
《機器學習基石》第一週 —— When Can Machine Learn?
(注:由於之前進行了吳恩達機器學習課程的學習,其中有部分內容與機器學習基石的內容重疊,所以以下該系列的筆記只記錄新的知識)
《機器學習基石》課程圍繞著下面這四個問題而展開:

主要內容:
一、什麼時候適合用機器學習?
二、該課程所採用的一套符號表示
三、機器學習的流程
四、感知機演算法
五、學習的型別
六、機器學習的無效性
七、機器學習的可行性(在無效性的前提下加一些條件限制)
一、什麼時候適合用機器學習?

對於第一點:我們學習的物件必須要存在某些顯式的或者潛在的規律,否則,如果學習物件都毫無規律,那麼學習到的所謂的知識(經驗)也就站不住腳了。
對於第二點:這些問題難以使用某些演算法或者公式明確地算出結果,假如可以,那麼我們就只需要學習數學和演算法就足以解決問題,又何須機器學習呢?所以機器學習就是可以用來解決這些有規律但規律又相對模糊的問題。
對於第三點:只有依靠以往大量的經歷所得到的經驗,才是可靠的。
二、該課程所採用的一套符號表示


三、機器學習的流程
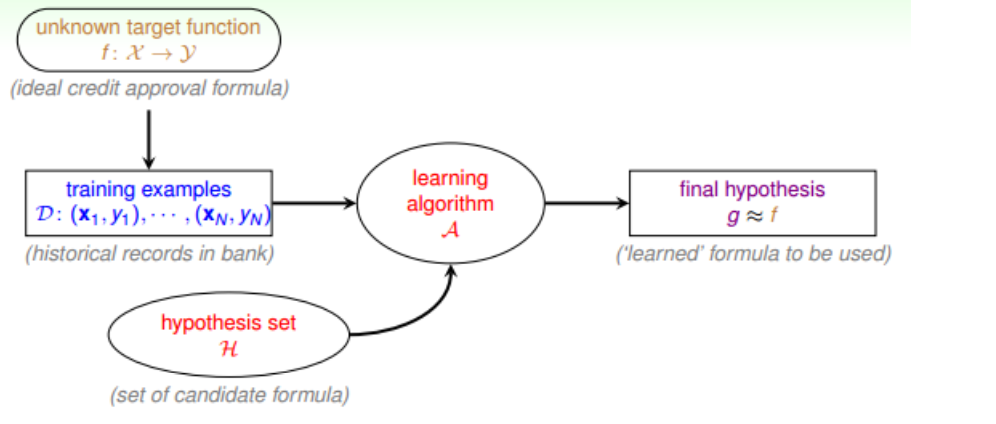
四、感知機演算法
五、學習的型別
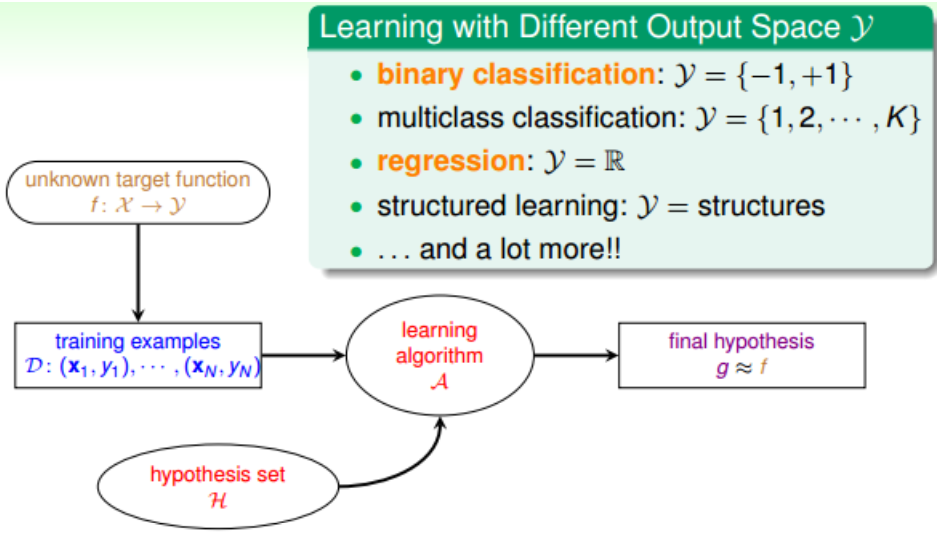
1.根據輸出y的取值型別而區別,有分類、迴歸、結構化學習:
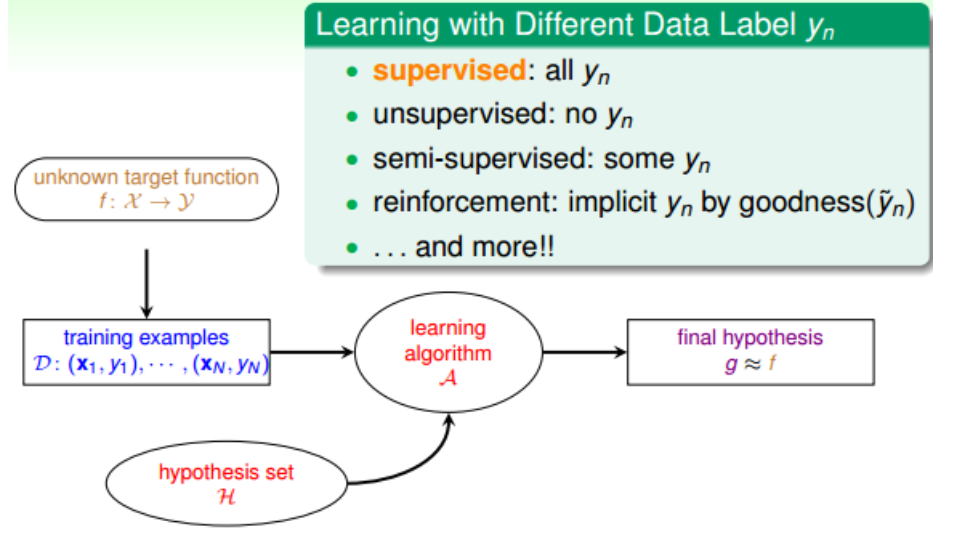
