
Coursera機器學習-第七週-Support Vector Machine
Large Margin Classification
支援向量機(Support vector machine)通常用在機器學習 (Machine learning)。是一種監督式學習 (Supervised Learning)的方法,主要用在統計分類 (Classification)問題和迴歸分析 (Regression)問題上。
支援向量機屬於一般化線性分類器,也可以被認為是提克洛夫規範化(Tikhonov Regularization)方法的一個特例。這族分類器的特點是他們能夠同時最小化經驗誤差與最大化幾何邊緣區,因此支援向量機也被稱為最大邊緣區分類器。現在多簡稱為SVM。
先來回顧邏輯迴歸函式:
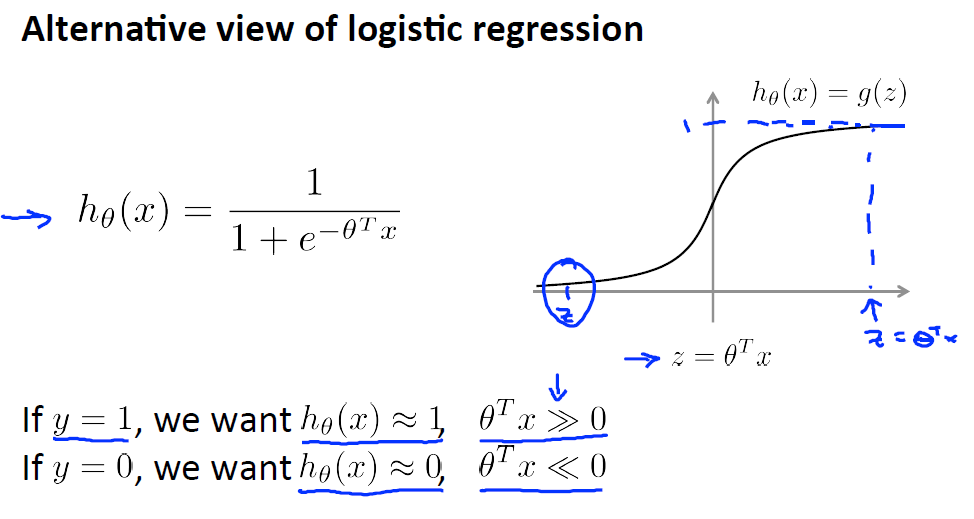
由圖上可知:
Logistic Regression Cost Function:
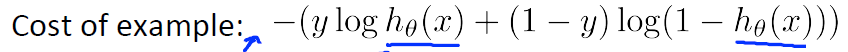
ps:這是對於一個樣本點的cost Function,所以沒有除以m
左圖:紅色線描述的是新的代價函式的,記為
右圖:紅色線描述的是新的代價函式的,記為
這裡的下標是指在代價函式中對應的 y=1 和 y=0 的情況

構建SVM的代價函式
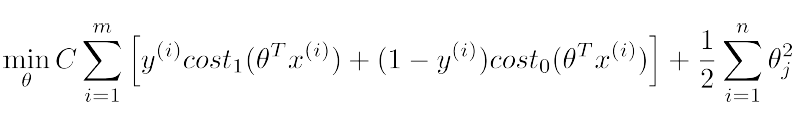
這個代價函式是由logistic regression變化過來的,只需將
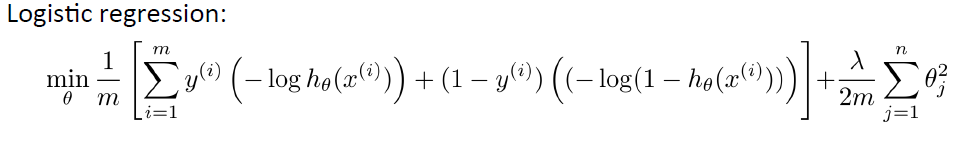
同時乘以m,除以
記
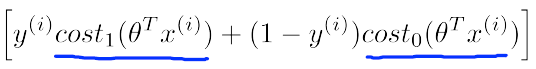 為
為 當C取非常大的值時,例如10000,就要求
當y=1時,
當y=1時,

Large margin classifier:
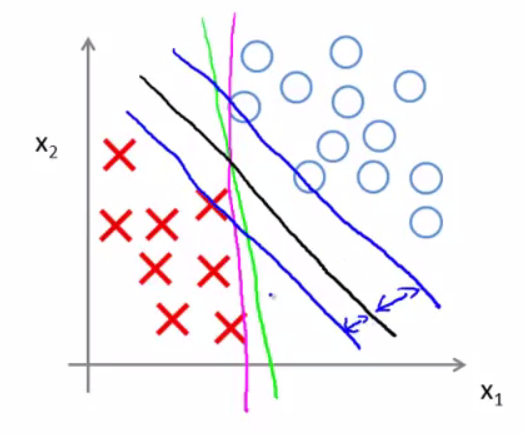
關於Decision Boundary 我們或許可以得到粉色的線、綠色的線、黑色的線。但是,其中,哪種的分類是更合理,更好的呢?
