
深度學習布料交換:在Keras中實現條件類比GAN
給定三個輸入影象:人穿著布A,獨立布A和獨立布B,條件類比GAN(CAGAN)生成穿著布B的人類影象。參見下圖。
在我的實驗中,CAGAN能夠交換不同類別的衣服,例如長/短袖T恤(原始紙張中未顯示)。換句話說,CAGAN不僅改變了衣服的顏色,而且還必須產生從長袖到短袖領域的人體部位。
預習:

CAGAN概述。

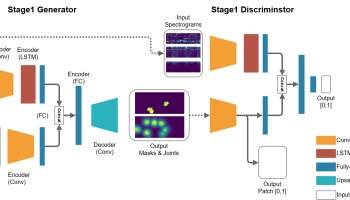
發電機G和鑑別器D的架構

結果比較:cycleGAN(左)和CAGAN(右)。
資料集:
影象是從zalora.com.tw抓取的。我們收集了大約2000個人/物對作為訓練資料。
(*由於版權問題,此帖子中的某些圖片會被插圖替換或裁剪。)
組態
- 優化者:亞當
- 學習率:2e-4
- 批量大小:16(CAGAN)或8(CAGAN + StackGAN-v2)
- 資料增強:隨機裁剪和翻轉
GitHub回購。
可以在此處找到CAGAN的keras實現。
關於實施的說明:
- 在CAGAN論文中,關於實現細節的描述寫道:“此外,我們總是使用任何中間層的最後6個通道(在G和D中)來儲存輸入的下采樣副本
”。我不完全理解這意味著什麼,所以我所做的就是來連線
和
每一箇中間層。然而,當連線
I. CycleGAN是我們的第一次嘗試
為什麼選擇CycleGAN?這是影象到影象生成的首選解決方案(個人)。已經在GitHub上實現了keras。
它有用嗎?是的,但缺乏多樣性和現實。
迴圈實現的CycleGAN是從這裡借來的。
結果: 給定單獨的物品影象作為輸入,上圖顯示了在訓練~10k次迭代後生成的人體影象。CycleGAN無法生成人臉,身體形狀遠非真實。底行還有模式摺疊(類似的人體姿勢)。
給定單獨的物品影象作為輸入,上圖顯示了在訓練~10k次迭代後生成的人體影象。CycleGAN無法生成人臉,身體形狀遠非真實。底行還有模式摺疊(類似的人體姿勢)。
II。重新實現CAGAN
為何選擇CAGAN?想要生成具有不同姿勢的逼真人體影象。充分利用輸入人類影象。
它有用嗎?是。
概述:
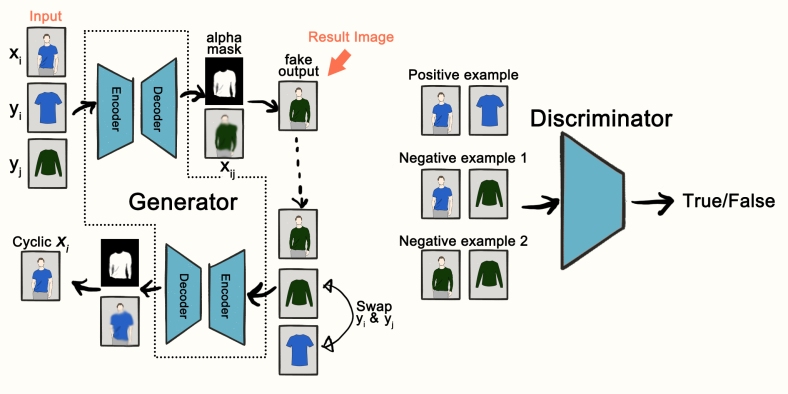
給出三個輸入影象:
 ,獨立布B,條件類比GAN(CAGAN)生成將
,獨立布B,條件類比GAN(CAGAN)生成將 其布料從A交換到B 的人類影象。應用鑑別器以通過在三個示例對上對真/假進行分類來幫助改善生成的結果質量。
其布料從A交換到B 的人類影象。應用鑑別器以通過在三個示例對上對真/假進行分類來幫助改善生成的結果質量。
建築:
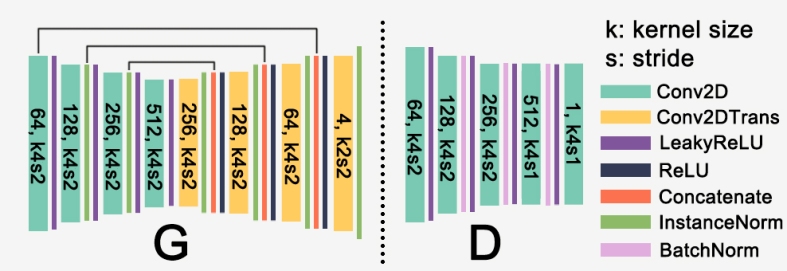
發電機G和鑑別器D的結構。
生成器是典型的UNET,它將早期層功能連線到後面的層。發生器的輸出是包含四通道張量的![\ left [\ alpha,\ hat {x} {ij} ^ R,\ hat {x} {ij} ^ G,\ hat {x} _ {ij} ^ B \ right]](https://s0.wp.com/latex.php?latex=%5Cleft+%5B%5Calpha+%2C+%5Chat%7Bx%7D%7Bij%7D%5ER%2C+%5Chat%7Bx%7D%7Bij%7D%5EG%2C+%5Chat%7Bx%7D_%7Bij%7D%5EB+%5Cright+%5D+&bg=ffffff&fg=555555&s=0)
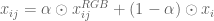
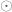
鑑別器由幾層Conv2D組成,輸出為8x8x1 sigmoid輸出(輸入大小128x96x3),即所謂的PatchGAN方法。
訓練損失功能:
在CAGAN培訓中,有3個應用損失:第一,對抗性損失
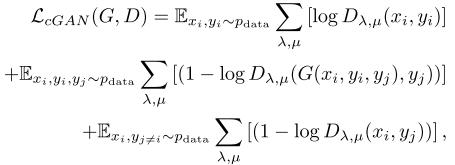 其中
其中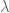


