使用Tensorflow構造簡單的神經網路模型
阿新 • • 發佈:2018-12-16
Tensorflow
- TensorFlow™是一個基於資料流程式設計(dataflow programming)的符號數學系統,被廣泛應用於各類機器學習(machine learning)演算法的程式設計實現,其前身是谷歌的神經網路演算法庫DistBelief [1] 。
- Tensorflow擁有多層級結構,可部署於各類伺服器、PC終端和網頁並支援GPU和TPU高效能數值計算,被廣泛應用於谷歌內部的產品開發和各領域的科學研究 。
神經網路
在機器學習和相關領域,人工神經網路(人工神經網路)的計算模型靈感來自動物的中樞神經系統(尤其是腦),並且被用於估計或可以依賴於大量的輸入和一般的未知近似函式。人工神經網路通常呈現為相互連線的“神經元”,它可以從輸入的計算值,並且能夠機器學習以及模式識別由於它們的自適應性質的系統。
例如,用於手寫體識別的神經網路是由一組可能被輸入影象的畫素啟用的輸入神經元來限定。後進過加權,並通過一個函式(由網路的設計者確定的)轉化,這些神經元的致動被上到其他神經元然後被傳遞。重複此過程,直到最後,一輸出神經元被啟用。這決定了哪些字元被讀取。
像其他的從資料-神經網路認識到的機器學習系統方法已被用來解決各種各樣的很難用普通的以規則為基礎的程式設計解決的任務,包括計算機視覺和語音識別。
也許,人工神經網路的最大優勢是他們能夠被用作一個任意函式逼近的機制,那是從觀測到的資料“學習”。然而,使用起來也不是那麼簡單的,一個比較好理解的基本理論是必不可少的
下面我們用例項來說明:
神經網路的結構模型如下圖所示:
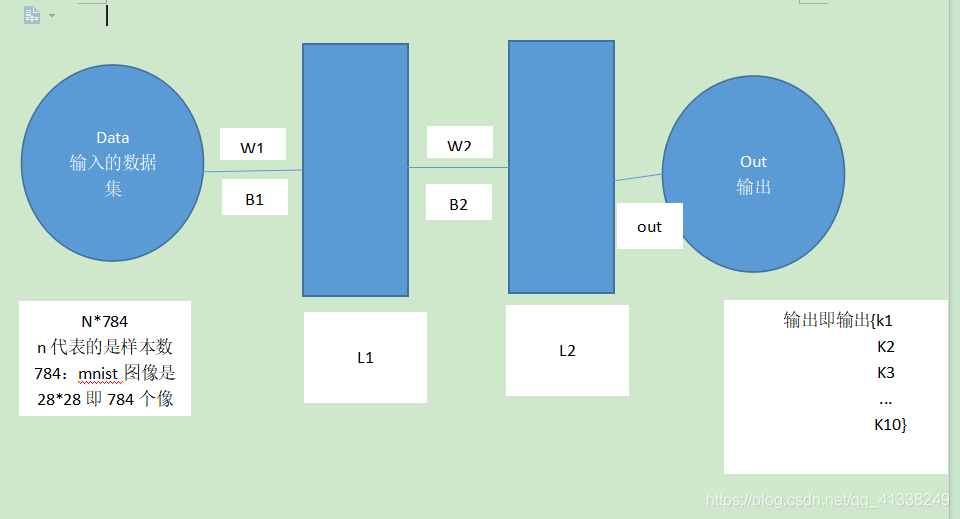
假如我們給L1層256個神經元,L2層128個神經元
第一步:對權重引數和偏置引數的初始化
那麼w1=784*256 b1=256
w2=256*128 b2=128
程式碼如下所示:
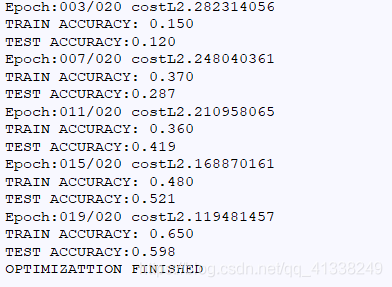
import numpy as np import tensorflow as tf import matplotlib.pyplot as plt from tensorflow.examples.tutorials.mnist import input_data mnist=input_data.read_data_sets("MNIST_data",one_hot=True) n_hidden_1=256 #第一層神經元 n_hidden_2=128 #第二層神經元 n_input=784 #輸入畫素點個數 n_classes=10 #最終得出分類的類別 10分類 #引數初始化 x=tf.placeholder("float",[None,n_input]) y=tf.placeholder("float",[None,n_classes]) stddev=0.1 weights={#初始化w1 w2 out 使用高斯初始化 'w1':tf.Variable(tf.random_normal([n_input,n_hidden_1],stddev=stddev)),#w1=784*256 'w2':tf.Variable(tf.random_normal([n_hidden_1,n_hidden_2],stddev=stddev)),#w2=256*128 'out':tf.Variable(tf.random_normal([n_hidden_2,n_classes],stddev=stddev)) #out=128*10 } biases={ 'b1':tf.Variable(tf.random_normal([n_hidden_1])), 'b2':tf.Variable(tf.random_normal([n_hidden_2])), 'out':tf.Variable(tf.random_normal([n_classes])) } print("NETWORK READY") #前向傳播 def multilayer_perceptron(_X,_weights,_biases): # _X表示data weights表示所有的w biases表示所有的b layer_1=tf.nn.sigmoid(tf.add(tf.matmul(_X,_weights['w1']),_biases['b1']))#計算layer1這層的輸出值,每層後面都要加sigmoid啟用函式 layer_2=tf.nn.sigmoid(tf.add(tf.matmul(layer_1,_weights['w2']),_biases['b2'])) #計算layer2這層的輸出值 return (tf.matmul(layer_2,_weights['out'])+_biases['out'])#輸出層不需要sigmoid函式啟用 #prediction pred=multilayer_perceptron(x,weights,biases) #定義損失函式 cost=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred,labels=y))#交叉熵函式第一個引數是網路的預測值,第二個引數是實際的label值 optm=tf.train.GradientDescentOptimizer(learning_rate=0.001).minimize(cost)#運用梯度下降的優化器求解cost corr=tf.equal(tf.argmax(pred,1),tf.argmax(y,1)) #模型的準確率 accr=tf.reduce_mean(tf.cast(corr,"float")) #轉化成float型別計算精度 init=tf.global_variables_initializer()#全域性變數初始化 print("FUNCTIONS READY") training_epochs=20 batch_size=100 display_step=4 sess=tf.Session()#定義計算圖的區域 sess.run(init) for epoch in range(training_epochs): avg_cost=0 total_batch=int(mnist.train.num_examples/batch_size) for i in range(total_batch): batch_xs,batch_ys=mnist.train.next_batch(batch_size) feeds={x:batch_xs,y:batch_ys} sess.run(optm,feed_dict=feeds) avg_cost+=sess.run(cost,feed_dict=feeds) avg_cost=avg_cost/total_batch if(epoch+1) % display_step ==0: print("Epoch:%03d/%03d costL%.9f" % (epoch,training_epochs,avg_cost)) feeds={x:batch_xs,y:batch_ys} train_acc=sess.run(accr,feed_dict=feeds) print("TRAIN ACCURACY: %.3f" %(train_acc)) feeds={x:mnist.test.images,y:mnist.test.labels} test_accc=sess.run(accr,feed_dict=feeds) print("TEST ACCURACY:%.3f" %(test_accc)) print("OPTIMIZATTION FINISHED")
執行結果如下: