
利用模擬退火提高Kmeans的聚類精度
http://www.cnblogs.com/LBSer/p/4605904.html
Kmeans演算法是一種非監督聚類演算法,由於原理簡單而在業界被廣泛使用,一般在實踐中遇到聚類問題往往會優先使用Kmeans嘗試一把看看結果。本人在工作中對Kmeans有過多次實踐,進行過使用者行為聚類(MapReduce版本)、影象聚類(MPI版本)等。然而在實踐中發現初始點選擇與聚類結果密切相關,如果初始點選取不當,聚類結果將很差。為解決這一問題,本博文嘗試將模擬退火這一啟發式演算法與Kmeans聚類相結合,實踐表明這種方法具有較好效果,已經在實際工作中推廣使用。
1 Kmeans演算法原理
K-MEANS演算法:輸入:聚類個數k,以及包含 n個數據物件的資料。輸出:滿足方差最小標準的k個聚類。 處理流程: (1) 從 n個數據物件選擇 k 個物件作為初始聚類中心; (2) 迴圈(3)到(4)直到每個聚類不再發生變化為止 (3) 根據每個聚類物件的均值(中心物件),計算每個物件與這些中心物件的距離;並根據最小距離重新對相應物件進行劃分; (4) 重新計算每個(有變化)聚類的均值(中心物件)
1.1 Step 1