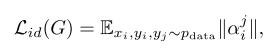 其中||
其中|| 
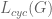
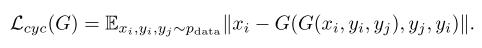
採摘櫻桃的結果:
所以有什麼問題?
當訓練超過3000次更新時,生成的影象中存在重複的偽影,有時人臉會變形,如下所示:
這些偽影也可以在原始CAGAN論文的圖6(c)和(d)中找到。
我認為這是由小編碼器輸出大小(輸入大小的1 / 16x)引起的,因此在超解析度相關任務中使用的架構和方法可能會有所幫助,這將導致下一節。
III。CAGAN + StackGAN-v2
為什麼將CAGAN與StackGan-v2結合使用?想要生成高質量的紋理/圖形,並穩定培訓。
它有用嗎?有點,它更經常地產生成功的結果。而且它的訓練更穩定。
訓練期間使用的任何技巧?
1.將高斯噪聲新增到鑑別器輸入。
2. 在鑑別器輸入上使用混合技術。
3.將Conv2D核心大小更改為(4,3)。
4.為生成器損失新增標識丟失。見下面的[實驗註釋] 2。
5.尺寸64×48迴圈輸出合併為
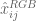
6.連線![[x_i,y_j]](https://s0.wp.com/latex.php?latex=%5Bx_i%2C+y_j%5D&bg=ffffff&fg=555555&s=0)
![[x_i,y_i]](https://s0.wp.com/latex.php?latex=%5Bx_i%2C+y_i%5D&bg=ffffff&fg=555555&s=0)
架構:上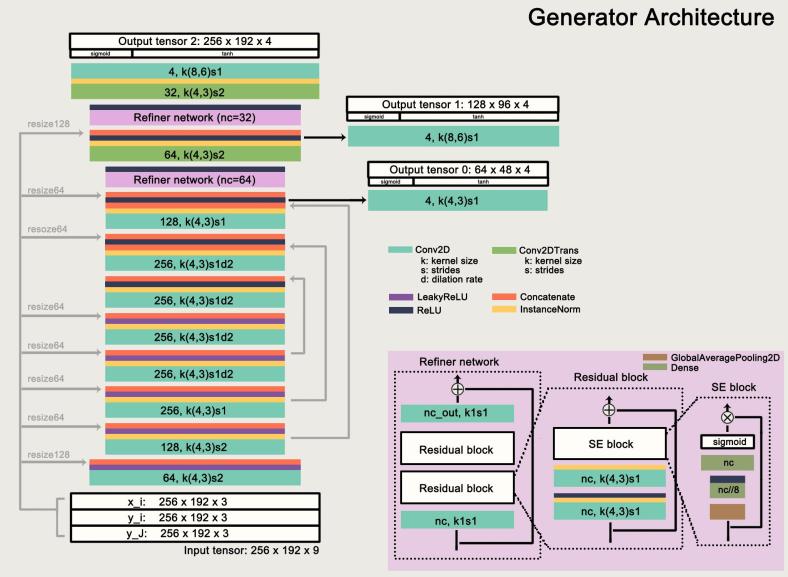 圖詳細顯示了模型架構。該模型將三個影象作為輸入,並在其末端生成三個不同大小的人類影象(帶有alpha蒙版)。我們對CAGAN架構進行了一些修改:首先,受到本文處理影象完成的啟發,我們用擴充套件的Conc2D層替換了部分stride 2 Conv2D層,使得特徵對映解析度減半。這可以防止輸出影象丟失細節。其次,在解碼器(-ish)部分中引入了精煉網路。精煉網路由兩堆殘餘塊組成,它學習新增細節以及提高輸出影象的真實感。此外,我們應用擠壓和激勵模組 在剩餘的塊之上(希望學會)增加對資訊功能的敏感性。
圖詳細顯示了模型架構。該模型將三個影象作為輸入,並在其末端生成三個不同大小的人類影象(帶有alpha蒙版)。我們對CAGAN架構進行了一些修改:首先,受到本文處理影象完成的啟發,我們用擴充套件的Conc2D層替換了部分stride 2 Conv2D層,使得特徵對映解析度減半。這可以防止輸出影象丟失細節。其次,在解碼器(-ish)部分中引入了精煉網路。精煉網路由兩堆殘餘塊組成,它學習新增細節以及提高輸出影象的真實感。此外,我們應用擠壓和激勵模組 在剩餘的塊之上(希望學會)增加對資訊功能的敏感性。
我們模型的另一個主幹是StackGAN-v2(StackGAN ++)。StackGan-v2由樹狀結構中的多個生成器和鑑別器組成。在我們的模型中,我們使用不同比例的三級發生器:256 x 192,128 x 96和64 x 48,而最深的發生器生成最終輸出影象。StackGAN架構有助於穩定訓練並改善輸出顏色的真實感(例如,膚色)。
請注意,我們的前饋輸入影象
(鑑別器具有與CAGAN相同的結構。故意保持簡單。)
訓練損失函式:
除了在CAGAN中使用的損失函式之外,我們還引入了兩個損失函式:身份丟失