支援向量機將會選擇 這個黑色的決策邊界 。這條黑色的看起是更穩健的決策界 ,在分離正樣本和負樣本上它顯得的更好 。數學上來講 ,這條黑線有更大的距離 ,這個距離叫做間距 (margin) 當畫出這兩條 ,額外的藍線我們看到黑色的決策界和訓練樣本之間有更大的最短距離, 然而粉線和藍線離訓練樣本就非常近 。
這個距離叫做支援向量機的間距。 而這是支援向量機具有魯棒性的原因, 因為它努力用一個最大間距來分離樣本 。
引數C對分類的影響:
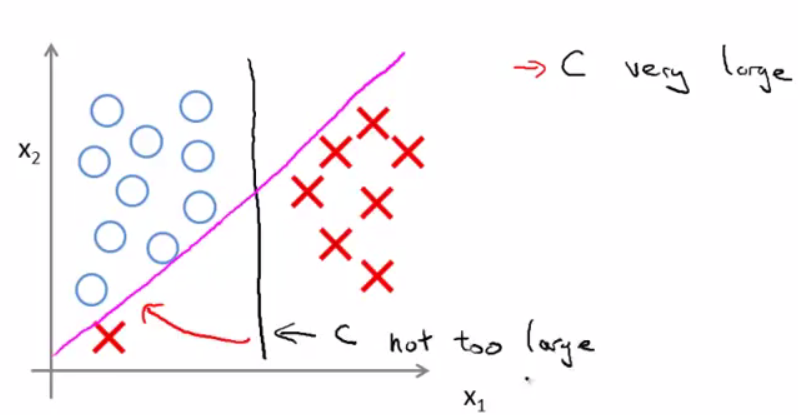
其實C是一個懲罰係數,是對於離群點(outlier)的懲罰程度。當C比較小時,對於離群點可以忽略,當C比較大的時候,就不能忽略離群點了,必須將離群點劃分到相應的類別。
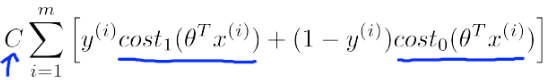
這節的內容請參見參考文章
Kernels
核函式的本質:
- 實際中,我們會經常遇到線性不可分的樣例,此時,我們的常用做法是把樣例特徵對映到高維空間中去
- 如果凡是遇到線性不可分的樣例,一律對映到高維空間,那麼這個維度大小是會高到可怕的。該怎麼辦?
