
使用梯度下降演算法來求解線性迴歸模型
阿新 • • 發佈:2019-01-10
廢話
求解線性迴歸模型的解析解可以直接使用公式,這節可以使用梯度下降演算法來求解這類問題的優化問題:
原理的東西不想說了 ,總之機器學習的一般思路都是:
構建模型(也就是你想建立什麼樣的預測函式 y=blabla)
—-》
接著就是你想對你要建立的模型使用什麼樣的損失函式求解最優化問題(此處使用的是最小二乘的原理也就是預測值和真實值的差平方和 ,最後除以樣本數cost=blabla)
—-》
最後一步就是求解最優化問題(引數更新的方式)
程式碼
# 好了這是最後一遍!!
import numpy as np
import random
#首先要生成一系列資料,三個引數分別是要生成資料的樣本數,資料的偏差,以及資料的方差 結果
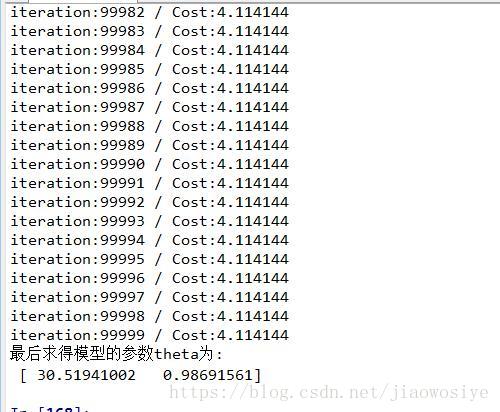
結束語
好久沒寫程式碼了,明顯不如以前了,雖然以前也是個弱寶寶~ ~
堅持
今天就先到這,我要回宿舍啦~~~