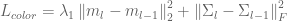
![x_ {ident} = G([x_i,y_i,y_i]),](https://s0.wp.com/latex.php?latex=x_%7Bident%7D%3DG%28%5Bx_i%2C+y_i%2C+y_i%5D%29%2C&bg=ffffff&fg=555555&s=0)
其中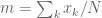
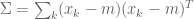
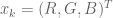
身份損失鼓勵模型專注於
採摘櫻桃的結果:
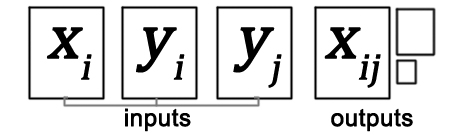
輸入影象顯示為前三個影象。跟隨右側相應生成的人體影象。(輸入影象被插圖替換)
內部類
長袖到短袖


上圖顯示了每個階段輸出影象的細化:上圖顯示了膚色的細化,下圖顯示了圖形顏色的細化。
影象


我們的模型能夠生成比原始CAGAN更清晰的目標文章圖形。
其他

我們可以從結果影象中看出,沒有生成重複的偽像。(雖然沒有顯示,但在我們的模型中,人臉上的文物也減少了。)
好的,現在怎麼樣?
總的來說,我對結果很滿意,因為我們的模型只訓練了大約2000個影象對(<1 / 7x的CAGAN)。但它在提高模型複雜度,換句話說,更長的訓練時間的權衡中產生了更高質量的影象。更重要的是,生成的影象仍然遠非完美。例如,我們的模型無法瞭解穿布的變形(單獨布料)。大多數交換結果看起來就像是通過一些改進將目標衣服複製貼上到人體影象上。因此,圖形的位置通常是偏離位置的。我們嘗試了空間變換器層(使用薄平面樣條變換),但遺憾的是未能獲得良好的結果。無論如何,我們可以想到很多叛逃:生硬的邊緣,低成功率,不知道頸線等。
此外,我們沒有進行任何定量評估。我們只通過觀察其視覺質量來判斷效能。在這裡,我想引用Generative Adversarial Networks:An Overview(作為我缺乏GAN知識的藉口):“如何衡量由生成模型合成的樣本的優良性?我們應該使用可能性估計嗎?使用一種方法訓練的GAN能否與另一種方法進行比較(模型比較)?這些是開放式問題,不僅與GAN有關,而且與概率模型有關。
我從實施CAGAN中學到了什麼:
- 理解某些架構背後的概念比架構本身更重要。
- 在調整超引數(如核心大小和損失函式的加權因子)上花費太多時間是不明智的,因為它總是導致微不足道的改進。
- 直覺從未在神經網路上工作過。我認為會改善結果的是99%的失敗。
- 為每個圖層指定一個正確的名稱,以便我可以按Ctrl + F在model.summary()中搜索它們。
- 進行單元測試,檢查迭代後是否更新了權重。
2017年11月25日更新:來自UMD(拉里戴維斯實驗室)的
一篇名為“VITON:基於影象的虛擬試穿網路 ” 的新論文 在布料交換方面給出了令人印象深刻的結果,基本上讓這個帖子毫無價值LOL。我相信本文中的TPS變換部分可以被空間變換器網路所取代。
2018年2月18日更新:
