【清華AI自強計劃-計算機視覺課程-第三講課程筆記1】
【清華AI自強計劃】-第三講課程筆記-1
資料歸一化中的“一”是什麼意思?
將不同變數的量綱都轉化為1,消除單位的影響。
明確課程定位:
垂直行業從業者&愛好者:
聽課目標:0->0.5 定性理解,專注落地
演算法科學家:
聽課目標:0->1 初步入門,加強演算法
提升方法:共享論文
AI工程師:
需要的程式碼工程能力更強,和真實業務環境相結合,如大量資料需要平行計算,有專案需要上線
聽課目標:0->1 初步入門,加強程式碼 能力
提升方法:工程問題,做作業的時候將每個函式都弄清楚,再做些上下游的工作,如資料是怎麼爬取的,將專案上線等。
第三講目標:訓練“識別手寫數字”的演算法
資料集介紹:
MNIST:
M 指是modified,資料集中原來高中生和公務員的手寫數字分別作為測試集和訓練集,modified版本將其混合,即將測試集和訓練集混合。
如何用邏輯迴歸解決這一問題?(用二分類解決十分類的問題,One vs All)
訓練10個分類器,每個分類器只打1個類別,想解決10分類的問題,訓練10個分類器即可。(A defense of one-vs-all classification)
計算機看圖是一個數字矩陣:

60000個圖片樣本,每個樣本對應2828的維度,形成上圖右邊的輸入矩陣。
訓練結果:樣本數量設定為55000時,最後輸出預測精度剛超過50%:泛化能力不行。
而當訓練樣本數為500時,預測精度反而達到90%。
為什麼樣本數量少,精度反而更高呢?
擬合出來的模型相當於在2828維度的空間中畫出決策邊界,樣本數非常少,以至於隨便畫條線都可以很好把樣本分隔開。
NN神經網路的歷史淵源:
生物學神經元衍生出數學模型:
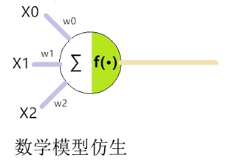
小於一個閾值不啟用,大於一個閾值將資料往後傳。
神經元多了–>感知機——>(有監督)BP神經網路
無監督:布林計算機
瞭解模型是什麼樣子的,引數在哪兒,怎麼輸入的,
觸及到核心知識時是沒有任何捷徑的,要仔細弄懂每個符號,每個運算過程。
只有輸出沒有輸入的圓圈代表偏置,作用是讓擬合曲線離開原點。
輸入層:神經元個數為特徵個數
輸出層:二分類輸出層只有一個,多分類情況下分類類別等於輸出層神經元個數。
隱藏層:神經元個數任意指定。
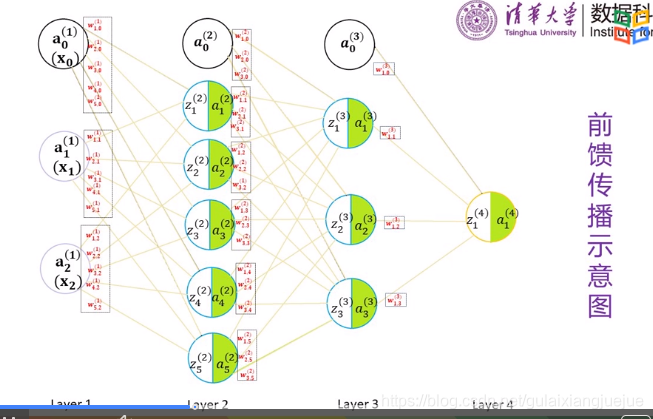
前饋傳播示意圖解析:
上圖中字母上角標括號內的數字代表層數
a,z,x下角標為在此層中的序號
w為模型引數,下角標有兩位,前面一位為指向神經元的序號, 後面一位是自己的序號。
全連線:前層每一個神經元和下一層所有神經元都要相連


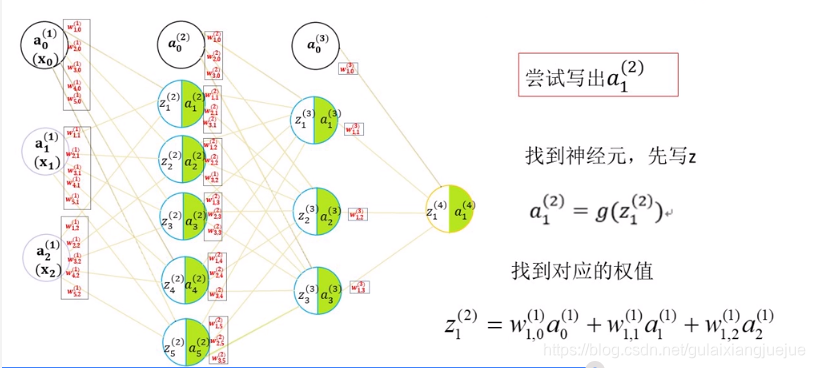
變數及引數解析:

訊號傳導下一層神經元先加和到z,再經過啟用函式輸出a。
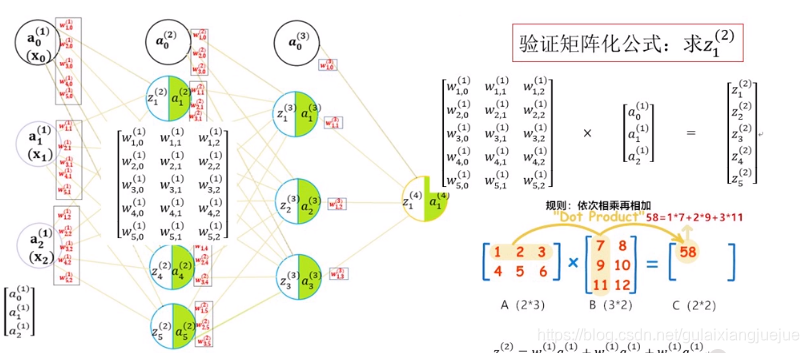
矩陣化表示,更加簡潔:
第二層的z等於第一層的權值乘以數值。