2.根據(樣本)輸出y的有無或者有多少而區別,有監督式學習、無監督式學習、半監督式學習、增強式學習:
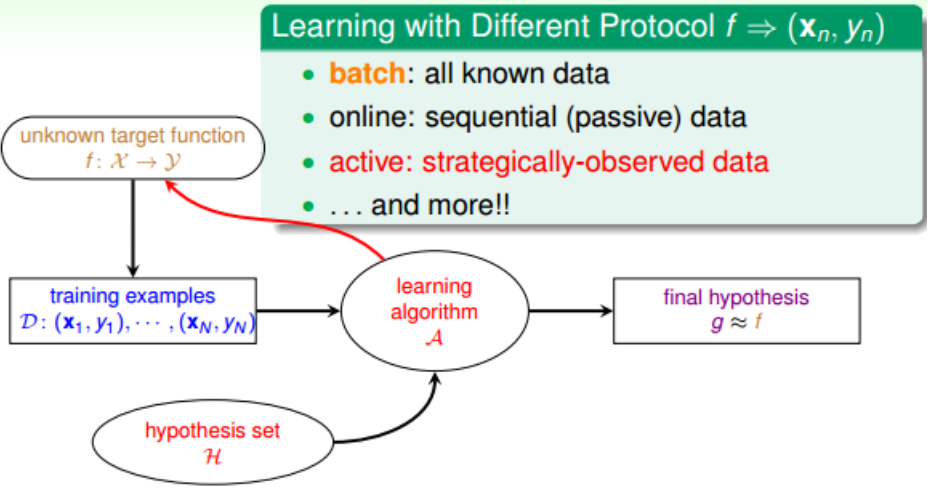
3.根據學習的協議而區別,有:batch leanring、online leanring、active learning:

4.根據輸入x的型別而區別,有:concrete features、raw features、abstract feature。
concrete features:有具體的、形象化的含義,例如身高、點選次數等這些特徵。
raw features:原始的、未經過處理的特徵,例如圖片的畫素等。
abstract feature:沒有現實含義的,如資料編號或者使用者ID。
5.總結:

六、機器學習的無效性
所謂機器學習的無效性,按照個人的理解,就是:單憑從給出的資料集中學習到的規律無法應用於資料集之外的資料,或者說是:每個人都學習到了不同的規律,且這些規律對於資料集都是成立的,但是對於資料集之外的資料就不成立了,這就是機器學習的不可行性。但是,假如增加一些條件限制,機器學習就可行了。其中一個很重要的條件限制就是:樣本大小,也就是資料集的大小N足夠大。下節詳情。
七、機器學習的可行性
證明機器學習可行性的式子就是Hoeffding's inequality:

其中u是實際上類別0的比例(假設是二分類),v是資料集(樣本)類別0的比例。當N足夠大時,v就近似等於u,這就說明了從樣本集中學到的規律,就近似是真實的規律,這樣就能將學習到的規律應用到資料集之外的資料了。