
模型求解
監督學習的優化目標
這部分摘自:機器學習中的範數規則化之(一)L0、L1與L2範數
一般來說,監督學習可以看做最小化下面的目標函式:
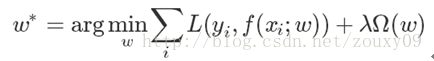
其中,第一項L(yi,f(xi;w)) 衡量我們的模型(分類或者回歸)對第i個樣本的預測值f(xi;w)和真實的標籤yi之前的誤差。因為我們的模型是要擬合我們的訓練樣本的嘛,所以我們要求這一項最小,也就是要求我們的模型儘量的擬合我們的訓練資料。但正如上面說言,我們不僅要保證訓練誤差最小,我們更希望我們的模型測試誤差小,所以我們需要加上第二項,也就是對引數w的規則化函式Ω(w)去約束我們的模型儘量的簡單。
機器學習的大部分帶參模型都和這個不但形似,而且神似。是的,其實大部分無非就是變換這兩項而已。對於第一項Loss函式,如果是Square loss,那就是最小二乘了;如果是Hinge Loss,那就是著名的SVM了;如果是exp-Loss,那就是牛逼的 Boosting了;如果是log-Loss,那就是Logistic Regression了;還有等等。不同的loss函式,具有不同的擬合特性,這個也得就具體問題具體分析的。 規則化函式Ω(w)也有很多種選擇,一般是模型複雜度的單調遞增函式,模型越複雜,規則化值就越大。比如,規則化項可以是模型引數向量的範數。然而,不同的選擇對引數w的約束不同,取得的效果也不同,但我們在論文中常見的都聚集在:零範數、一範數、二範數、跡範數、Frobenius範數和核範數等等。
線性迴歸中,經典的方法是OLS(普通最小二乘),為了防止過擬合又有Ridge迴歸和LASSO迴歸,高維資料還有PLS、OPLS等。
概率模型中,有LSE(最小二乘估計),此外還有所謂的MLE(最大似然估計)。
OLS對應的是SE(平方誤差,均方誤差MSE乘以N)。
此處對這些方法進行總結。(未完待續……)