1.2 Step 2
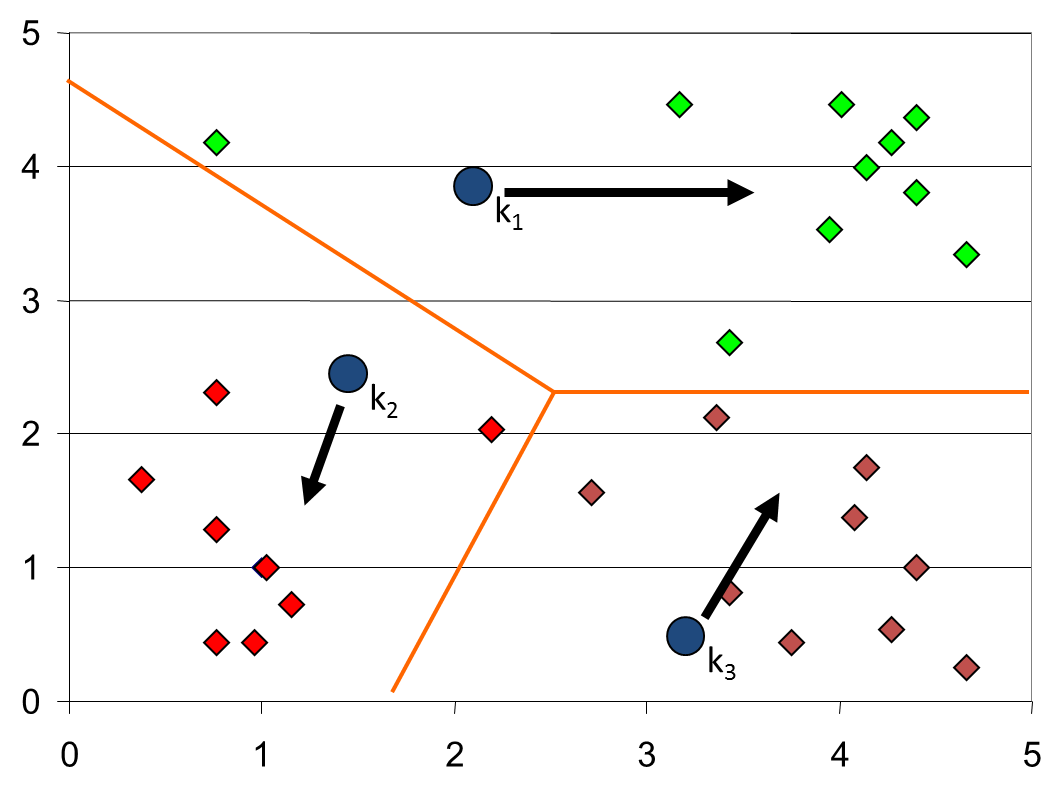
1.3 Step 3

1.4 Step 4
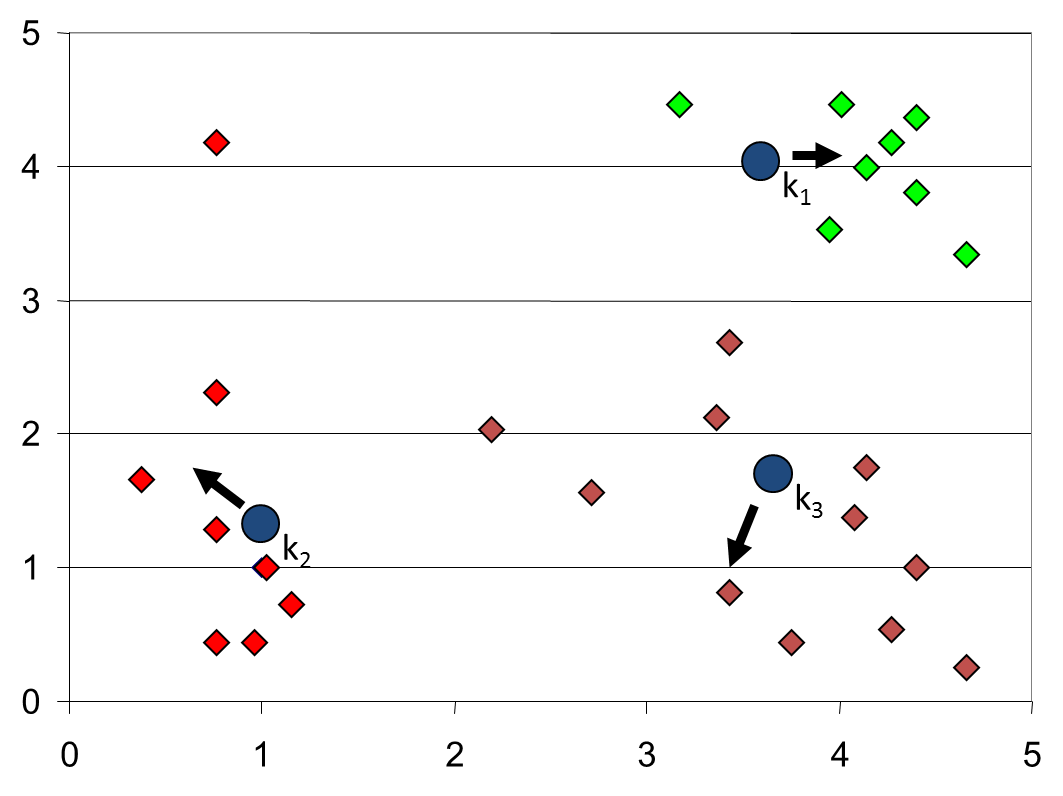
1.5 Step 5

2 初始點與聚類結果的關係
K means的結果與初始點的選擇密切相關,往往陷於區域性最優。

2.1 例子
下面以一個實際例子來講初始點的選擇對聚類結果的影響。首先3箇中心點(分別是紅綠藍三點)被隨機初始化,所有的資料點都還沒有進行聚類,預設全部都標記為紅色,如下圖所示:

迭代最終結果如下:

如果初始點為如下:
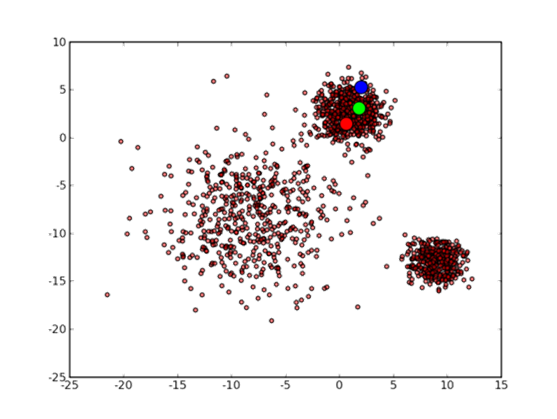
最終會收斂到這樣的結果:
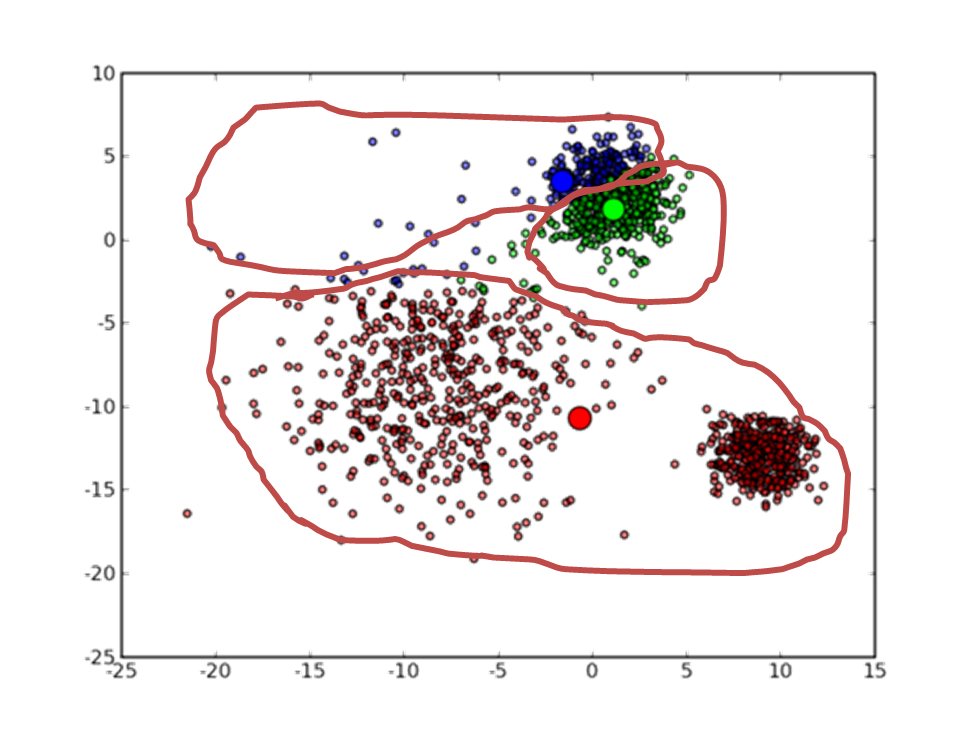
3 解決方法
那怎麼解決呢?一般在實際使用中,我們會隨機初始化多批初始中心點,然後對不同批次的初始中心點進行聚類,執行完後選擇一個相對較優的結果。這種方法不僅不夠自動,而且有較大概率得不到較優的結果。目前,研究較多的是將模擬退火、遺傳演算法等啟發式演算法與Kmeans聚類相結合,這樣能大大降低陷於區域性最優的困境。下圖就是模擬退火的演算法流程圖。