- 此時,核函式就隆重登場了,核函式的價值在於它雖然也是講特徵進行從低維到高維的轉換,但核函式絕就絕在它事先在低維上進行計算,而將實質上的分類效果表現在了高維上,也就如上文所說的避免了直接在高維空間中的複雜計算。
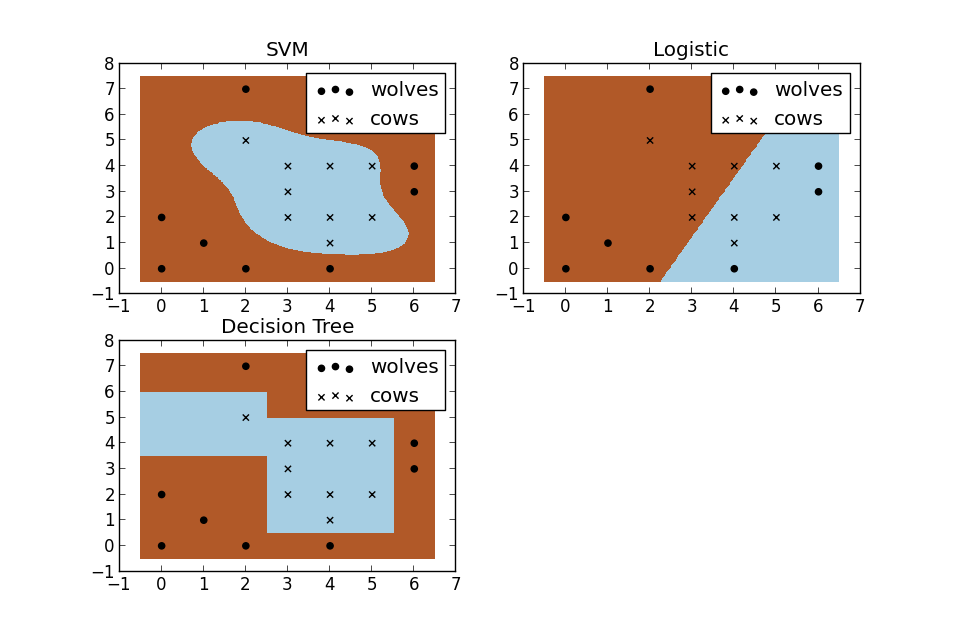
假設現在你是一個農場主,圈養了一批羊群,但為預防狼群襲擊羊群,你需要搭建一個籬笆來把羊群圍起來。但是籬笆應該建在哪裡呢?你很可能需要依據牛群和狼群的位置建立一個“分類器”,比較下圖這幾種不同的分類器,我們可以看到SVM完成了一個很完美的解決方案。
對於非線性的決策邊界,我們之前可以用多項式擬合的方式進行預測,例如圖上的

Kernel:

1.標記點(landmark,
2.通過Kernel函式計算相似度
3.代入Hypothesis進行預測
標記點(landmark,
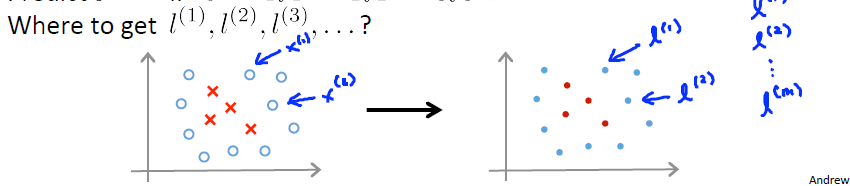
左邊的圖是Training set(訓練集),其中分為Positive和negative樣本點。將其按照樣本序號標記為
Kernel Function:
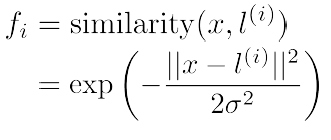
Kerenl 的
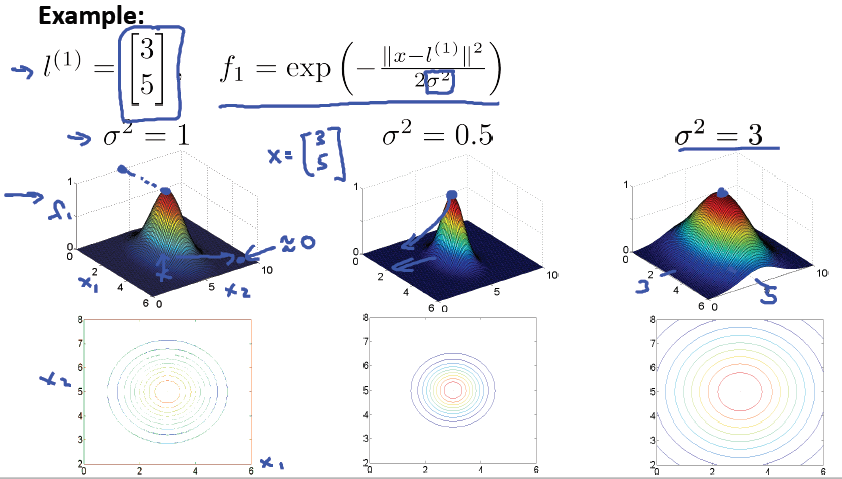
Kernels計算相似度:
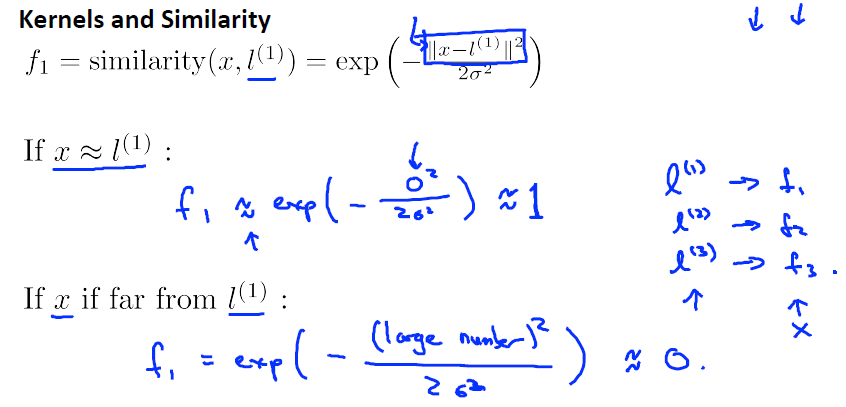
當
當
預測分類例子:

假設已經知道
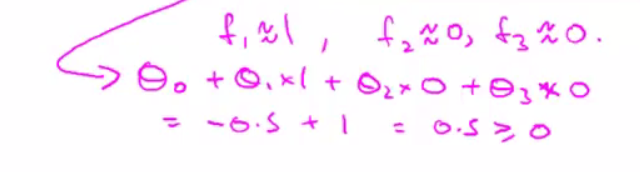
可以預測該樣本點屬於”1”(positive)
