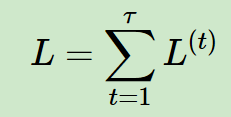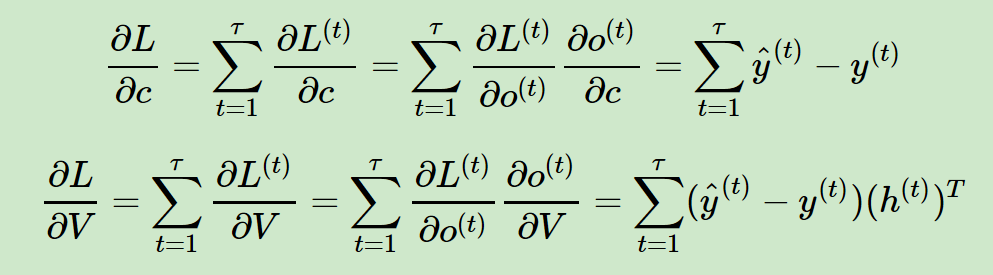序列模型(2)-----迴圈神經網路RNN
阿新 • • 發佈:2018-12-04
一、RNN的作用:
RNN可解決的問題:
訓練樣本輸入是連續的序列,且序列的長短不一,比如基於時間的序列:一段段連續的語音,一段段連續的手寫文字。這些序列比較長,且長度不一,比較難直接的拆分成一個個獨立的樣本來通過DNN/CNN進行訓練。
二、RNN模型:
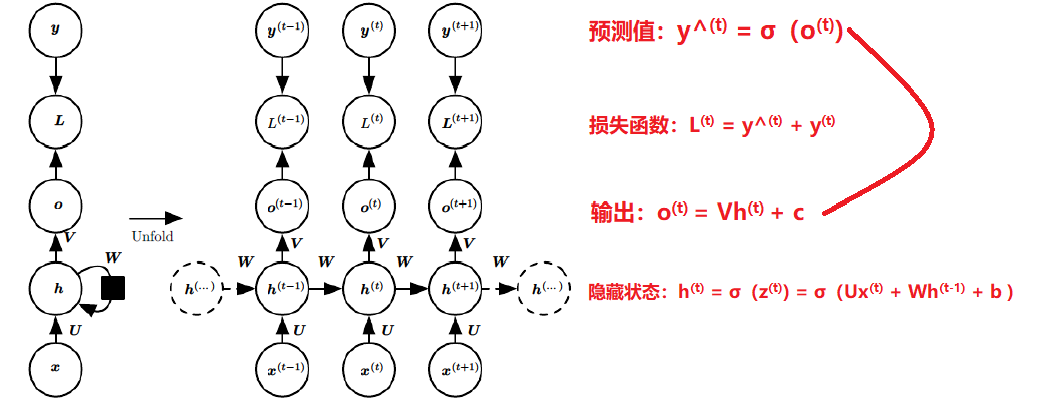
上圖中左邊是RNN模型沒有按時間展開的圖,如果按時間序列展開,則是上圖中的右邊部分。我們重點觀察右邊部分的圖。
這幅圖描述了在序列索引號t附近RNN的模型。其中:
1)x(t)代表在序列索引號 t 時訓練樣本的輸入。同樣的,x(t−1)和
2)h(t) 代表在序列索引號 t 時模型的隱藏狀態。h(t) 由x(t)和h(t−1) 共同決定。
3)o(t) 代表在序列索引號 t 時模型的輸出。o(t) 只由模型當前的隱藏狀態h(t)決定。
4)L(t) 代表在序列索引號 t 時模型的損失函式。
5)y(t) 代表在序列索引號 t 時訓練樣本序列的真實輸出。
6)