基於服裝區域的基於生成對抗網路的虛擬嘗試:基於CAGAN的ICLR研討會論文,其中引入了人類解析網路來分割服裝區域。即,alpha掩碼不再由生成器生成,而是由預先訓練的網路生成。
更新
時間:2018年11月20日:SwapNet:單一檢視中的服裝轉移影象:一篇ECCV2018論文,其中作者提出了一個框架,“將服裝轉移到具有任意身體姿勢,形狀和衣服的人的影象上”。網路利用姿勢和布料分割作為先驗資訊。它還使用變形(如在VITON中)來改善生成的衣服的紋理細節。
[實驗註釋]
1.替換Con2DTranspose與最近鄰上取樣沒有給出更好的結果影象,因為迴圈
2.新增身份丟失減少了棋盤格工件,並使網路從模式崩潰中穩定下來。身份損失是L1損失,定義為:
![idt = G([x_i,y_i,y_i])](https://s0.wp.com/latex.php?latex=idt%3DG%28%5Bx_i%2C+y_i%2C+y_i%5D%29&bg=ffffff&fg=555555&s=0)
3。 感知損失(我的實驗中的MobileNet)也沒有幫助。也許是因為迴圈損失對結果影象沒有太大影響。迴圈損耗加權因子在迴圈GAN(tjwei的keras實現)中
4. StackGAN-v2架構可能有所幫助。仍在實驗中(調整超引數)。到目前為止只與原來的CAGAN得到了類似的結果。完成。
5.在L a b色彩空間中對影象進行訓練的模型在白色物品上表現不佳。
6.使用最小平方損失時沒有收斂。
7.將輸入[ 
8.使用擴張卷積可以改善紋理(例如,T恤上的圖形)質量。
9。 新增輔助本地上下文鑑別器(受本文啟發)沒有找到一個好的方法將其插入CAGANs。
10.在發生器中使用更多膨脹的Conv2D和更少的stride2 Conv2D層(9的相同紙張)。
11.在StackGAN-v2架構中使用迴圈丟失是一個類似於XGAN中語義一致性丟失的概念(最近發表的來自Google腦的論文):它們都使用中間層的特徵距離作為損失以鼓勵內容一致性。
12.如果WGAN-GP能帶來更好的結果,我一直想知道。通過略讀之後本文是提供有關超解析度任務GAN和WGAN(-GP)之間的比較,我決定推遲實驗WGAN。
廣告
廣告
舉報此廣告
舉報此廣告
有關
在“keras”中
在“未分類”中

在Floybhub上使用Mask-RCNN和SSD進行車輛檢測:Udacity自動駕駛汽車納米度
在“floydhub”中
分類:keras
郵政導航
←用Swish,ReLU和SELU進行實驗(在neptune.ml上)
2個想法“ 布與深學習交換:實施Keras有條件類比GAN ”
-
Xintong Han 說:
嗨,我是Xintong Han。在使用VITON紙張時,我嘗試過空間變壓器網路(至少兩週)。即使將基礎事實TPS引數作為監督的一部分,STN也很難收斂,這使得很難超越形狀上下文匹配。如果你在這個場景中讓STN工作取得任何進展,我很高興聽到這個。
喜歡
-
少安路 說:
嗨,Xintong。我在CAGAN上嘗試了STN,但也沒有找到成功的結果。
關於以監督方式訓練STN,你的意思是給出兩個二元掩模作為輸入:布掩碼M和蒙面目標服裝C(類似於VITON論文中引用的WarpNet),STN不能很好地學習TPS引數?
-