相似的,對於天藍色的樣本點
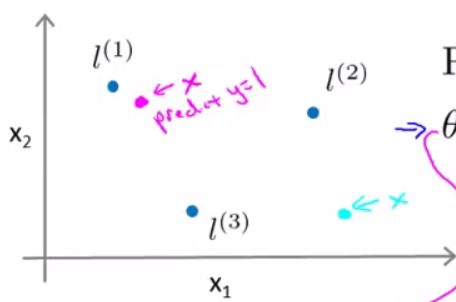
可以預測該樣本點屬於”0”(negative)
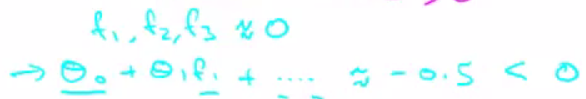
Summary:

PS:那麼在這m個訓練資料中,每一個訓練資料
於是,每個特徵向量
如下圖所示,這裡與之前講過的cost function的區別在於用kernel
Large Margin Classification
支援向量機(Support vector machine)通常用在機器學習 (Machine learning)。是一種監督式學習 (Supervised Learning)的方法,主要用在統計分類
忘記截圖了,做了二次的,有點繞這裡,慢點想就好了。
正確選項是,It would be reasonable to try increasing C. It would also be reasonable to try decreasing σ2.
&n
本次文章內容: Coursera吳恩達機器學習課程,第七週程式設計作業。程式語言是Matlab。
本文只是從程式碼結構上做的小筆記,更復雜的推導不在這裡。演算法分兩部分進行理解,第一部分是根據code對演算法進行綜述,第二部分是程式碼。
本次作業分兩個part,第一個是using SVM,第
實驗指導書 下載密碼:a15g
本篇部落格主要講解,吳恩達機器學習第七週的程式設計作業,包含兩個實驗,一是線性svm和帶有高斯核函式的svm的基本使用;二是利用svm進行垃圾郵件分類。原始實驗使用Matlab實現,本篇部落格提供Python版本。
目錄
1.
