
機器學習筆記——第一週
一、監督學習(Supervised Learning)
- 監督學習:給學習演算法一個數據集,這個資料集中包含“正確答案”。
- 迴歸(Regression):試著推出一系列連續值的屬性。舉例:房價問題。給定一系列房子的資料(房子大小以及它的實際售價),然後通過運用學習演算法,算出我們需要得到的正確答案。
- 分類(Classification):試著推測出離散值的輸出值。
舉例:用一個軟體來檢驗每一個使用者的賬戶,判斷它們是否被盜過(0代表未被盜過,1代表曾被盜過)。
二、無監督學習(Unsupervised Learning)
1.在無監督學習中我們已知的資料集沒有標籤或者它們具有相同的標籤。無監督學習將這些資料分成不同的簇。(聚類演算法)
2.應用於基因學的理解應用、社交網路的分析、新聞事件分類、天文資料分析等。
3.雞尾酒演算法(雞尾酒會問題):
在宴會房間中,有2個人同時說話,有2個麥克風在房間中,這2個麥克風放在不同的地方,離說話人的距離不同,每個麥克風記錄下不同的聲音。這樣,雖然是同樣的兩個人說話,但是聽起來像是兩份份錄音疊加在一起,產生現在的錄音。這個演算法會區分出2個說話人的各自的聲音。
程式碼: [W,s,v] = svd((repmat(sum(x.*x,1),size(x,1),1).*x)*x');
注:svd:奇異值分解。
三、模型表示(Model Representation)
1.監督學習演算法的工作方式:
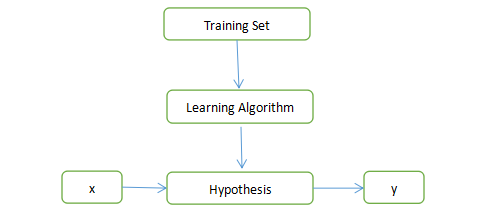
注:
Training Set:訓練集;
Learning Algorithm:學習演算法;
Hypothesis:假設函式;
x : 輸入值;
y : 輸出值。
2.單變數線性迴歸/線性迴歸:只含有一個特徵(輸入變數)。
四、代價函式(Cost Function)
- 代價函式也被稱為平方誤差函式或平方誤差代價函式。
- 代價函式適合解決迴歸問題。
- 函式:
 注:代表訓練樣本的數量。
注:代表訓練樣本的數量。
五、梯度下降(Gradient Descent)
- 梯度下降:批量梯度下降是一個用來求函式的最小值的演算法,引數更新的過程就是一個不斷迭代的過程,每次更新引數得到的函式都會使誤差損失越來越小,直到收斂到區域性極小值。
- 批量梯度下降演算法(BGD,batch gradient descent)
(1)用到了歷遍整個訓練集的樣本,在梯度下降的過程中,當計算偏導數時,計算總和。在每一個單獨的梯度下降中,最終計算m個訓練樣本的總和。
(2)公式表示:
注:
:=表示賦值;
α表示學習率;
(3)特點:
能達到全域性最優解,易於並行實現。
每一次迭代使用全部的樣本,當樣本數目很多時,訓練過程緩慢。
3.隨機梯度下降(SGD,stochastic gradient descent algorithm)
(1)隨機梯度下降每次更新引數都只使用一個樣本,進行多次更新。
(2)特點:
訓練速度快;
準確度下降,並不是最優解,不易於並行實現。
注:此學習筆記根據《吳恩達機器學習》課程記錄,並加入了自己的理解,如果有需要改正的地方,懇請指正!