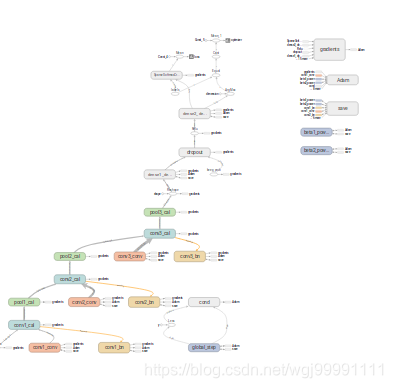
2)從圖中可以看出,張量(資料)是從下向上流動的。並且這個圖是分層的,我們能看到每一層的主要操作。

3)在圖的最上方,張量(資料)會分到兩個方向,一邊是損失函式,另一邊是預測精度。
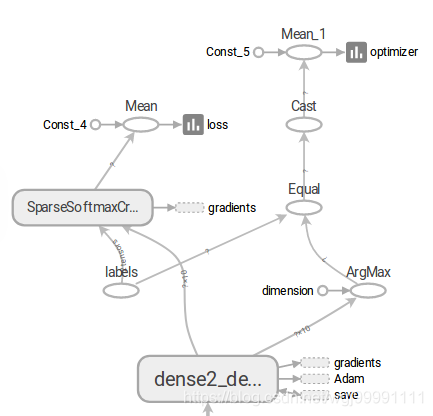
4)損失函式的值我們希望其越來越低,預測精度我們希望其越來越高,這裡面還有個一反向傳播的問題,雖然我們在程式中沒有設計到反向傳播的圖形標註程式碼,但這個系統是自己生成的,反向傳播的過程是通過資料輸入gradients節點來實現的。我們可以看到有很多節點都向gradients節點輸出資料了,這裡描述的就是一個反向傳播優化權重值的過程。
而Adam則表示模型的尋優演算法的變化過程。
5)資訊採集點

這個圖左邊是一個節點,一個數據流邊,然後一個Summary節點,表示我們會採集這個節點計算過後的資料,並會把資料顯示在tensorboard中。看到這個東西,就表示這時我們的一個數據採集點。
也可以說,如果你認為那個節點的資料需要採集,作為我們調優的依據,就把他記下來,然後在程式中加程式碼,把這個節點資料採集下來。
6)高頻節點和從屬區
圖中這些用虛線框起來的節點稱之為高頻節點(high-degree)(這個中文是自己翻譯的,可能不準確),由於這些節點與圖中的其他很多節點都有連線關係,如果都表示出來就會顯得圖很亂,所以就把這些節點顯示在圖右上角的從屬區,而在主圖中採取這種方式表示其他節點與高頻節點之間的關係。從屬區如下圖所示:

右側的這個就是從屬區。