課程視訊連結
第七週PPT 下載密碼:tmss
上週主要講解了如何設計機器學習系統和如何改進機器學習系統,包括一些模型選擇的方法,模型效能的評價指標,模型改進的方法等。本週主要講解支援向量機SVM的原理包括優化目標、大間隔以及核函式等SVM核心內容,以及SVM的使用。
&nbs
Classification and Representation
1. Classification
Linear Regression (線性迴歸)考慮的是連續值([0,1]之間的數)的問題,而Logistic Regression(邏輯迴歸)考
Cost Function and Backpropagation
Cost Function
假設有樣本m個。x(m)表示第m個樣本輸入,y(m)表示第m個樣本輸出,L表示網路的層數,sl表示在l層下,神經單元的總個數(不包括偏置bias units)
Kernel Trick
回顧一下SVM的對偶形式。使用對偶形式的目的是為了拜託對映到新的空間之後假設空間VC維
d
^
機器學習技法 Lecture1: Linear Support Vector Machine
Large-Margin Separating Hyperplane
Standard Large-Margin Problem
Support Ve
機器學習技法 Lecture2: Dual Support Vector Machine
Motivation of Dual SVM
Lagrange Dual SVM
Solving Dual SVM
Messages behind
本片文章內容:
Coursera吳恩達機器學習課程,第十週 Large Scale Machine Learning 部分的測驗,題目及答案截圖。
1.cost increase ,說明資料diverge。減小learning rate。
stochastic不需要每步都是減
本次文章內容: Coursera吳恩達機器學習課程,第八週程式設計作業。程式語言是Matlab。
本文只是從程式碼結構上做的小筆記,更復雜的推導不在這裡。演算法分兩部分進行理解,第一部分是根據code對演算法進行綜述,第二部分是程式碼。
本次作業分兩個part,第一個是K-Means Clu
本片文章內容:
Coursera吳恩達機器學習課程,第八週的測驗,題目及答案截圖。
本次文章內容: Coursera吳恩達機器學習課程,第六週程式設計作業。程式語言是Matlab。
學習演算法分兩部分進行理解,第一部分是根據code對演算法進行綜述,第二部分是程式碼。
0 Introduction
在這個練習中,應用regularized linea
說實話,這一次的測驗對我還是有一點難度的,為了刷到100分,刷了7次(哭)。
無奈,第2道和第4道題總是出錯,後來終於找到錯誤的地方,錯誤原因是思維定式,沒有動腦和審題正確。
這兩道題細節會在下面做出講解。
第二題分析:題意問,使用大量的資料,在哪兩種情況時
ex5.py
import scipy.optimize as op
import numpy as np
from scipy.io import loadmat
from ex5modules import *
#Part 1: Loading and visuali
本次文章內容: Coursera吳恩達機器學習課程,第五週程式設計作業。程式語言是Matlab。
學習演算法分兩部分進行理解,第一部分是根據code對演算法進行綜述,第二部分是程式碼。
0 Introduction
在這個練習中,將應用 backpropagation 滿足 優化 最終 clas 定義 mar 擴展 strong play 本講內容
1.Optional margin classifier(最優間隔分類器)
2.primal/dual optimization(原始優化問題和對偶優化問題)KKT conditions(KK
轉載https://www.cnblogs.com/LoganGo/p/8562575.html
一.邏輯迴歸問題(分類問題)
生活中存在著許多分類問題,如判斷郵件是否為垃圾郵件;判斷腫瘤是惡性還是良性等。機器學習中邏輯迴歸便是解決分類問題的一種方法。 二分類:通常表示為yϵ{0,1}
決策樹
相比於其他方法,決策樹是一種更為簡單的機器學習方法,它是對被觀測資料進行分類的一種相當直觀的方法,決策樹在經過訓練之後,看起來更像是以樹狀形式排列的一系列if-then語句。只要沿著樹的路徑一直向下,正確回答每一個問題,最終就會得到答案,沿著最終的葉節點向上回溯,就會得到一個有關最終分類 相關推薦
Coursera機器學習-第七週-Support Vector Machine
Coursera-吳恩達-機器學習-第七週-測驗-Support Vector Machines
Coursera-吳恩達-機器學習-第七週-程式設計作業: Support Vector Machines
機器學習 | 吳恩達機器學習第七週程式設計作業(Python版)
機器學習 | 吳恩達機器學習第七週學習筆記
Coursera機器學習-第三週-邏輯迴歸Logistic Regression
Coursera機器學習-第五週-Neural Network BackPropagation
機器學習技法 Lecture3: Kernel Support Vector Machine
機器學習技法 Lecture1: Linear Support Vector Machine
機器學習技法 Lecture2: Dual Support Vector Machine
Coursera-吳恩達-機器學習-第十週-測驗-Large Scale Machine Learning
Coursera-吳恩達-機器學習-第八週-程式設計作業: K-Means Clustering and PCA
Coursera-吳恩達-機器學習-第八週-測驗-Principal Component Analysis
Coursera-吳恩達-機器學習-第六週-程式設計作業: Regularized Linear Regression and Bias/Variance
Coursera-吳恩達-機器學習-第六週-測驗-Machine Learning System Design
Coursera NG 機器學習 第五週 正則化 bias Vs variance Python實現
Coursera-吳恩達-機器學習-第五週-程式設計作業: Neural Networks Learning
(筆記)斯坦福機器學習第七講--最優間隔分類器
吳恩達 機器學習 第三週
機器學習第七篇