4 實戰
“紙上得來終覺淺,絕知此事要躬行”,僅知道原理而不去實踐永遠不能深刻掌握某一知識。本人實現了基於模擬退火的Kmeans演算法以及普通的Kmeans演算法,以便進行比較分析。
4.1 實驗步驟
1)首先我們隨機生成二維資料點以便用於聚類。

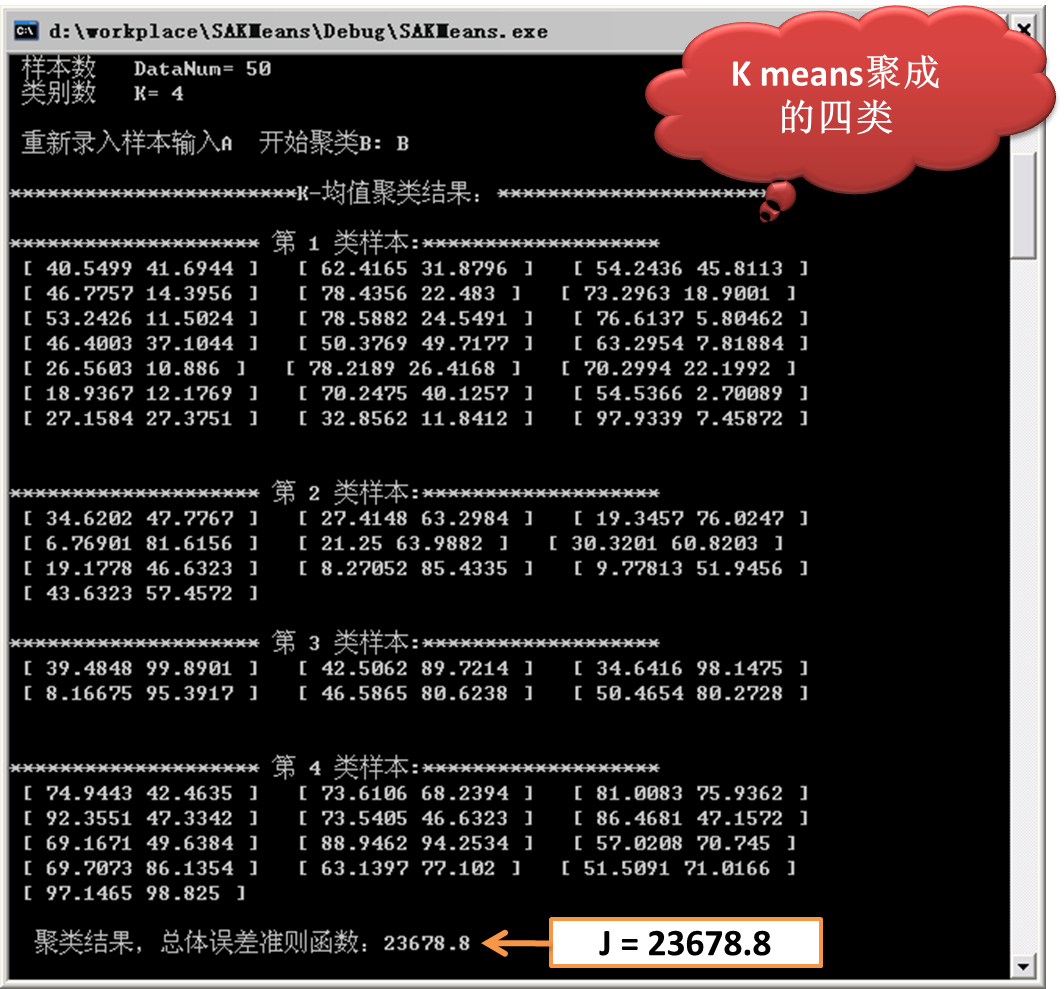
2)基於原生的Kmeans得到的結果。
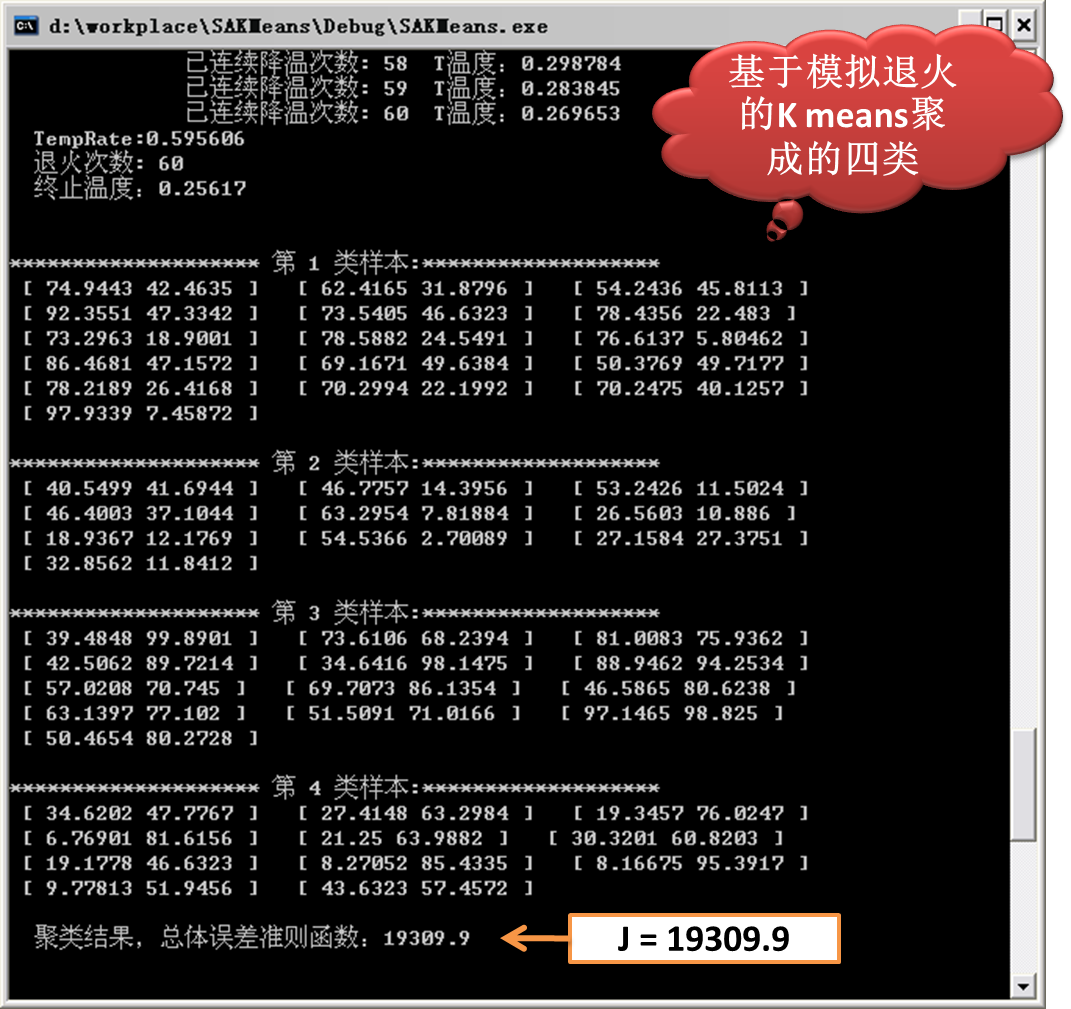
3)基於模擬退火的Kmeans得到的結果
4.2 結論
由上圖的實驗結果可以看出,基於模擬退火的Kmeans所得的總體誤差準則結果為:19309.9。
而普通的Kmeans所得的總體誤差準則結果為:23678.8。
可以看出基於模擬退火的Kmeans所得的結果較好,當然,此演算法的複雜度較高,收斂所需的時間較長,尤其是在大資料環境下。
轉載請標明源地址:http://www.cnblogs.com/LBSer